 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport-Set Based Cross-Supervision for Video Grounding
Aug 24, 2021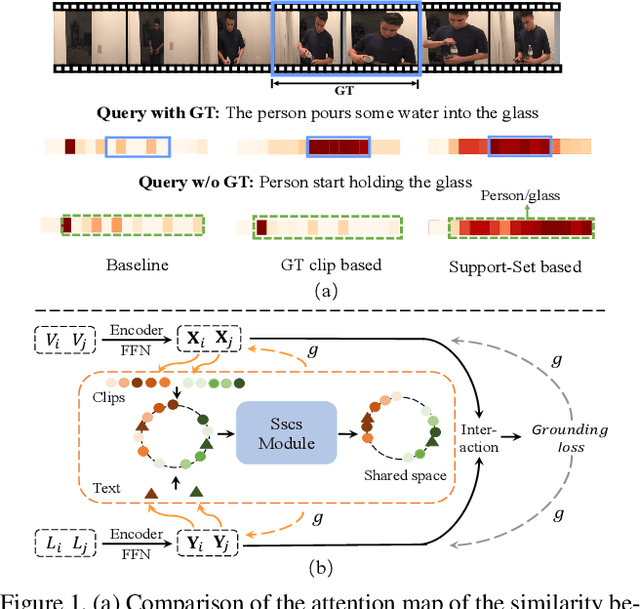
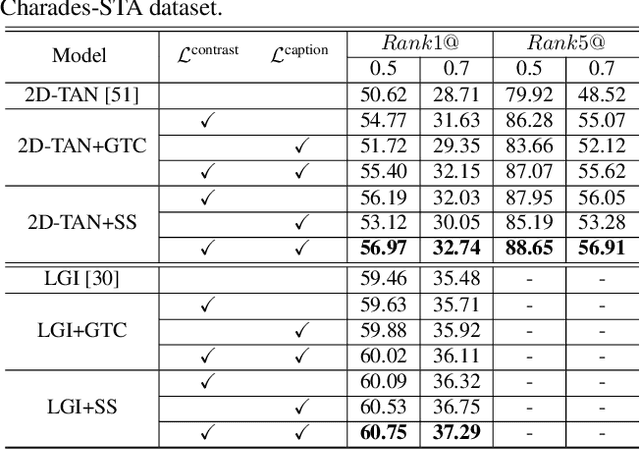

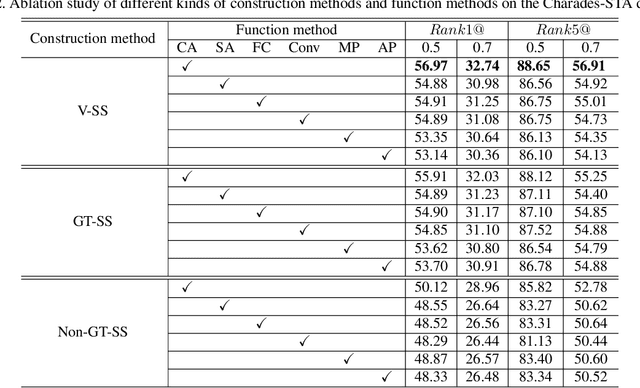
Current approaches for video grounding propose kinds of complex architectures to capture the video-text relations, and have achieved impressive improvements. However, it is hard to learn the complicated multi-modal relations by only architecture designing in fact. In this paper, we introduce a novel Support-set Based Cross-Supervision (Sscs) module which can improve existing methods during training phase without extra inference cost. The proposed Sscs module contains two main components, i.e., discriminative contrastive objective and generative caption objective. The contrastive objective aims to learn effective representations by contrastive learning, while the caption objective can train a powerful video encoder supervised by texts. Due to the co-existence of some visual entities in both ground-truth and background intervals, i.e., mutual exclusion, naively contrastive learning is unsuitable to video grounding. We address the problem by boosting the cross-supervision with the support-set concept, which collects visual information from the whole video and eliminates the mutual exclusion of entities. Combined with the original objectives, Sscs can enhance the abilities of multi-modal relation modeling for existing approaches. We extensively evaluate Sscs on three challenging datasets, and show that our method can improve current state-of-the-art methods by large margins, especially 6.35% in terms of R1@0.5 on Charades-STA.
Exploring Stronger Feature for Temporal Action Localization
Jun 24, 2021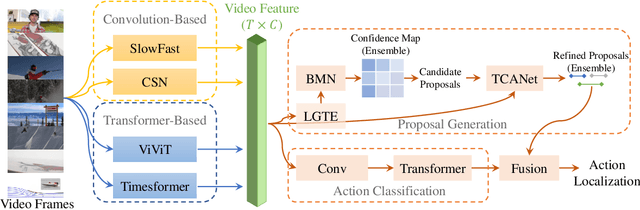
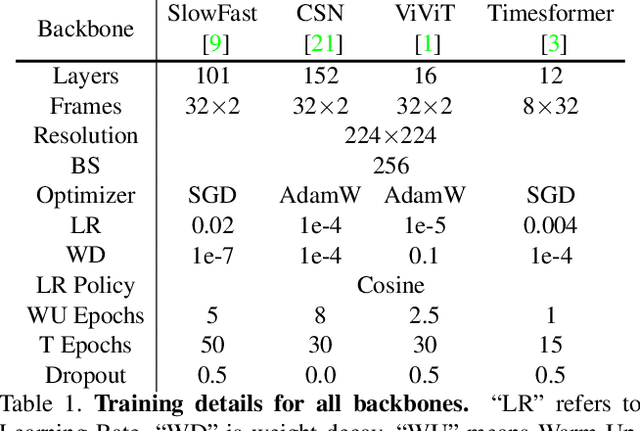

Temporal action localization aims to localize starting and ending time with action category. Limited by GPU memory, mainstream methods pre-extract features for each video. Therefore, feature quality determines the upper bound of detection performance. In this technical report, we explored classic convolution-based backbones and the recent surge of transformer-based backbones. We found that the transformer-based methods can achieve better classification performance than convolution-based, but they cannot generate accuracy action proposals. In addition, extracting features with larger frame resolution to reduce the loss of spatial information can also effectively improve the performance of temporal action localization. Finally, we achieve 42.42% in terms of mAP on validation set with a single SlowFast feature by a simple combination: BMN+TCANet, which is 1.87% higher than the result of 2020's multi-model ensemble. Finally, we achieve Rank 1st on the CVPR2021 HACS supervised Temporal Action Localization Challenge.
Weakly-Supervised Temporal Action Localization Through Local-Global Background Modeling
Jun 20, 2021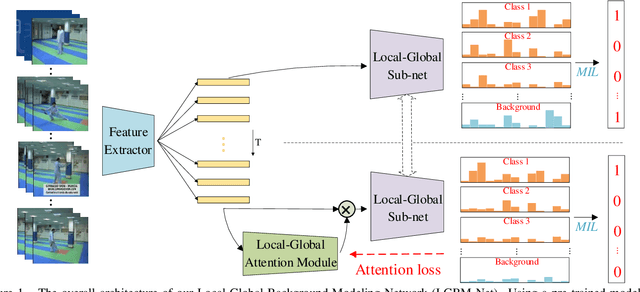
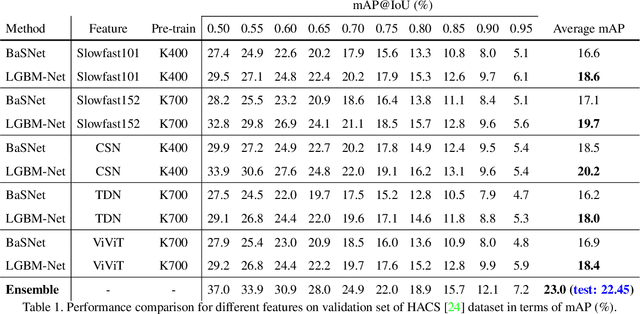
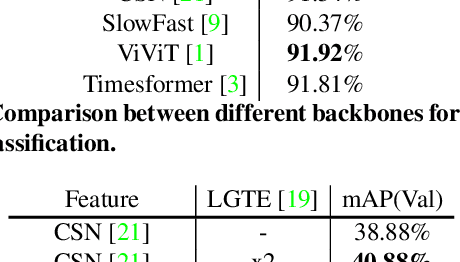
Weakly-Supervised Temporal Action Localization (WS-TAL) task aims to recognize and localize temporal starts and ends of action instances in an untrimmed video with only video-level label supervision. Due to lack of negative samples of background category, it is difficult for the network to separate foreground and background, resulting in poor detection performance. In this report, we present our 2021 HACS Challenge - Weakly-supervised Learning Track solution that based on BaSNet to address above problem. Specifically, we first adopt pre-trained CSN, Slowfast, TDN, and ViViT as feature extractors to get feature sequences. Then our proposed Local-Global Background Modeling Network (LGBM-Net) is trained to localize instances by using only video-level labels based on Multi-Instance Learning (MIL). Finally, we ensemble multiple models to get the final detection results and reach 22.45% mAP on the test set
* CVPR-2021 HACS Challenge - Weakly-supervised Learning Track champion solution (1st Place)
Proposal Relation Network for Temporal Action Detection
Jun 20, 2021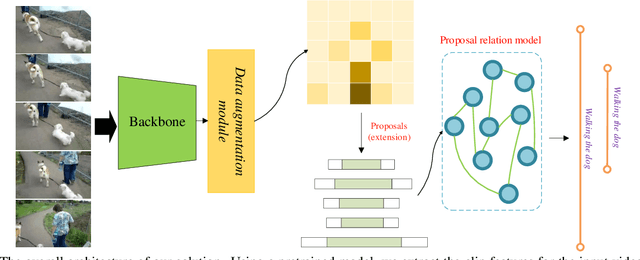
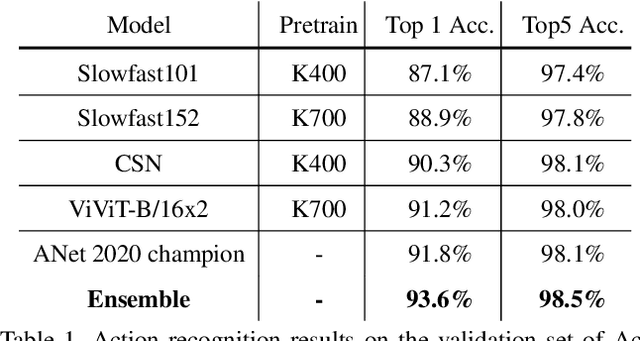
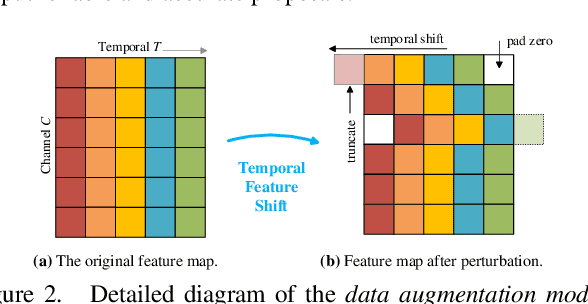

This technical report presents our solution for temporal action detection task in AcitivityNet Challenge 2021. The purpose of this task is to locate and identify actions of interest in long untrimmed videos. The crucial challenge of the task comes from that the temporal duration of action varies dramatically, and the target actions are typically embedded in a background of irrelevant activities. Our solution builds on BMN, and mainly contains three steps: 1) action classification and feature encoding by Slowfast, CSN and ViViT; 2) proposal generation. We improve BMN by embedding the proposed Proposal Relation Network (PRN), by which we can generate proposals of high quality; 3) action detection. We calculate the detection results by assigning the proposals with corresponding classification results. Finally, we ensemble the results under different settings and achieve 44.7% on the test set, which improves the champion result in ActivityNet 2020 by 1.9% in terms of average mAP.
* CVPR-2021 ActivityNet Temporal Action Localization Challenge champion solution (1st Place)
Relation Modeling in Spatio-Temporal Action Localization
Jun 16, 2021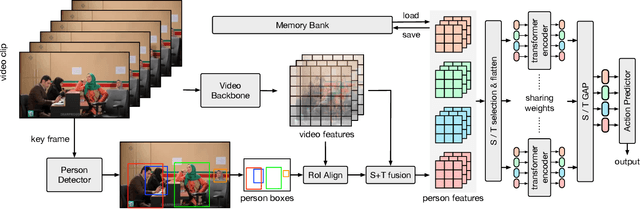
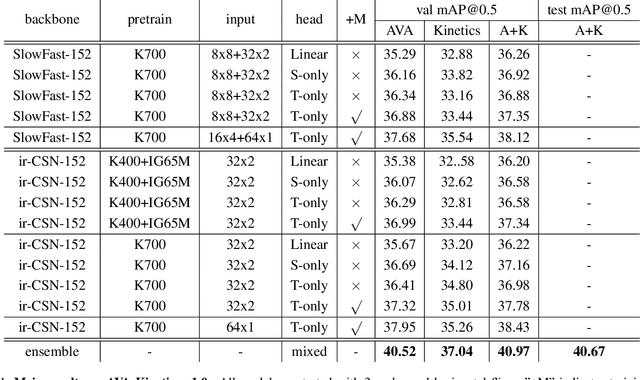
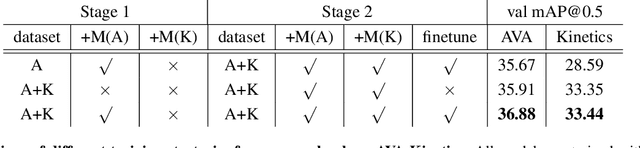
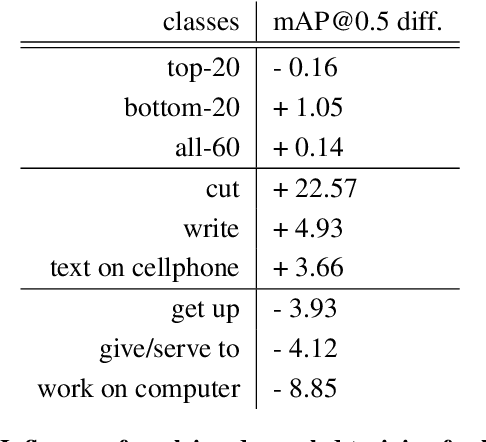
This paper presents our solution to the AVA-Kinetics Crossover Challenge of ActivityNet workshop at CVPR 2021. Our solution utilizes multiple types of relation modeling methods for spatio-temporal action detection and adopts a training strategy to integrate multiple relation modeling in end-to-end training over the two large-scale video datasets. Learning with memory bank and finetuning for long-tailed distribution are also investigated to further improve the performance. In this paper, we detail the implementations of our solution and provide experiments results and corresponding discussions. We finally achieve 40.67 mAP on the test set of AVA-Kinetics.
A Stronger Baseline for Ego-Centric Action Detection
Jun 13, 2021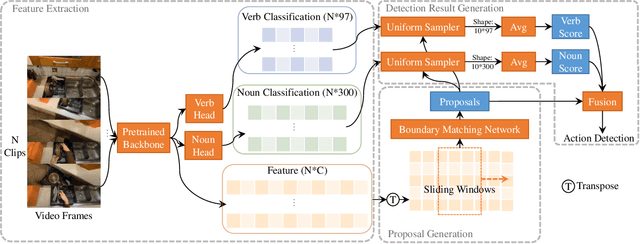
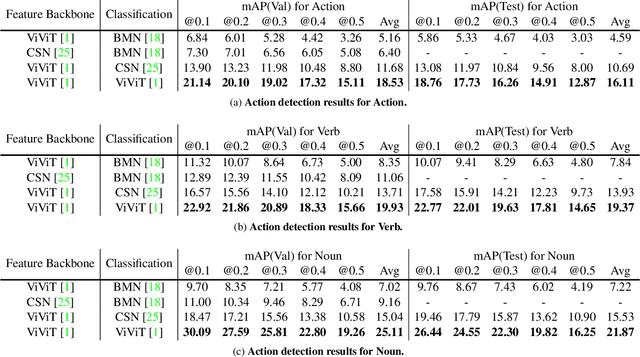
This technical report analyzes an egocentric video action detection method we used in the 2021 EPIC-KITCHENS-100 competition hosted in CVPR2021 Workshop. The goal of our task is to locate the start time and the end time of the action in the long untrimmed video, and predict action category. We adopt sliding window strategy to generate proposals, which can better adapt to short-duration actions. In addition, we show that classification and proposals are conflict in the same network. The separation of the two tasks boost the detection performance with high efficiency. By simply employing these strategy, we achieved 16.10\% performance on the test set of EPIC-KITCHENS-100 Action Detection challenge using a single model, surpassing the baseline method by 11.7\% in terms of average mAP.
Towards Training Stronger Video Vision Transformers for EPIC-KITCHENS-100 Action Recognition
Jun 09, 2021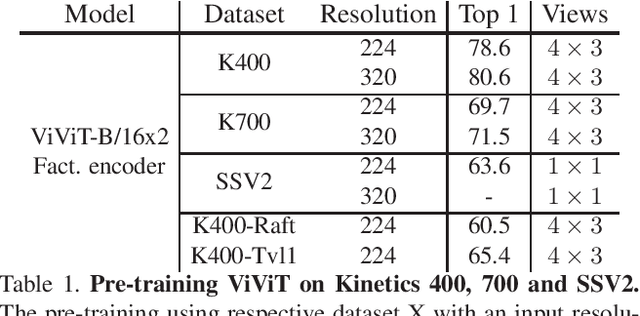
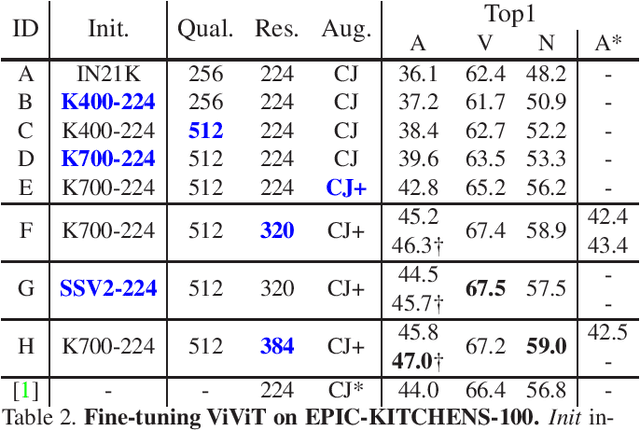
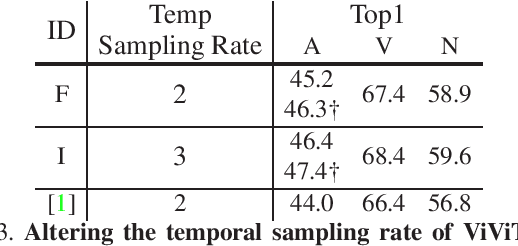
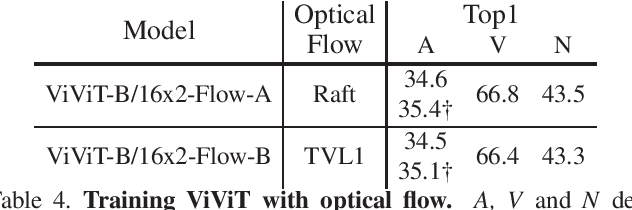
With the recent surge in the research of vision transformers, they have demonstrated remarkable potential for various challenging computer vision applications, such as image recognition, point cloud classification as well as video understanding. In this paper, we present empirical results for training a stronger video vision transformer on the EPIC-KITCHENS-100 Action Recognition dataset. Specifically, we explore training techniques for video vision transformers, such as augmentations, resolutions as well as initialization, etc. With our training recipe, a single ViViT model achieves the performance of 47.4\% on the validation set of EPIC-KITCHENS-100 dataset, outperforming what is reported in the original paper by 3.4%. We found that video transformers are especially good at predicting the noun in the verb-noun action prediction task. This makes the overall action prediction accuracy of video transformers notably higher than convolutional ones. Surprisingly, even the best video transformers underperform the convolutional networks on the verb prediction. Therefore, we combine the video vision transformers and some of the convolutional video networks and present our solution to the EPIC-KITCHENS-100 Action Recognition competition.
Multi-Scale Feature Aggregation by Cross-Scale Pixel-to-Region Relation Operation for Semantic Segmentation
Jun 03, 2021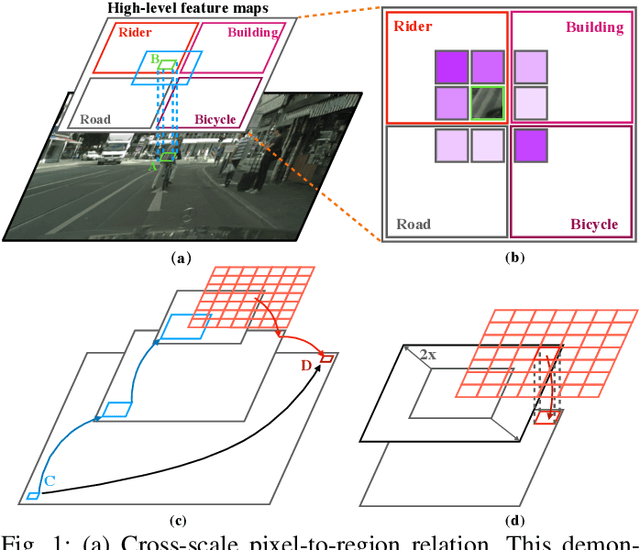
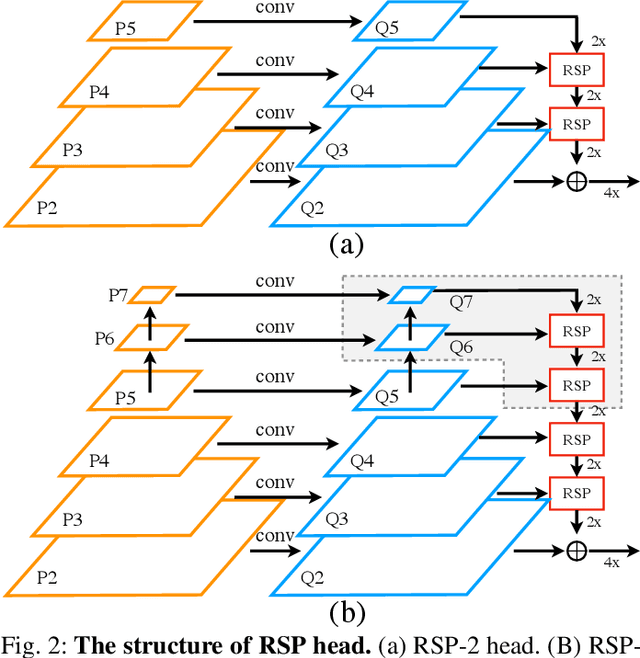
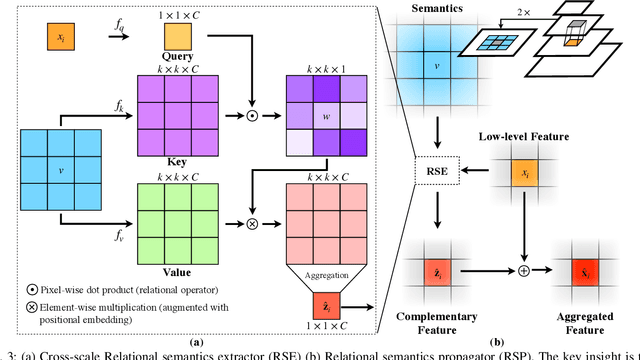

Exploiting multi-scale features has shown great potential in tackling semantic segmentation problems. The aggregation is commonly done with sum or concatenation (concat) followed by convolutional (conv) layers. However, it fully passes down the high-level context to the following hierarchy without considering their interrelation. In this work, we aim to enable the low-level feature to aggregate the complementary context from adjacent high-level feature maps by a cross-scale pixel-to-region relation operation. We leverage cross-scale context propagation to make the long-range dependency capturable even by the high-resolution low-level features. To this end, we employ an efficient feature pyramid network to obtain multi-scale features. We propose a Relational Semantics Extractor (RSE) and Relational Semantics Propagator (RSP) for context extraction and propagation respectively. Then we stack several RSP into an RSP head to achieve the progressive top-down distribution of the context. Experiment results on two challenging datasets Cityscapes and COCO demonstrate that the RSP head performs competitively on both semantic segmentation and panoptic segmentation with high efficiency. It outperforms DeeplabV3 [1] by 0.7% with 75% fewer FLOPs (multiply-adds) in the semantic segmentation task.
Self-supervised Motion Learning from Static Images
Apr 01, 2021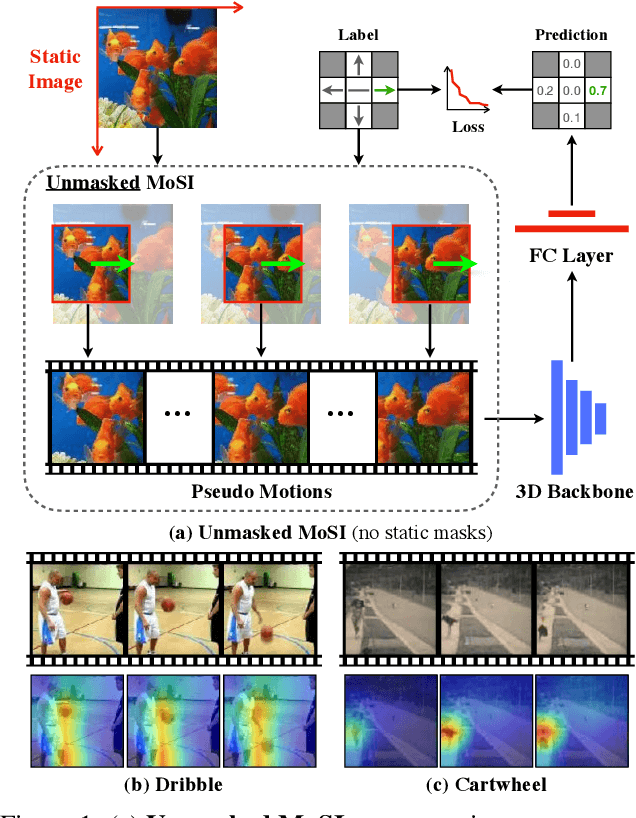
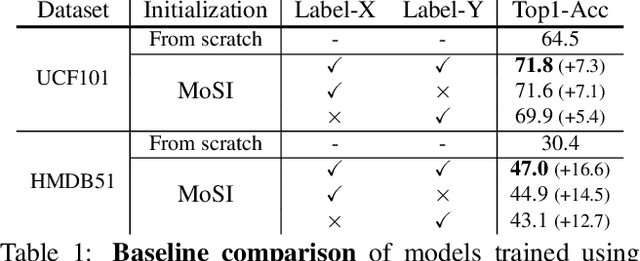
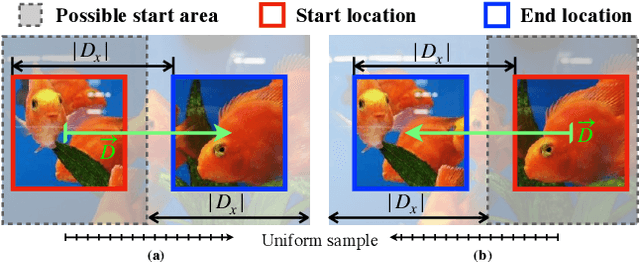
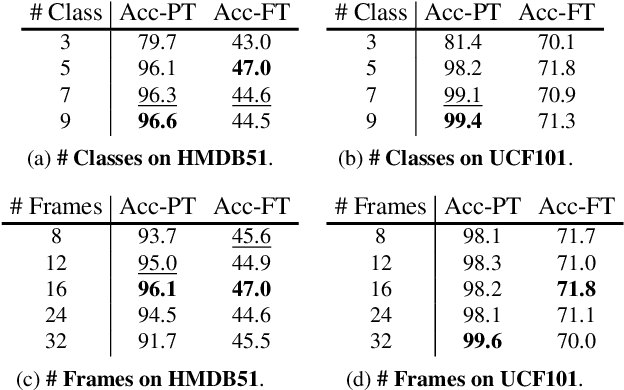
Motions are reflected in videos as the movement of pixels, and actions are essentially patterns of inconsistent motions between the foreground and the background. To well distinguish the actions, especially those with complicated spatio-temporal interactions, correctly locating the prominent motion areas is of crucial importance. However, most motion information in existing videos are difficult to label and training a model with good motion representations with supervision will thus require a large amount of human labour for annotation. In this paper, we address this problem by self-supervised learning. Specifically, we propose to learn Motion from Static Images (MoSI). The model learns to encode motion information by classifying pseudo motions generated by MoSI. We furthermore introduce a static mask in pseudo motions to create local motion patterns, which forces the model to additionally locate notable motion areas for the correct classification.We demonstrate that MoSI can discover regions with large motion even without fine-tuning on the downstream datasets. As a result, the learned motion representations boost the performance of tasks requiring understanding of complex scenes and motions, i.e., action recognition. Extensive experiments show the consistent and transferable improvements achieved by MoSI. Codes will be soon released.
Towards Accurate Human Pose Estimation in Videos of Crowded Scenes
Oct 21, 2020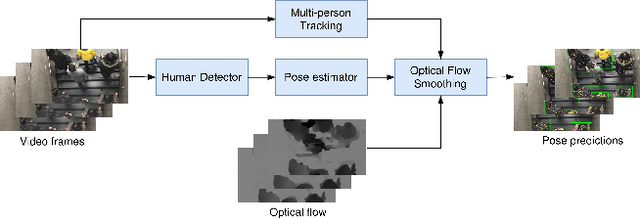

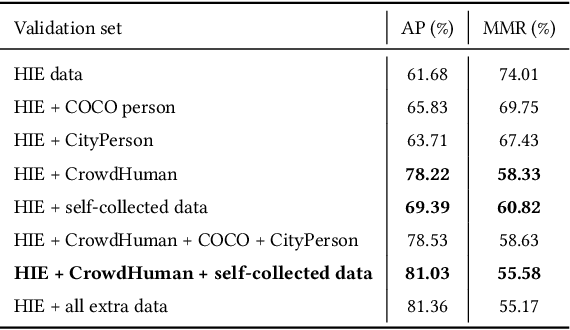
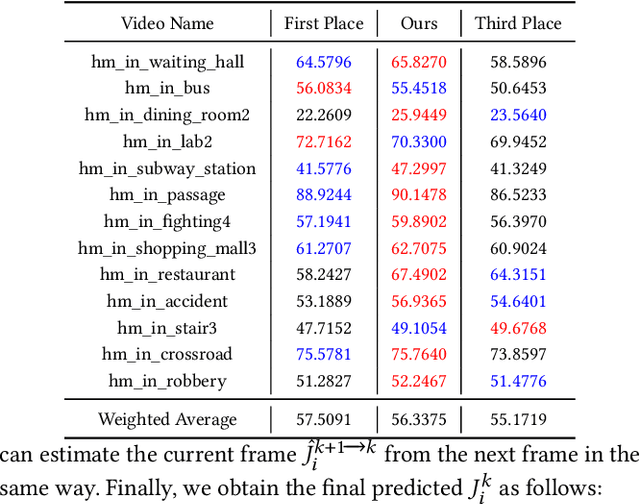
Video-based human pose estimation in crowded scenes is a challenging problem due to occlusion, motion blur, scale variation and viewpoint change, etc. Prior approaches always fail to deal with this problem because of (1) lacking of usage of temporal information; (2) lacking of training data in crowded scenes. In this paper, we focus on improving human pose estimation in videos of crowded scenes from the perspectives of exploiting temporal context and collecting new data. In particular, we first follow the top-down strategy to detect persons and perform single-person pose estimation for each frame. Then, we refine the frame-based pose estimation with temporal contexts deriving from the optical-flow. Specifically, for one frame, we forward the historical poses from the previous frames and backward the future poses from the subsequent frames to current frame, leading to stable and accurate human pose estimation in videos. In addition, we mine new data of similar scenes to HIE dataset from the Internet for improving the diversity of training set. In this way, our model achieves best performance on 7 out of 13 videos and 56.33 average w\_AP on test dataset of HIE challenge.