 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Generation with Covariate Time Series
Mar 05, 2026While RAG has greatly enhanced LLMs, extending this paradigm to Time-Series Foundation Models (TSFMs) remains a challenge. This is exemplified in the Predictive Maintenance of the Pressure Regulating and Shut-Off Valve (PRSOV), a high-stakes industrial scenario characterized by (1) data scarcity, (2) short transient sequences, and (3) covariate coupled dynamics. Unfortunately, existing time-series RAG approaches predominantly rely on generated static vector embeddings and learnable context augmenters, which may fail to distinguish similar regimes in such scarce, transient, and covariate coupled scenarios. To address these limitations, we propose RAG4CTS, a regime-aware, training-free RAG framework for Covariate Time-Series. Specifically, we construct a hierarchal time-series native knowledge base to enable lossless storage and physics-informed retrieval of raw historical regimes. We design a two-stage bi-weighted retrieval mechanism that aligns historical trends through point-wise and multivariate similarities. For context augmentation, we introduce an agent-driven strategy to dynamically optimize context in a self-supervised manner. Extensive experiments on PRSOV demonstrate that our framework significantly outperforms state-of-the-art baselines in prediction accuracy. The proposed system is deployed in Apache IoTDB within China Southern Airlines. Since deployment, our method has successfully identified one PRSOV fault in two months with zero false alarm.
Learning Individual Models for Imputation (Technical Report)
Apr 07, 2020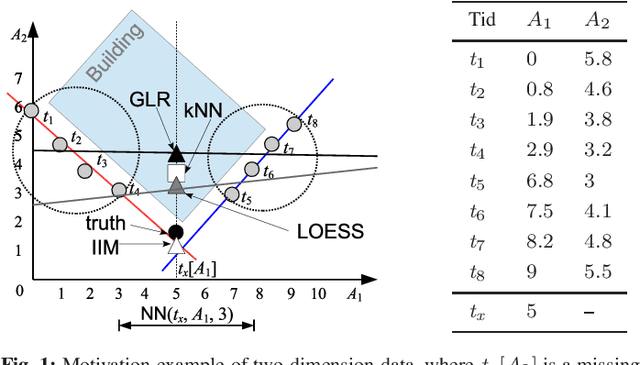
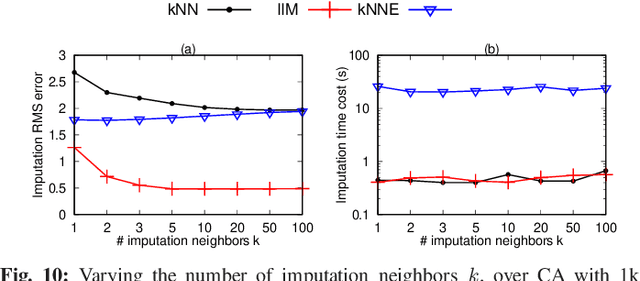
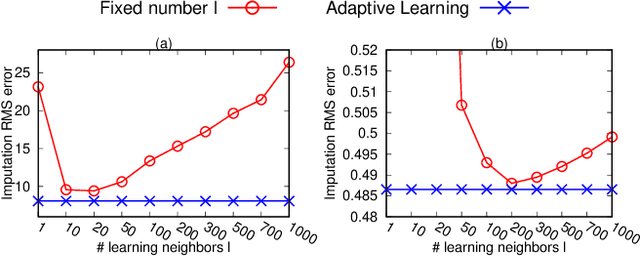
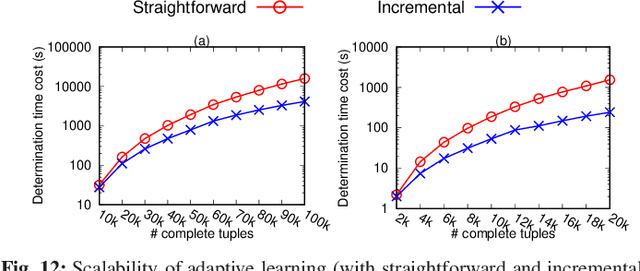
Missing numerical values are prevalent, e.g., owing to unreliable sensor reading, collection and transmission among heterogeneous sources. Unlike categorized data imputation over a limited domain, the numerical values suffer from two issues: (1) sparsity problem, the incomplete tuple may not have sufficient complete neighbors sharing the same/similar values for imputation, owing to the (almost) infinite domain; (2) heterogeneity problem, different tuples may not fit the same (regression) model. In this study, enlightened by the conditional dependencies that hold conditionally over certain tuples rather than the whole relation, we propose to learn a regression model individually for each complete tuple together with its neighbors. Our IIM, Imputation via Individual Models, thus no longer relies on sharing similar values among the k complete neighbors for imputation, but utilizes their regression results by the aforesaid learned individual (not necessary the same) models. Remarkably, we show that some existing methods are indeed special cases of our IIM, under the extreme settings of the number l of learning neighbors considered in individual learning. In this sense, a proper number l of neighbors is essential to learn the individual models (avoid over-fitting or under-fitting). We propose to adaptively learn individual models over various number l of neighbors for different complete tuples. By devising efficient incremental computation, the time complexity of learning a model reduces from linear to constant. Experiments on real data demonstrate that our IIM with adaptive learning achieves higher imputation accuracy than the existing approaches.