 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCsl
Papers and Code
MaDiS: Taming Masked Diffusion Language Models for Sign Language Generation
Jan 27, 2026Sign language generation (SLG) aims to translate written texts into expressive sign motions, bridging communication barriers for the Deaf and Hard-of-Hearing communities. Recent studies formulate SLG within the language modeling framework using autoregressive language models, which suffer from unidirectional context modeling and slow token-by-token inference. To address these limitations, we present MaDiS, a masked-diffusion-based language model for SLG that captures bidirectional dependencies and supports efficient parallel multi-token generation. We further introduce a tri-level cross-modal pretraining scheme that jointly learns from token-, latent-, and 3D physical-space objectives, leading to richer and more grounded sign representations. To accelerate model convergence in the fine-tuning stage, we design a novel unmasking strategy with temporal checkpoints, reducing the combinatorial complexity of unmasking orders by over $10^{41}$ times. In addition, a mixture-of-parts embedding layer is developed to effectively fuse information stored in different part-wise sign tokens through learnable gates and well-optimized codebooks. Extensive experiments on CSL-Daily, Phoenix-2014T, and How2Sign demonstrate that MaDiS achieves superior performance across multiple metrics, including DTW error and two newly introduced metrics, SiBLEU and SiCLIP, while reducing inference latency by nearly 30%. Code and models will be released on our project page.
EASLT: Emotion-Aware Sign Language Translation
Jan 07, 2026Sign Language Translation (SLT) is a complex cross-modal task requiring the integration of Manual Signals (MS) and Non-Manual Signals (NMS). While recent gloss-free SLT methods have made strides in translating manual gestures, they frequently overlook the semantic criticality of facial expressions, resulting in ambiguity when distinct concepts share identical manual articulations. To address this, we present **EASLT** (**E**motion-**A**ware **S**ign **L**anguage **T**ranslation), a framework that treats facial affect not as auxiliary information, but as a robust semantic anchor. Unlike methods that relegate facial expressions to a secondary role, EASLT incorporates a dedicated emotional encoder to capture continuous affective dynamics. These representations are integrated via a novel *Emotion-Aware Fusion* (EAF) module, which adaptively recalibrates spatio-temporal sign features based on affective context to resolve semantic ambiguities. Extensive evaluations on the PHOENIX14T and CSL-Daily benchmarks demonstrate that EASLT establishes advanced performance among gloss-free methods, achieving BLEU-4 scores of 26.15 and 22.80, and BLEURT scores of 61.0 and 57.8, respectively. Ablation studies confirm that explicitly modeling emotion effectively decouples affective semantics from manual dynamics, significantly enhancing translation fidelity. Code is available at https://github.com/TuGuobin/EASLT.
USTM: Unified Spatial and Temporal Modeling for Continuous Sign Language Recognition
Dec 15, 2025Continuous sign language recognition (CSLR) requires precise spatio-temporal modeling to accurately recognize sequences of gestures in videos. Existing frameworks often rely on CNN-based spatial backbones combined with temporal convolution or recurrent modules. These techniques fail in capturing fine-grained hand and facial cues and modeling long-range temporal dependencies. To address these limitations, we propose the Unified Spatio-Temporal Modeling (USTM) framework, a spatio-temporal encoder that effectively models complex patterns using a combination of a Swin Transformer backbone enhanced with lightweight temporal adapter with positional embeddings (TAPE). Our framework captures fine-grained spatial features alongside short and long-term temporal context, enabling robust sign language recognition from RGB videos without relying on multi-stream inputs or auxiliary modalities. Extensive experiments on benchmarked datasets including PHOENIX14, PHOENIX14T, and CSL-Daily demonstrate that USTM achieves state-of-the-art performance against RGB-based as well as multi-modal CSLR approaches, while maintaining competitive performance against multi-stream approaches. These results highlight the strength and efficacy of the USTM framework for CSLR. The code is available at https://github.com/gufranSabri/USTM
RVLF: A Reinforcing Vision-Language Framework for Gloss-Free Sign Language Translation
Dec 08, 2025Gloss-free sign language translation (SLT) is hindered by two key challenges: **inadequate sign representation** that fails to capture nuanced visual cues, and **sentence-level semantic misalignment** in current LLM-based methods, which limits translation quality. To address these issues, we propose a three-stage **r**einforcing **v**ision-**l**anguage **f**ramework (**RVLF**). We build a large vision-language model (LVLM) specifically designed for sign language, and then combine it with reinforcement learning (RL) to adaptively enhance translation performance. First, for a sufficient representation of sign language, RVLF introduces an effective semantic representation learning mechanism that fuses skeleton-based motion cues with semantically rich visual features extracted via DINOv2, followed by instruction tuning to obtain a strong SLT-SFT baseline. Then, to improve sentence-level semantic misalignment, we introduce a GRPO-based optimization strategy that fine-tunes the SLT-SFT model with a reward function combining translation fidelity (BLEU) and sentence completeness (ROUGE), yielding the optimized model termed SLT-GRPO. Our conceptually simple framework yields substantial gains under the gloss-free SLT setting without pre-training on any external large-scale sign language datasets, improving BLEU-4 scores by +5.1, +1.11, +1.4, and +1.61 on the CSL-Daily, PHOENIX-2014T, How2Sign, and OpenASL datasets, respectively. To the best of our knowledge, this is the first work to incorporate GRPO into SLT. Extensive experiments and ablation studies validate the effectiveness of GRPO-based optimization in enhancing both translation quality and semantic consistency.
TYrPPG: Uncomplicated and Enhanced Learning Capability rPPG for Remote Heart Rate Estimation
Nov 08, 2025



Remote photoplethysmography (rPPG) can remotely extract physiological signals from RGB video, which has many advantages in detecting heart rate, such as low cost and no invasion to patients. The existing rPPG model is usually based on the transformer module, which has low computation efficiency. Recently, the Mamba model has garnered increasing attention due to its efficient performance in natural language processing tasks, demonstrating potential as a substitute for transformer-based algorithms. However, the Mambaout model and its variants prove that the SSM module, which is the core component of the Mamba model, is unnecessary for the vision task. Therefore, we hope to prove the feasibility of using the Mambaout-based module to remotely learn the heart rate. Specifically, we propose a novel rPPG algorithm called uncomplicated and enhanced learning capability rPPG (TYrPPG). This paper introduces an innovative gated video understanding block (GVB) designed for efficient analysis of RGB videos. Based on the Mambaout structure, this block integrates 2D-CNN and 3D-CNN to enhance video understanding for analysis. In addition, we propose a comprehensive supervised loss function (CSL) to improve the model's learning capability, along with its weakly supervised variants. The experiments show that our TYrPPG can achieve state-of-the-art performance in commonly used datasets, indicating its prospects and superiority in remote heart rate estimation. The source code is available at https://github.com/Taixi-CHEN/TYrPPG.
Artificial Intelligence Virtual Cells: From Measurements to Decisions across Modality, Scale, Dynamics, and Evaluation
Oct 14, 2025Artificial Intelligence Virtual Cells (AIVCs) aim to learn executable, decision-relevant models of cell state from multimodal, multiscale measurements. Recent studies have introduced single-cell and spatial foundation models, improved cross-modality alignment, scaled perturbation atlases, and explored pathway-level readouts. Nevertheless, although held-out validation is standard practice, evaluations remain predominantly within single datasets and settings; evidence indicates that transport across laboratories and platforms is often limited, that some data splits are vulnerable to leakage and coverage bias, and that dose, time and combination effects are not yet systematically handled. Cross-scale coupling also remains constrained, as anchors linking molecular, cellular and tissue levels are sparse, and alignment to scientific or clinical readouts varies across studies. We propose a model-agnostic Cell-State Latent (CSL) perspective that organizes learning via an operator grammar: measurement, lift/project for cross-scale coupling, and intervention for dosing and scheduling. This view motivates a decision-aligned evaluation blueprint across modality, scale, context and intervention, and emphasizes function-space readouts such as pathway activity, spatial neighborhoods and clinically relevant endpoints. We recommend operator-aware data design, leakage-resistant partitions, and transparent calibration and reporting to enable reproducible, like-for-like comparisons.
SSL-SSAW: Self-Supervised Learning with Sigmoid Self-Attention Weighting for Question-Based Sign Language Translation
Sep 17, 2025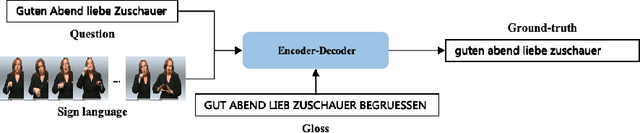
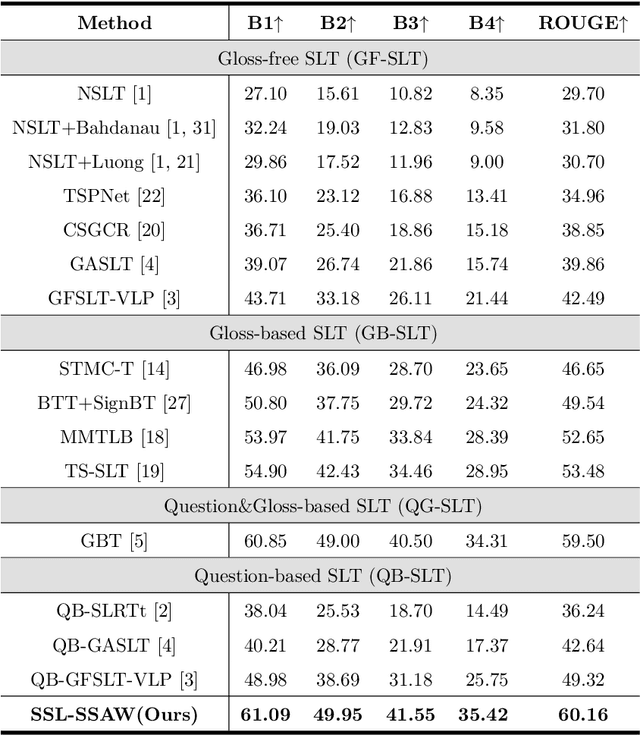
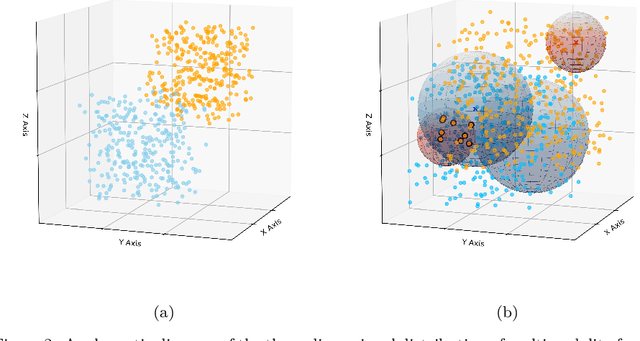
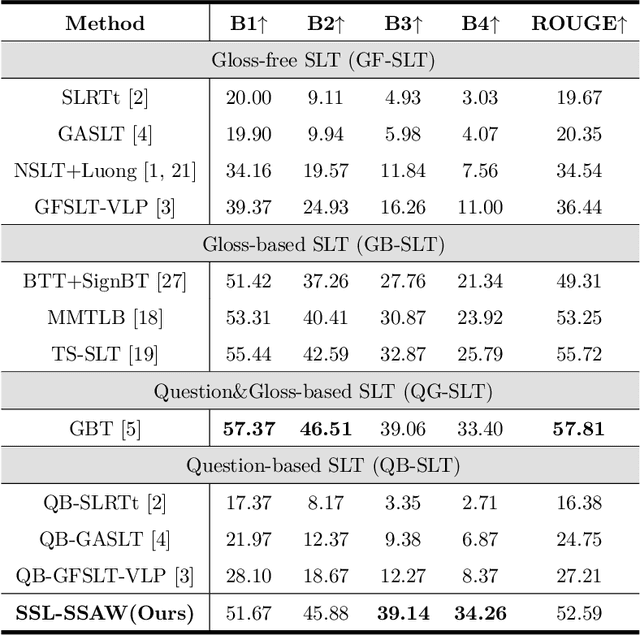
Sign Language Translation (SLT) bridges the communication gap between deaf people and hearing people, where dialogue provides crucial contextual cues to aid in translation. Building on this foundational concept, this paper proposes Question-based Sign Language Translation (QB-SLT), a novel task that explores the efficient integration of dialogue. Unlike gloss (sign language transcription) annotations, dialogue naturally occurs in communication and is easier to annotate. The key challenge lies in aligning multimodality features while leveraging the context of the question to improve translation. To address this issue, we propose a cross-modality Self-supervised Learning with Sigmoid Self-attention Weighting (SSL-SSAW) fusion method for sign language translation. Specifically, we employ contrastive learning to align multimodality features in QB-SLT, then introduce a Sigmoid Self-attention Weighting (SSAW) module for adaptive feature extraction from question and sign language sequences. Additionally, we leverage available question text through self-supervised learning to enhance representation and translation capabilities. We evaluated our approach on newly constructed CSL-Daily-QA and PHOENIX-2014T-QA datasets, where SSL-SSAW achieved SOTA performance. Notably, easily accessible question assistance can achieve or even surpass the performance of gloss assistance. Furthermore, visualization results demonstrate the effectiveness of incorporating dialogue in improving translation quality.
SiLVERScore: Semantically-Aware Embeddings for Sign Language Generation Evaluation
Sep 04, 2025Evaluating sign language generation is often done through back-translation, where generated signs are first recognized back to text and then compared to a reference using text-based metrics. However, this two-step evaluation pipeline introduces ambiguity: it not only fails to capture the multimodal nature of sign language-such as facial expressions, spatial grammar, and prosody-but also makes it hard to pinpoint whether evaluation errors come from sign generation model or the translation system used to assess it. In this work, we propose SiLVERScore, a novel semantically-aware embedding-based evaluation metric that assesses sign language generation in a joint embedding space. Our contributions include: (1) identifying limitations of existing metrics, (2) introducing SiLVERScore for semantically-aware evaluation, (3) demonstrating its robustness to semantic and prosodic variations, and (4) exploring generalization challenges across datasets. On PHOENIX-14T and CSL-Daily datasets, SiLVERScore achieves near-perfect discrimination between correct and random pairs (ROC AUC = 0.99, overlap < 7%), substantially outperforming traditional metrics.
Alternating Training-based Label Smoothing Enhances Prompt Generalization
Aug 25, 2025



Recent advances in pre-trained vision-language models have demonstrated remarkable zero-shot generalization capabilities. To further enhance these models' adaptability to various downstream tasks, prompt tuning has emerged as a parameter-efficient fine-tuning method. However, despite its efficiency, the generalization ability of prompt remains limited. In contrast, label smoothing (LS) has been widely recognized as an effective regularization technique that prevents models from becoming over-confident and improves their generalization. This inspires us to explore the integration of LS with prompt tuning. However, we have observed that the vanilla LS even weakens the generalization ability of prompt tuning. To address this issue, we propose the Alternating Training-based Label Smoothing (ATLaS) method, which alternately trains with standard one-hot labels and soft labels generated by LS to supervise the prompt tuning. Moreover, we introduce two types of efficient offline soft labels, including Class-wise Soft Labels (CSL) and Instance-wise Soft Labels (ISL), to provide inter-class or instance-class relationships for prompt tuning. The theoretical properties of the proposed ATLaS method are analyzed. Extensive experiments demonstrate that the proposed ATLaS method, combined with CSL and ISL, consistently enhances the generalization performance of prompt tuning. Moreover, the proposed ATLaS method exhibits high compatibility with prevalent prompt tuning methods, enabling seamless integration into existing methods.
Beyond Gloss: A Hand-Centric Framework for Gloss-Free Sign Language Translation
Jul 31, 2025Sign Language Translation (SLT) is a challenging task that requires bridging the modality gap between visual and linguistic information while capturing subtle variations in hand shapes and movements. To address these challenges, we introduce \textbf{BeyondGloss}, a novel gloss-free SLT framework that leverages the spatio-temporal reasoning capabilities of Video Large Language Models (VideoLLMs). Since existing VideoLLMs struggle to model long videos in detail, we propose a novel approach to generate fine-grained, temporally-aware textual descriptions of hand motion. A contrastive alignment module aligns these descriptions with video features during pre-training, encouraging the model to focus on hand-centric temporal dynamics and distinguish signs more effectively. To further enrich hand-specific representations, we distill fine-grained features from HaMeR. Additionally, we apply a contrastive loss between sign video representations and target language embeddings to reduce the modality gap in pre-training. \textbf{BeyondGloss} achieves state-of-the-art performance on the Phoenix14T and CSL-Daily benchmarks, demonstrating the effectiveness of the proposed framework. We will release the code upon acceptance of the paper.