 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstanceRSR: Real-World Super-Resolution via Instance-Aware Representation Alignment
Mar 25, 2026Existing real-world super-resolution (RSR) methods based on generative priors have achieved remarkable progress in producing high-quality and globally consistent reconstructions. However, they often struggle to recover fine-grained details of diverse object instances in complex real-world scenes. This limitation primarily arises because commonly adopted denoising losses (e.g., MSE) inherently favor global consistency while neglecting instance-level perception and restoration. To address this issue, we propose InstanceRSR, a novel RSR framework that jointly models semantic information and introduces instance-level feature alignment. Specifically, we employ low-resolution (LR) images as global consistency guidance while jointly modeling image data and semantic segmentation maps to enforce semantic relevance during sampling. Moreover, we design an instance representation learning module to align the diffusion latent space with the instance latent space, enabling instance-aware feature alignment, and further incorporate a scale alignment mechanism to enhance fine-grained perception and detail recovery. Benefiting from these designs, our approach not only generates photorealistic details but also preserves semantic consistency at the instance level. Extensive experiments on multiple real-world benchmarks demonstrate that InstanceRSR significantly outperforms existing methods in both quantitative metrics and visual quality, achieving new state-of-the-art (SOTA) performance.
FastTalker: Jointly Generating Speech and Conversational Gestures from Text
Sep 24, 2024



Generating 3D human gestures and speech from a text script is critical for creating realistic talking avatars. One solution is to leverage separate pipelines for text-to-speech (TTS) and speech-to-gesture (STG), but this approach suffers from poor alignment of speech and gestures and slow inference times. In this paper, we introduce FastTalker, an efficient and effective framework that simultaneously generates high-quality speech audio and 3D human gestures at high inference speeds. Our key insight is reusing the intermediate features from speech synthesis for gesture generation, as these features contain more precise rhythmic information than features re-extracted from generated speech. Specifically, 1) we propose an end-to-end framework that concurrently generates speech waveforms and full-body gestures, using intermediate speech features such as pitch, onset, energy, and duration directly for gesture decoding; 2) we redesign the causal network architecture to eliminate dependencies on future inputs for real applications; 3) we employ Reinforcement Learning-based Neural Architecture Search (NAS) to enhance both performance and inference speed by optimizing our network architecture. Experimental results on the BEAT2 dataset demonstrate that FastTalker achieves state-of-the-art performance in both speech synthesis and gesture generation, processing speech and gestures in 0.17 seconds per second on an NVIDIA 3090.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024



Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
Impact of Design Decisions in Scanpath Modeling
May 14, 2024



Modeling visual saliency in graphical user interfaces (GUIs) allows to understand how people perceive GUI designs and what elements attract their attention. One aspect that is often overlooked is the fact that computational models depend on a series of design parameters that are not straightforward to decide. We systematically analyze how different design parameters affect scanpath evaluation metrics using a state-of-the-art computational model (DeepGaze++). We particularly focus on three design parameters: input image size, inhibition-of-return decay, and masking radius. We show that even small variations of these design parameters have a noticeable impact on standard evaluation metrics such as DTW or Eyenalysis. These effects also occur in other scanpath models, such as UMSS and ScanGAN, and in other datasets such as MASSVIS. Taken together, our results put forward the impact of design decisions for predicting users' viewing behavior on GUIs.
EyeFormer: Predicting Personalized Scanpaths with Transformer-Guided Reinforcement Learning
Apr 15, 2024



From a visual perception perspective, modern graphical user interfaces (GUIs) comprise a complex graphics-rich two-dimensional visuospatial arrangement of text, images, and interactive objects such as buttons and menus. While existing models can accurately predict regions and objects that are likely to attract attention ``on average'', so far there is no scanpath model capable of predicting scanpaths for an individual. To close this gap, we introduce EyeFormer, which leverages a Transformer architecture as a policy network to guide a deep reinforcement learning algorithm that controls gaze locations. Our model has the unique capability of producing personalized predictions when given a few user scanpath samples. It can predict full scanpath information, including fixation positions and duration, across individuals and various stimulus types. Additionally, we demonstrate applications in GUI layout optimization driven by our model. Our software and models will be publicly available.
PiTL: Cross-modal Retrieval with Weakly-supervised Vision-language Pre-training via Prompting
Jul 14, 2023



Vision-language (VL) Pre-training (VLP) has shown to well generalize VL models over a wide range of VL downstream tasks, especially for cross-modal retrieval. However, it hinges on a huge amount of image-text pairs, which requires tedious and costly curation. On the contrary, weakly-supervised VLP (W-VLP) explores means with object tags generated by a pre-trained object detector (OD) from images. Yet, they still require paired information, i.e. images and object-level annotations, as supervision to train an OD. To further reduce the amount of supervision, we propose Prompts-in-The-Loop (PiTL) that prompts knowledge from large language models (LLMs) to describe images. Concretely, given a category label of an image, e.g. refinery, the knowledge, e.g. a refinery could be seen with large storage tanks, pipework, and ..., extracted by LLMs is used as the language counterpart. The knowledge supplements, e.g. the common relations among entities most likely appearing in a scene. We create IN14K, a new VL dataset of 9M images and 1M descriptions of 14K categories from ImageNet21K with PiTL. Empirically, the VL models pre-trained with PiTL-generated pairs are strongly favored over other W-VLP works on image-to-text (I2T) and text-to-image (T2I) retrieval tasks, with less supervision. The results reveal the effectiveness of PiTL-generated pairs for VLP.
CLIP4IDC: CLIP for Image Difference Captioning
Jun 01, 2022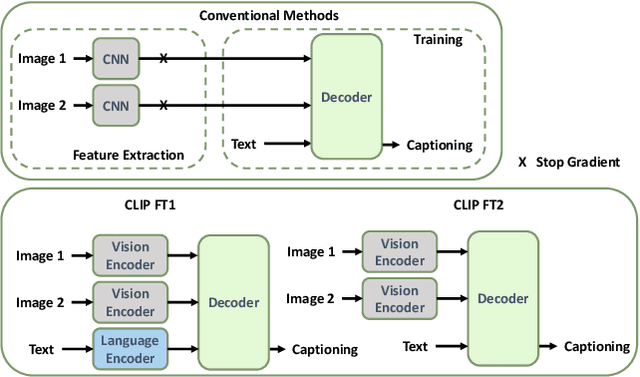
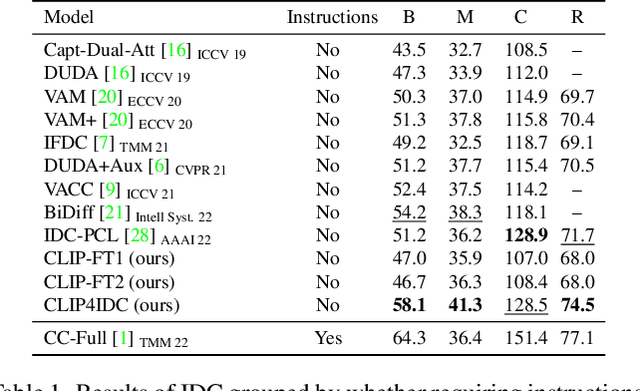
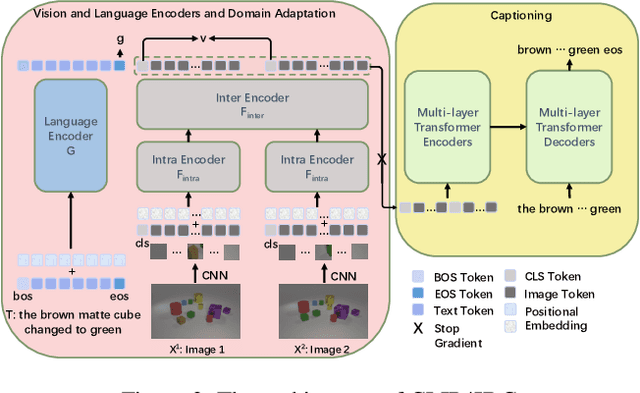
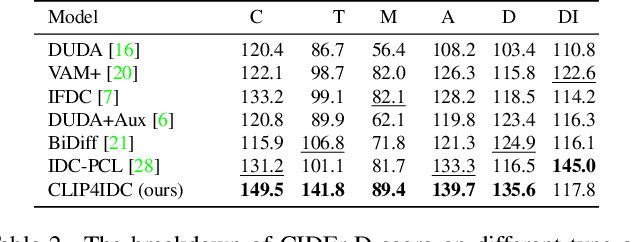
Image Difference Captioning (IDC) aims at generating sentences to describe the differences between two similar-looking images. The conventional approaches learn captioning models on the offline-extracted visual features and the learning can not be propagated back to the fixed feature extractors pre-trained on image classification datasets. Accordingly, potential improvements can be made by fine-tuning the visual features for: 1) narrowing the gap when generalizing the visual extractor trained on image classification to IDC, and 2) relating the extracted visual features to the descriptions of the corresponding changes. We thus propose CLIP4IDC to transfer a CLIP model for the IDC task to attain these improvements. Different from directly fine-tuning CLIP to generate sentences, a task-specific domain adaptation is used to improve the extracted features. Specifically, the target is to train CLIP on raw pixels to relate the image pairs to the described changes. Afterwards, a vanilla Transformer is trained for IDC on the features extracted by the vision encoder of CLIP. Experiments on three IDC benchmark datasets, CLEVR-Change, Spot-the-Diff and Image-Editing-Request, demonstrate the effectiveness of CLIP4IDC. Our code and models will be released at https://github.com/sushizixin/CLIP4IDC.