 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Super-Resolution: All You Need is a Video Diffusion Model
Mar 05, 2025



We present a generic video super-resolution algorithm in this paper, based on the Diffusion Posterior Sampling framework with an unconditional video generation model in latent space. The video generation model, a diffusion transformer, functions as a space-time model. We argue that a powerful model, which learns the physics of the real world, can easily handle various kinds of motion patterns as prior knowledge, thus eliminating the need for explicit estimation of optical flows or motion parameters for pixel alignment. Furthermore, a single instance of the proposed video diffusion transformer model can adapt to different sampling conditions without re-training. Due to limited computational resources and training data, our experiments provide empirical evidence of the algorithm's strong super-resolution capabilities using synthetic data.
BIMS-PU: Bi-Directional and Multi-Scale Point Cloud Upsampling
Jun 25, 2022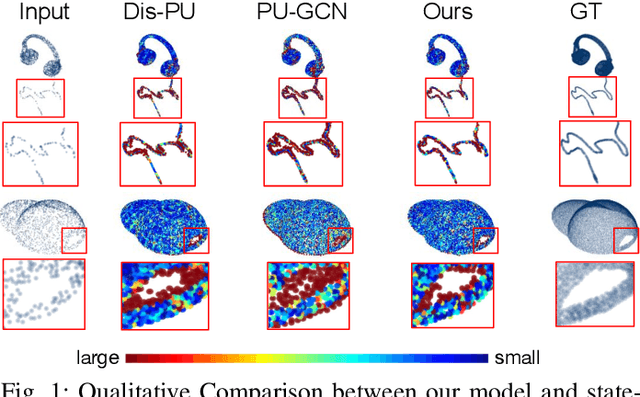
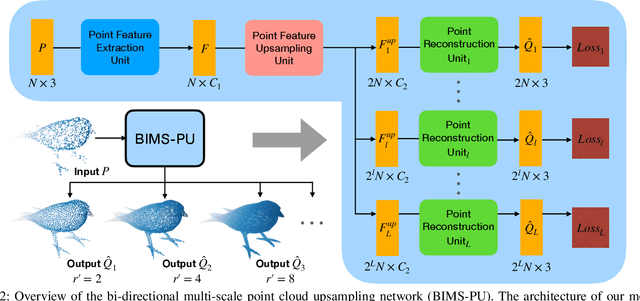
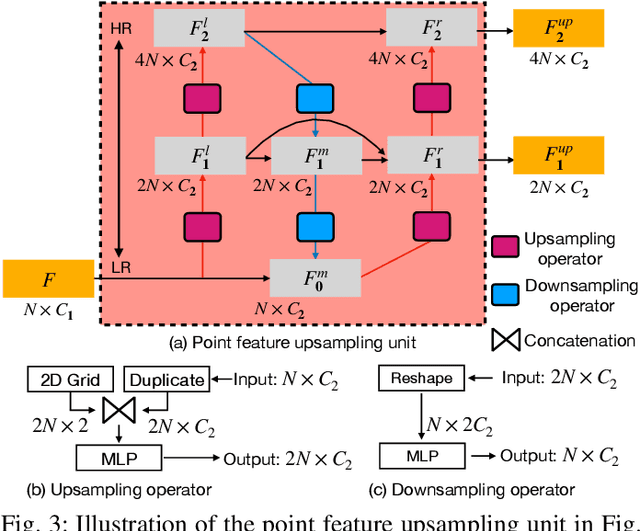
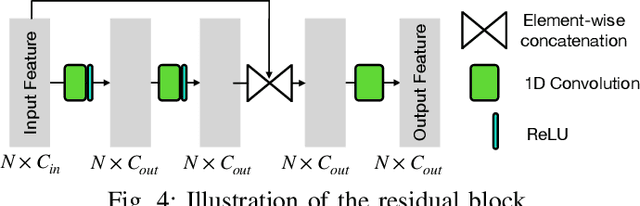
The learning and aggregation of multi-scale features are essential in empowering neural networks to capture the fine-grained geometric details in the point cloud upsampling task. Most existing approaches extract multi-scale features from a point cloud of a fixed resolution, hence obtain only a limited level of details. Though an existing approach aggregates a feature hierarchy of different resolutions from a cascade of upsampling sub-network, the training is complex with expensive computation. To address these issues, we construct a new point cloud upsampling pipeline called BIMS-PU that integrates the feature pyramid architecture with a bi-directional up and downsampling path. Specifically, we decompose the up/downsampling procedure into several up/downsampling sub-steps by breaking the target sampling factor into smaller factors. The multi-scale features are naturally produced in a parallel manner and aggregated using a fast feature fusion method. Supervision signal is simultaneously applied to all upsampled point clouds of different scales. Moreover, we formulate a residual block to ease the training of our model. Extensive quantitative and qualitative experiments on different datasets show that our method achieves superior results to state-of-the-art approaches. Last but not least, we demonstrate that point cloud upsampling can improve robot perception by ameliorating the 3D data quality.
* Accepted to RA-L 2022. in IEEE Robotics and Automation Letters
Multi-Scale Feature Aggregation by Cross-Scale Pixel-to-Region Relation Operation for Semantic Segmentation
Jun 03, 2021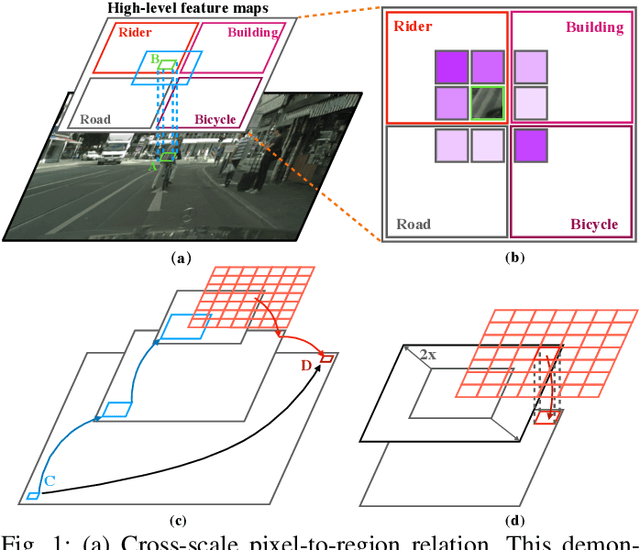
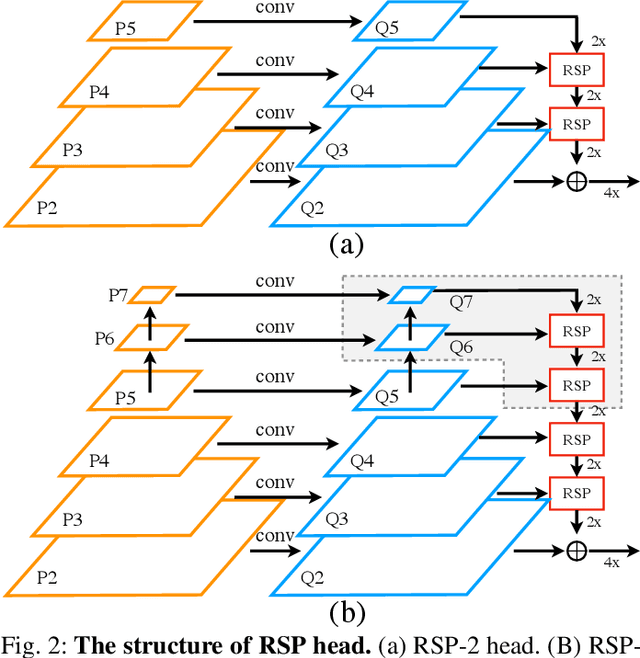
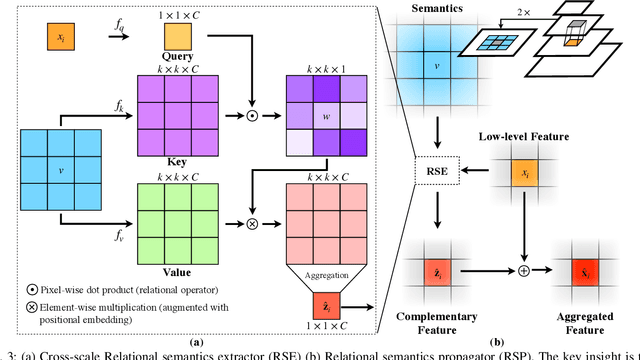

Exploiting multi-scale features has shown great potential in tackling semantic segmentation problems. The aggregation is commonly done with sum or concatenation (concat) followed by convolutional (conv) layers. However, it fully passes down the high-level context to the following hierarchy without considering their interrelation. In this work, we aim to enable the low-level feature to aggregate the complementary context from adjacent high-level feature maps by a cross-scale pixel-to-region relation operation. We leverage cross-scale context propagation to make the long-range dependency capturable even by the high-resolution low-level features. To this end, we employ an efficient feature pyramid network to obtain multi-scale features. We propose a Relational Semantics Extractor (RSE) and Relational Semantics Propagator (RSP) for context extraction and propagation respectively. Then we stack several RSP into an RSP head to achieve the progressive top-down distribution of the context. Experiment results on two challenging datasets Cityscapes and COCO demonstrate that the RSP head performs competitively on both semantic segmentation and panoptic segmentation with high efficiency. It outperforms DeeplabV3 [1] by 0.7% with 75% fewer FLOPs (multiply-adds) in the semantic segmentation task.
Group Sparsity Residual with Non-Local Samples for Image Denoising
Mar 22, 2018
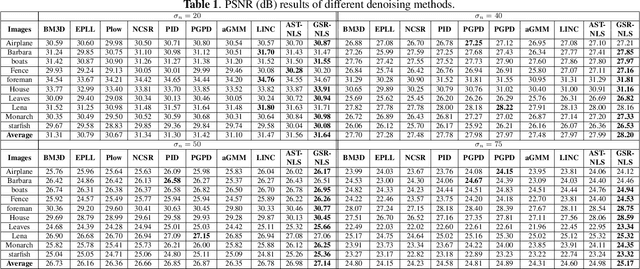


Inspired by group-based sparse coding, recently proposed group sparsity residual (GSR) scheme has demonstrated superior performance in image processing. However, one challenge in GSR is to estimate the residual by using a proper reference of the group-based sparse coding (GSC), which is desired to be as close to the truth as possible. Previous researches utilized the estimations from other algorithms (i.e., GMM or BM3D), which are either not accurate or too slow. In this paper, we propose to use the Non-Local Samples (NLS) as reference in the GSR regime for image denoising, thus termed GSR-NLS. More specifically, we first obtain a good estimation of the group sparse coefficients by the image nonlocal self-similarity, and then solve the GSR model by an effective iterative shrinkage algorithm. Experimental results demonstrate that the proposed GSR-NLS not only outperforms many state-of-the-art methods, but also delivers the competitive advantage of speed.
Image denoising via group sparsity residual constraint
Mar 03, 2017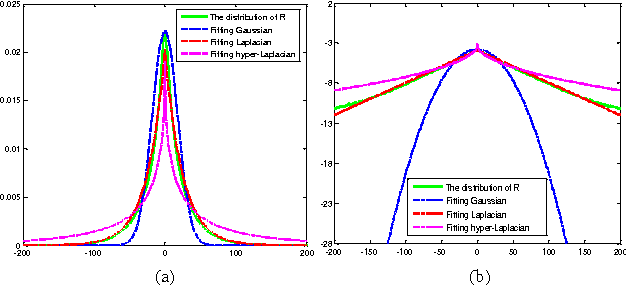
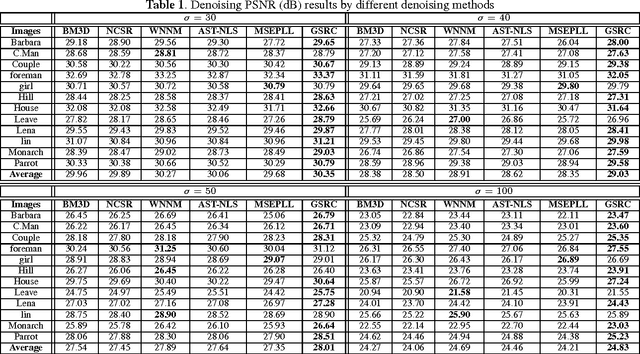


Group sparsity has shown great potential in various low-level vision tasks (e.g, image denoising, deblurring and inpainting). In this paper, we propose a new prior model for image denoising via group sparsity residual constraint (GSRC). To enhance the performance of group sparse-based image denoising, the concept of group sparsity residual is proposed, and thus, the problem of image denoising is translated into one that reduces the group sparsity residual. To reduce the residual, we first obtain some good estimation of the group sparse coefficients of the original image by the first-pass estimation of noisy image, and then centralize the group sparse coefficients of noisy image to the estimation. Experimental results have demonstrated that the proposed method not only outperforms many state-of-the-art denoising methods such as BM3D and WNNM, but results in a faster speed.
Image denoising using group sparsity residual and external nonlocal self-similarity prior
Jan 03, 2017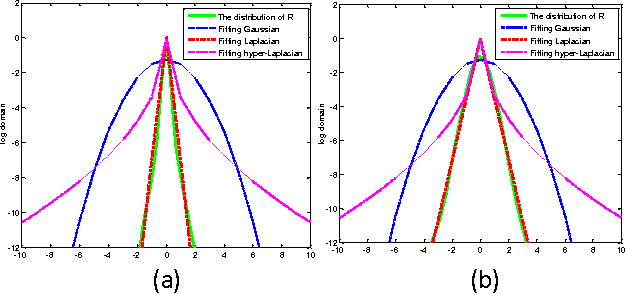
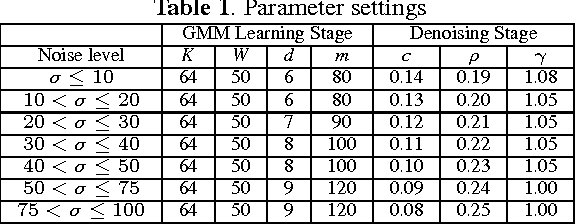


Nonlocal image representation has been successfully used in many image-related inverse problems including denoising, deblurring and deblocking. However, a majority of reconstruction methods only exploit the nonlocal self-similarity (NSS) prior of the degraded observation image, it is very challenging to reconstruct the latent clean image. In this paper we propose a novel model for image denoising via group sparsity residual and external NSS prior. To boost the performance of image denoising, the concept of group sparsity residual is proposed, and thus the problem of image denoising is transformed into one that reduces the group sparsity residual. Due to the fact that the groups contain a large amount of NSS information of natural images, we obtain a good estimation of the group sparse coefficients of the original image by the external NSS prior based on Gaussian Mixture model (GMM) learning and the group sparse coefficients of noisy image is used to approximate the estimation. Experimental results have demonstrated that the proposed method not only outperforms many state-of-the-art methods, but also delivers the best qualitative denoising results with finer details and less ringing artifacts.