 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Alignment by Fine-tuning Embeddings on Parallel Corpora
Jan 24, 2021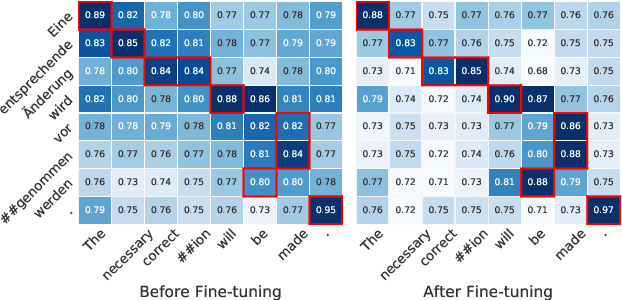

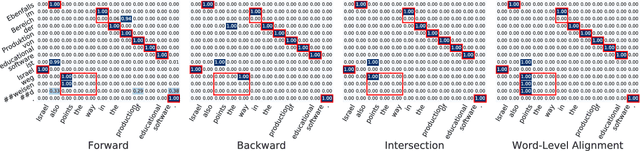
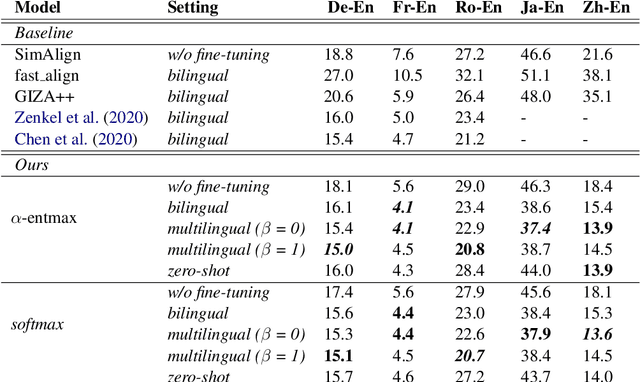
Word alignment over parallel corpora has a wide variety of applications, including learning translation lexicons, cross-lingual transfer of language processing tools, and automatic evaluation or analysis of translation outputs. The great majority of past work on word alignment has worked by performing unsupervised learning on parallel texts. Recently, however, other work has demonstrated that pre-trained contextualized word embeddings derived from multilingually trained language models (LMs) prove an attractive alternative, achieving competitive results on the word alignment task even in the absence of explicit training on parallel data. In this paper, we examine methods to marry the two approaches: leveraging pre-trained LMs but fine-tuning them on parallel text with objectives designed to improve alignment quality, and proposing methods to effectively extract alignments from these fine-tuned models. We perform experiments on five language pairs and demonstrate that our model can consistently outperform previous state-of-the-art models of all varieties. In addition, we demonstrate that we are able to train multilingual word aligners that can obtain robust performance on different language pairs. Our aligner, AWESOME (Aligning Word Embedding Spaces of Multilingual Encoders), with pre-trained models is available at https://github.com/neulab/awesome-align
CDEvalSumm: An Empirical Study of Cross-Dataset Evaluation for Neural Summarization Systems
Oct 22, 2020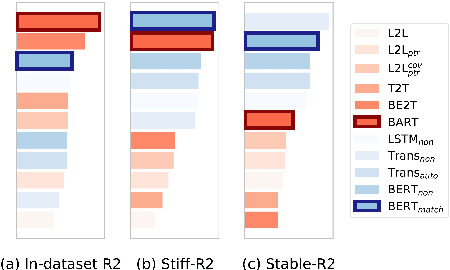
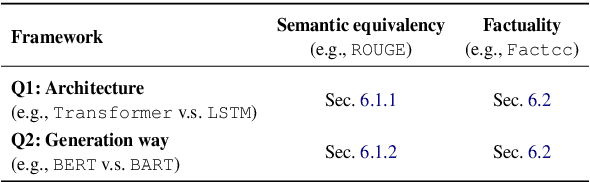

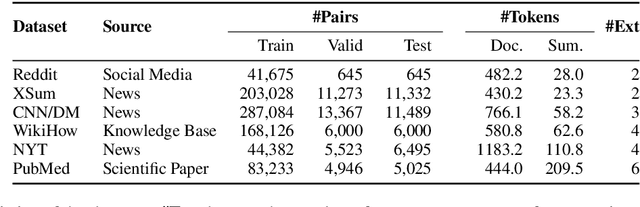
Neural network-based models augmented with unsupervised pre-trained knowledge have achieved impressive performance on text summarization. However, most existing evaluation methods are limited to an in-domain setting, where summarizers are trained and evaluated on the same dataset. We argue that this approach can narrow our understanding of the generalization ability for different summarization systems. In this paper, we perform an in-depth analysis of characteristics of different datasets and investigate the performance of different summarization models under a cross-dataset setting, in which a summarizer trained on one corpus will be evaluated on a range of out-of-domain corpora. A comprehensive study of 11 representative summarization systems on 5 datasets from different domains reveals the effect of model architectures and generation ways (i.e. abstractive and extractive) on model generalization ability. Further, experimental results shed light on the limitations of existing summarizers. Brief introduction and supplementary code can be found in https://github.com/zide05/CDEvalSumm.
GSum: A General Framework for Guided Neural Abstractive Summarization
Oct 15, 2020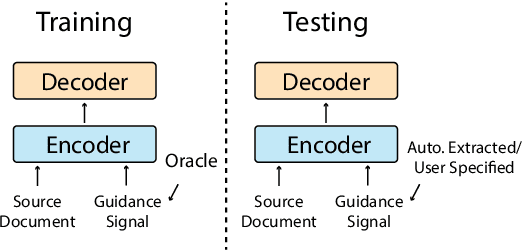
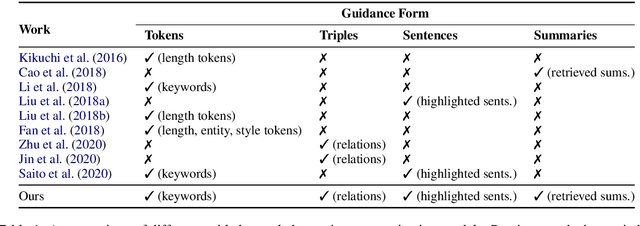
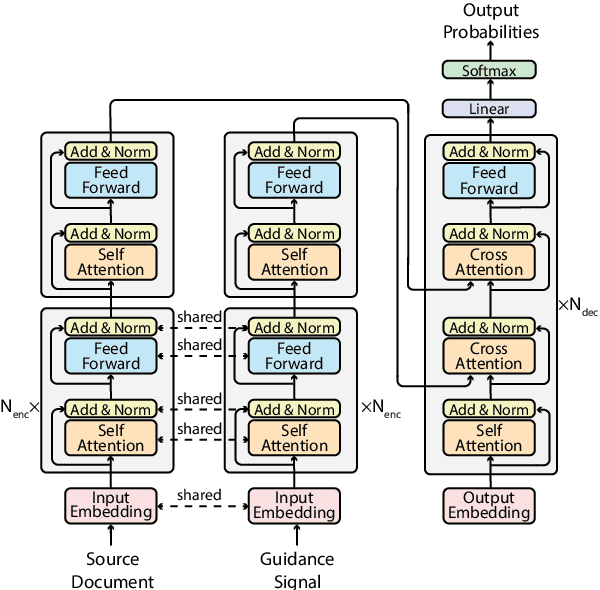
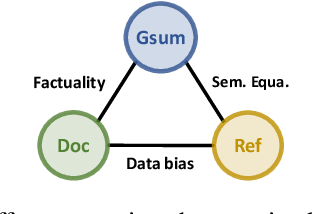
Neural abstractive summarization models are flexible and can produce coherent summaries, but they are sometimes unfaithful and can be difficult to control. While previous studies attempt to provide different types of guidance to control the output and increase faithfulness, it is not clear how these strategies compare and contrast to each other. In this paper, we propose a general and extensible guided summarization framework (GSum) that can effectively take different kinds of external guidance as input, and we perform experiments across several different varieties. Experiments demonstrate that this model is effective, achieving state-of-the-art performance according to ROUGE on 4 popular summarization datasets when using highlighted sentences as guidance. In addition, we show that our guided model can generate more faithful summaries and demonstrate how different types of guidance generate qualitatively different summaries, lending a degree of controllability to the learned models.
TICO-19: the Translation Initiative for Covid-19
Jul 06, 2020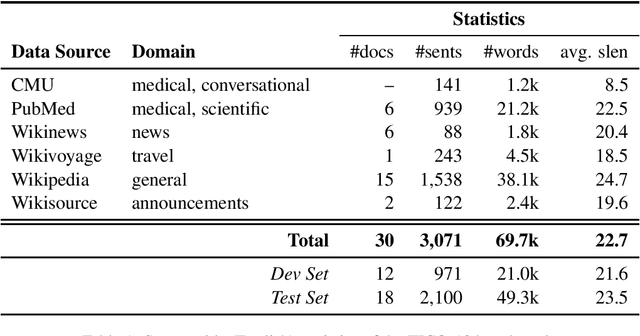
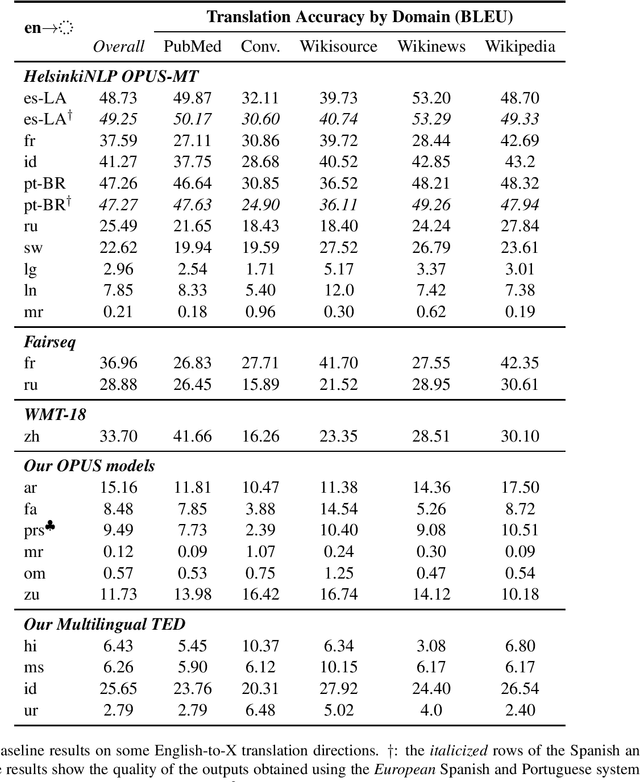
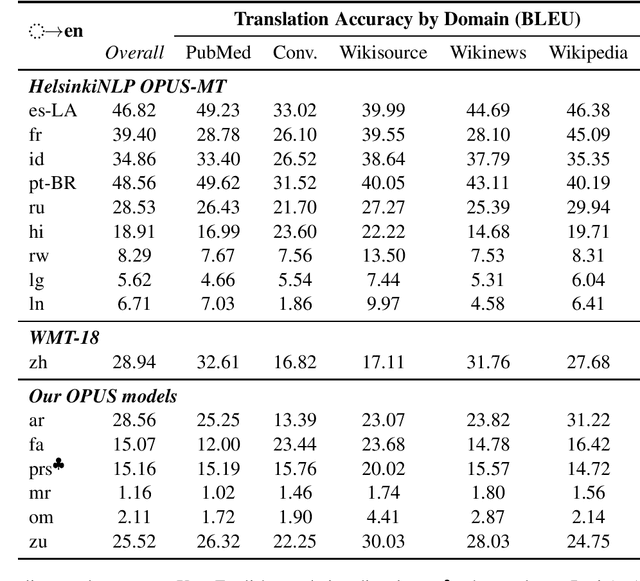
The COVID-19 pandemic is the worst pandemic to strike the world in over a century. Crucial to stemming the tide of the SARS-CoV-2 virus is communicating to vulnerable populations the means by which they can protect themselves. To this end, the collaborators forming the Translation Initiative for COvid-19 (TICO-19) have made test and development data available to AI and MT researchers in 35 different languages in order to foster the development of tools and resources for improving access to information about COVID-19 in these languages. In addition to 9 high-resourced, "pivot" languages, the team is targeting 26 lesser resourced languages, in particular languages of Africa, South Asia and South-East Asia, whose populations may be the most vulnerable to the spread of the virus. The same data is translated into all of the languages represented, meaning that testing or development can be done for any pairing of languages in the set. Further, the team is converting the test and development data into translation memories (TMXs) that can be used by localizers from and to any of the languages.
A Deep Reinforced Model for Zero-Shot Cross-Lingual Summarization with Bilingual Semantic Similarity Rewards
Jun 27, 2020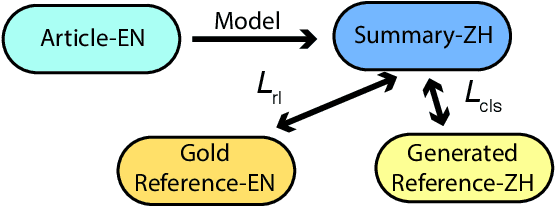
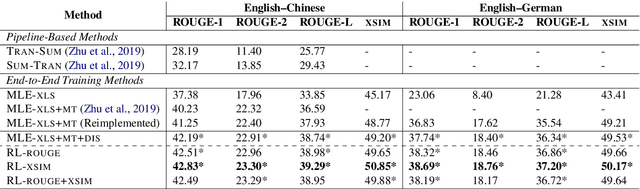
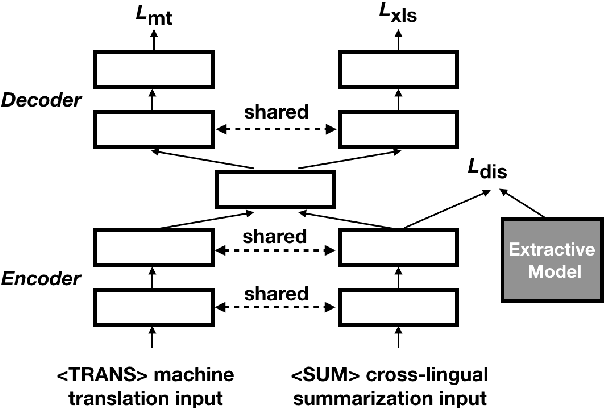
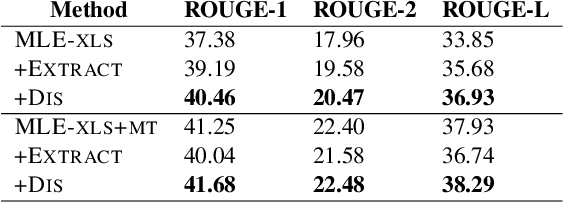
Cross-lingual text summarization aims at generating a document summary in one language given input in another language. It is a practically important but under-explored task, primarily due to the dearth of available data. Existing methods resort to machine translation to synthesize training data, but such pipeline approaches suffer from error propagation. In this work, we propose an end-to-end cross-lingual text summarization model. The model uses reinforcement learning to directly optimize a bilingual semantic similarity metric between the summaries generated in a target language and gold summaries in a source language. We also introduce techniques to pre-train the model leveraging monolingual summarization and machine translation objectives. Experimental results in both English--Chinese and English--German cross-lingual summarization settings demonstrate the effectiveness of our methods. In addition, we find that reinforcement learning models with bilingual semantic similarity as rewards generate more fluent sentences than strong baselines.
Dynamic Data Selection and Weighting for Iterative Back-Translation
Apr 07, 2020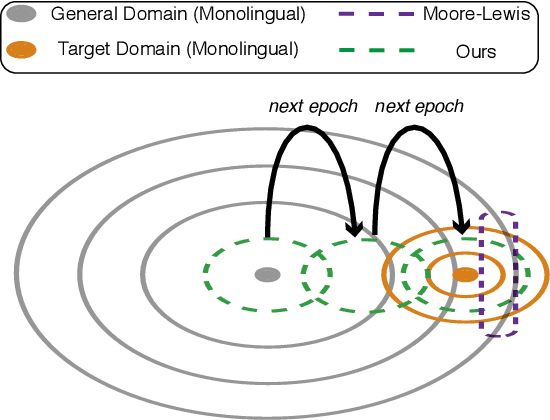
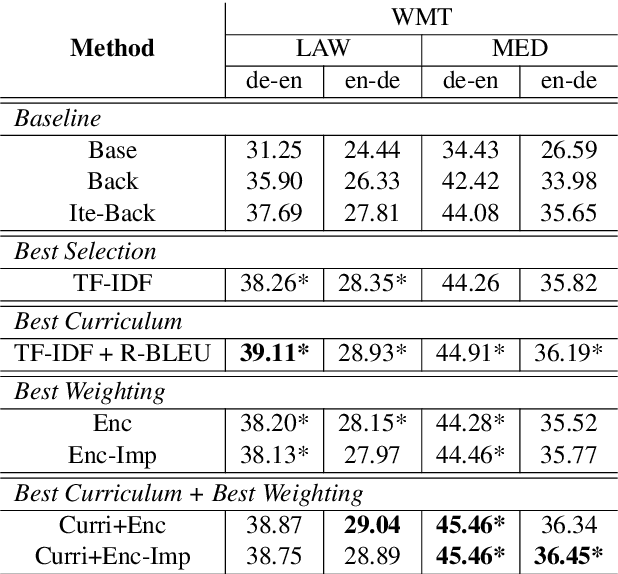

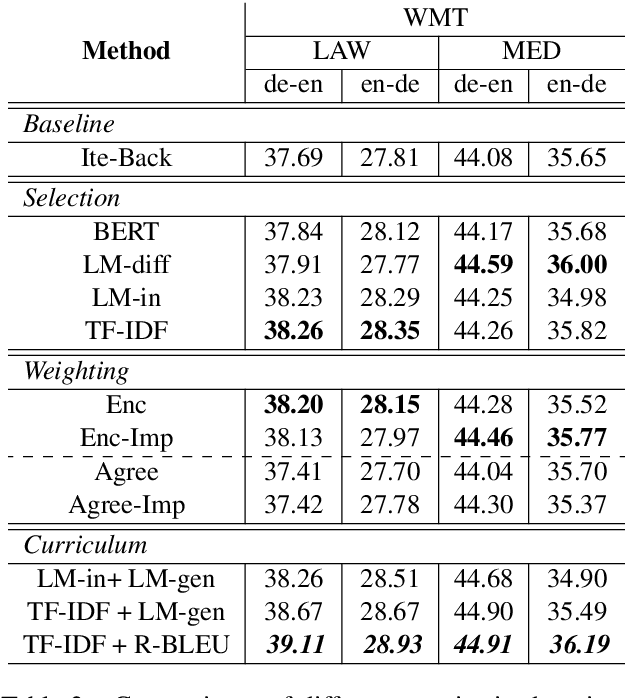
Back-translation has proven to be an effective method to utilize monolingual data in neural machine translation (NMT), and iteratively conducting back-translation can further improve the model performance. Selecting which monolingual data to back-translate is crucial, as we require that the resulting synthetic data are of high quality \textit{and} reflect the target domain. To achieve these two goals, data selection and weighting strategies have been proposed, with a common practice being to select samples close to the target domain but also dissimilar to the average general-domain text. In this paper, we provide insights into this commonly used approach and generalize it to a dynamic curriculum learning strategy, which is applied to iterative back-translation models. In addition, we propose weighting strategies based on both the current quality of the sentence and its improvement over the previous iteration. We evaluate our models on domain adaptation, low-resource, and high-resource MT settings and on two language pairs. Experimental results demonstrate that our methods achieve improvements of up to 1.8 BLEU points over competitive baselines.
Domain Differential Adaptation for Neural Machine Translation
Oct 07, 2019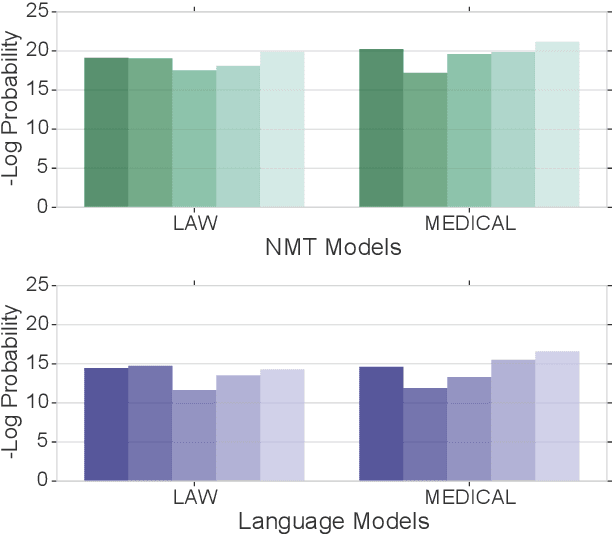
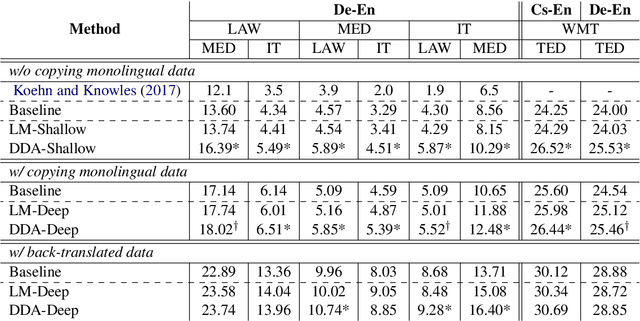
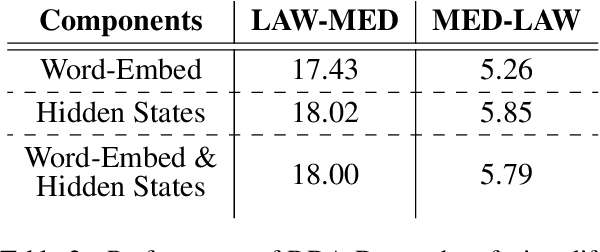
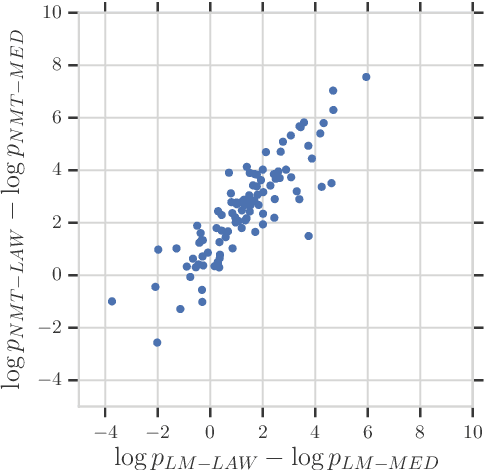
Neural networks are known to be data hungry and domain sensitive, but it is nearly impossible to obtain large quantities of labeled data for every domain we are interested in. This necessitates the use of domain adaptation strategies. One common strategy encourages generalization by aligning the global distribution statistics between source and target domains, but one drawback is that the statistics of different domains or tasks are inherently divergent, and smoothing over these differences can lead to sub-optimal performance. In this paper, we propose the framework of {\it Domain Differential Adaptation (DDA)}, where instead of smoothing over these differences we embrace them, directly modeling the difference between domains using models in a related task. We then use these learned domain differentials to adapt models for the target task accordingly. Experimental results on domain adaptation for neural machine translation demonstrate the effectiveness of this strategy, achieving consistent improvements over other alternative adaptation strategies in multiple experimental settings.
Unsupervised Domain Adaptation for Neural Machine Translation with Domain-Aware Feature Embeddings
Aug 27, 2019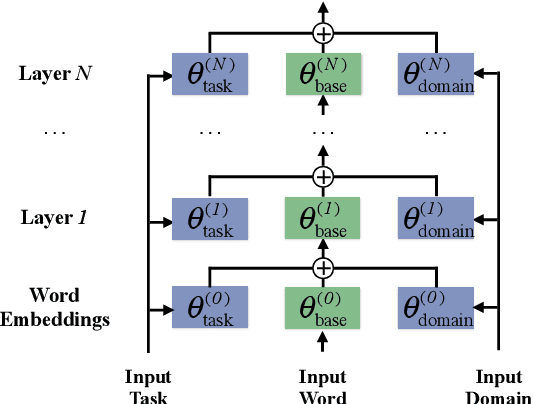
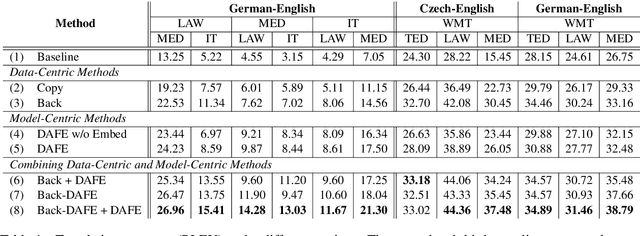
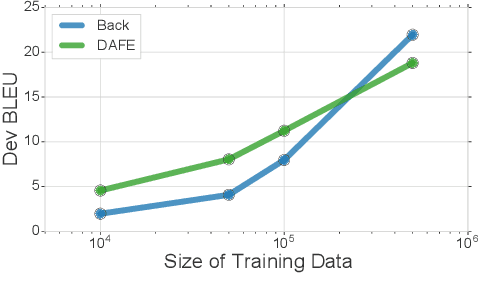

The recent success of neural machine translation models relies on the availability of high quality, in-domain data. Domain adaptation is required when domain-specific data is scarce or nonexistent. Previous unsupervised domain adaptation strategies include training the model with in-domain copied monolingual or back-translated data. However, these methods use generic representations for text regardless of domain shift, which makes it infeasible for translation models to control outputs conditional on a specific domain. In this work, we propose an approach that adapts models with domain-aware feature embeddings, which are learned via an auxiliary language modeling task. Our approach allows the model to assign domain-specific representations to words and output sentences in the desired domain. Our empirical results demonstrate the effectiveness of the proposed strategy, achieving consistent improvements in multiple experimental settings. In addition, we show that combining our method with back translation can further improve the performance of the model.
Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks
Aug 27, 2019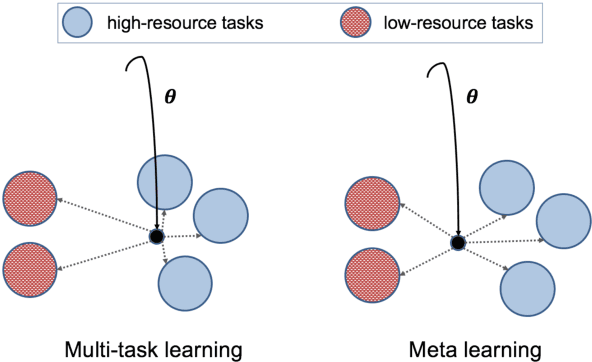
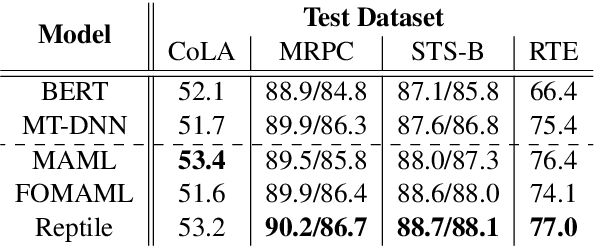
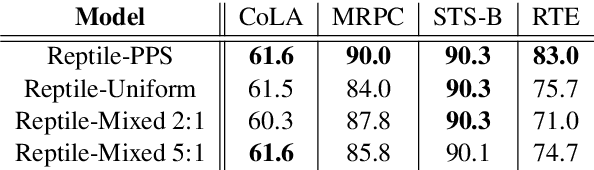
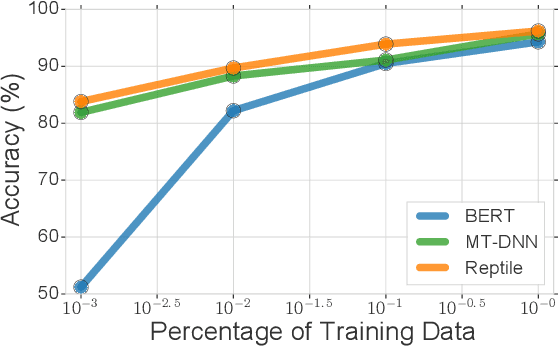
Learning general representations of text is a fundamental problem for many natural language understanding (NLU) tasks. Previously, researchers have proposed to use language model pre-training and multi-task learning to learn robust representations. However, these methods can achieve sub-optimal performance in low-resource scenarios. Inspired by the recent success of optimization-based meta-learning algorithms, in this paper, we explore the model-agnostic meta-learning algorithm (MAML) and its variants for low-resource NLU tasks. We validate our methods on the GLUE benchmark and show that our proposed models can outperform several strong baselines. We further empirically demonstrate that the learned representations can be adapted to new tasks efficiently and effectively.
Information Aggregation for Multi-Head Attention with Routing-by-Agreement
Apr 05, 2019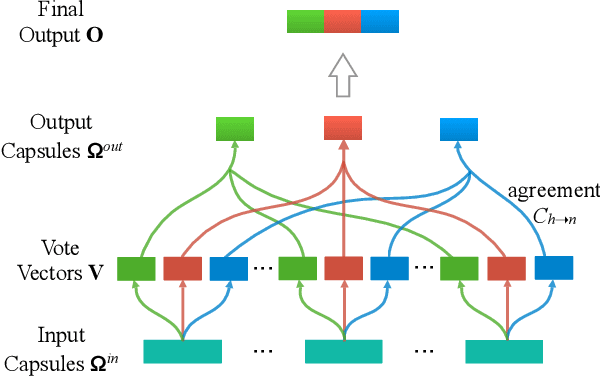

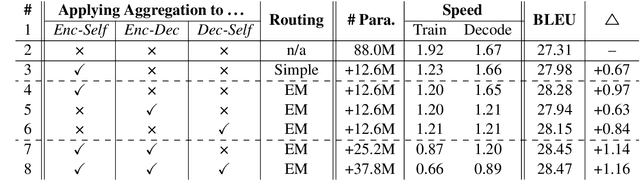
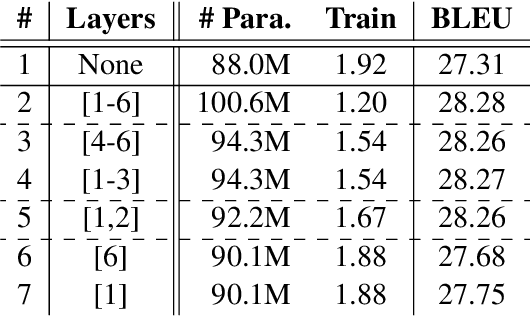
Multi-head attention is appealing for its ability to jointly extract different types of information from multiple representation subspaces. Concerning the information aggregation, a common practice is to use a concatenation followed by a linear transformation, which may not fully exploit the expressiveness of multi-head attention. In this work, we propose to improve the information aggregation for multi-head attention with a more powerful routing-by-agreement algorithm. Specifically, the routing algorithm iteratively updates the proportion of how much a part (i.e. the distinct information learned from a specific subspace) should be assigned to a whole (i.e. the final output representation), based on the agreement between parts and wholes. Experimental results on linguistic probing tasks and machine translation tasks prove the superiority of the advanced information aggregation over the standard linear transformation.