 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing Occluders with Compositional Convolutional Networks
Nov 18, 2019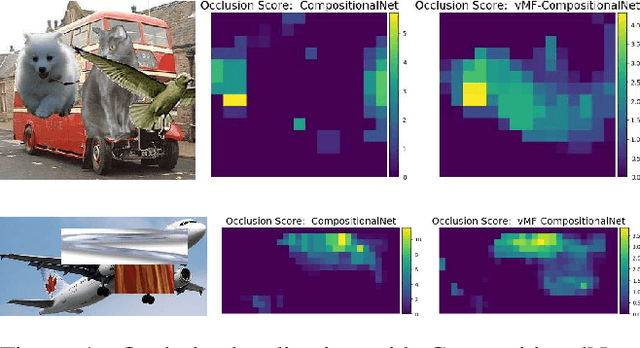

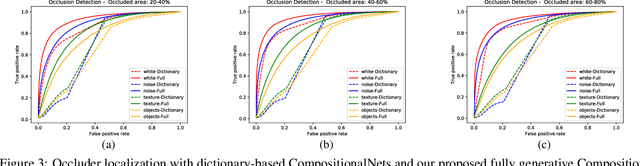
Compositional convolutional networks are generative compositional models of neural network features, that achieve state of the art results when classifying partially occluded objects, even when they have not been exposed to occluded objects during training. In this work, we study the performance of CompositionalNets at localizing occluders in images. We show that the original model is not able to localize occluders well. We propose to overcome this limitation by modeling the feature activations as a mixture of von-Mises-Fisher distributions, which also allows for an end-to-end training of CompositionalNets. Our experimental results demonstrate that the proposed extensions increase the model's performance at localizing occluders as well as at classifying partially occluded objects.
Hyper-Pairing Network for Multi-Phase Pancreatic Ductal Adenocarcinoma Segmentation
Sep 03, 2019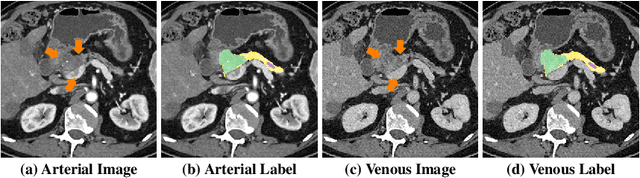
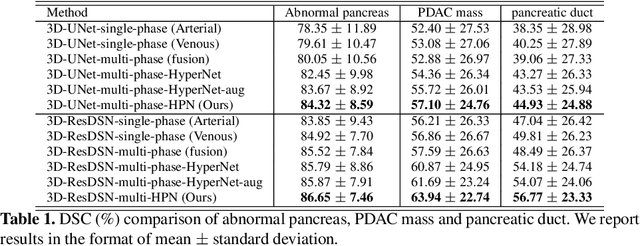
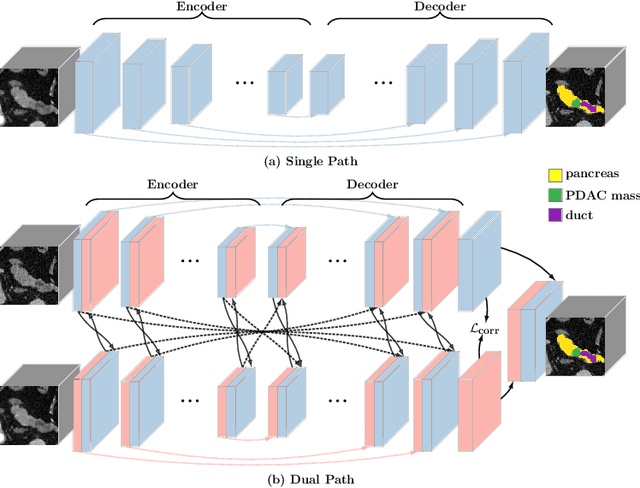
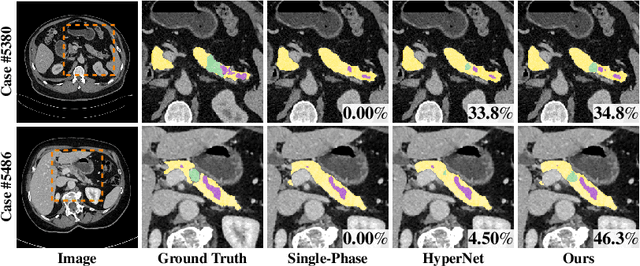
Pancreatic ductal adenocarcinoma (PDAC) is one of the most lethal cancers with an overall five-year survival rate of 8%. Due to subtle texture changes of PDAC, pancreatic dual-phase imaging is recommended for better diagnosis of pancreatic disease. In this study, we aim at enhancing PDAC automatic segmentation by integrating multi-phase information (i.e., arterial phase and venous phase). To this end, we present Hyper-Pairing Network (HPN), a 3D fully convolution neural network which effectively integrates information from different phases. The proposed approach consists of a dual path network where the two parallel streams are interconnected with hyper-connections for intensive information exchange. Additionally, a pairing loss is added to encourage the commonality between high-level feature representations of different phases. Compared to prior arts which use single phase data, HPN reports a significant improvement up to 7.73% (from 56.21% to 63.94%) in terms of DSC.
Multi-Scale Attentional Network for Multi-Focal Segmentation of Active Bleed after Pelvic Fractures
Jun 23, 2019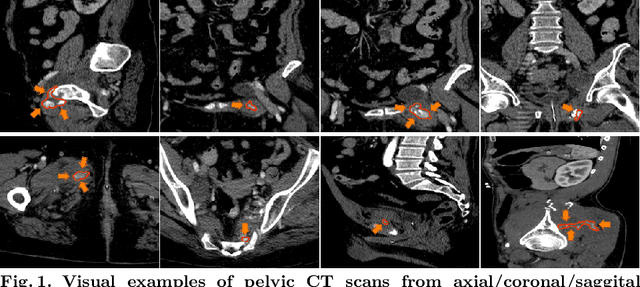
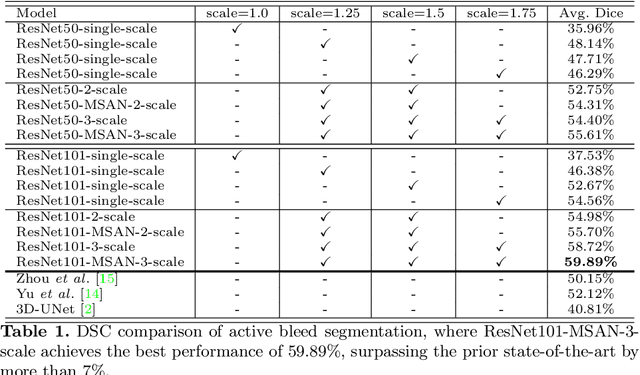
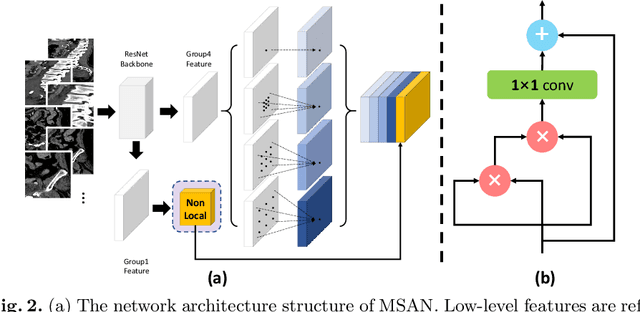
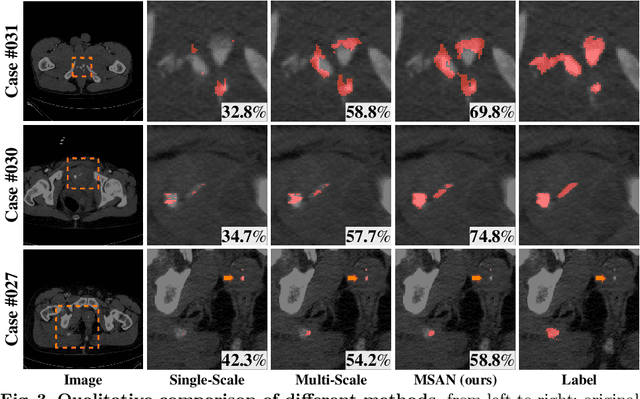
Trauma is the worldwide leading cause of death and disability in those younger than 45 years, and pelvic fractures are a major source of morbidity and mortality. Automated segmentation of multiple foci of arterial bleeding from abdominopelvic trauma CT could provide rapid objective measurements of the total extent of active bleeding, potentially augmenting outcome prediction at the point of care, while improving patient triage, allocation of appropriate resources, and time to definitive intervention. In spite of the importance of active bleeding in the quick tempo of trauma care, the task is still quite challenging due to the variable contrast, intensity, location, size, shape, and multiplicity of bleeding foci. Existing work [4] presents a heuristic rule-based segmentation technique which requires multiple stages and cannot be efficiently optimized end-to-end. To this end, we present, Multi-Scale Attentional Network (MSAN), the first yet reliable end-to-end network, for automated segmentation of active hemorrhage from contrast-enhanced trauma CT scans. MSAN consists of the following components: 1) an encoder which fully integrates the global contextual information from holistic 2D slices; 2) a multi-scale strategy applied both in the training stage and the inference stage to handle the challenges induced by variation of target sizes; 3) an attentional module to further refine the deep features, leading to better segmentation quality; and 4) a multi-view mechanism to fully leverage the 3D information. Our MSAN reports a significant improvement of more than 7% compared to prior arts in terms of DSC.
Compositional Convolutional Networks For Robust Object Classification under Occlusion
May 29, 2019
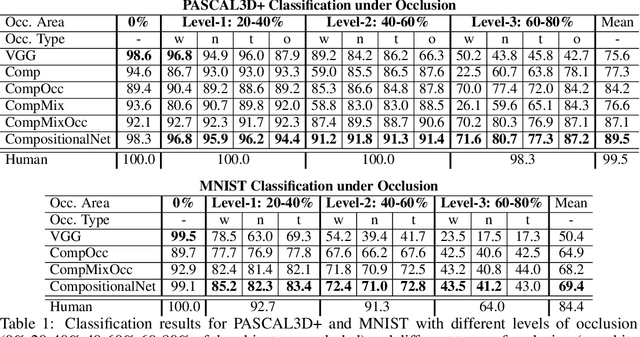
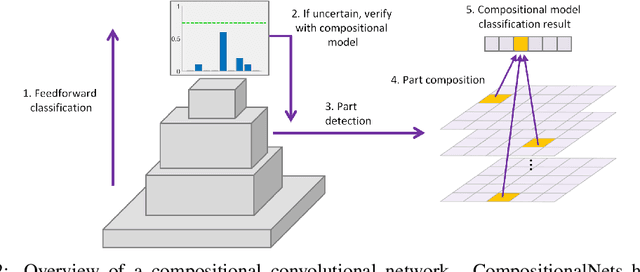
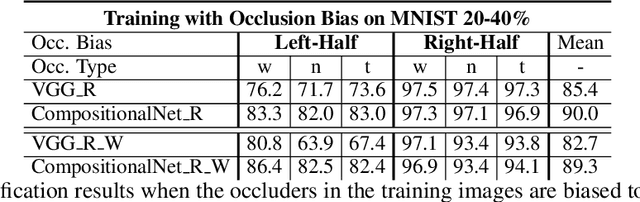
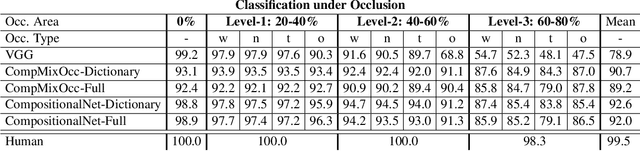
Deep convolutional neural networks (DCNNs) are powerful models that yield impressive results at object classification. However, recent work has shown that they do not generalize well to partially occluded objects and to mask attacks. In contrast to DCNNs, compositional models are robust to partial occlusion, however, they are not as discriminative as deep models. In this work, we integrate DCNNs and compositional object models to retain the best of both approaches: a discriminative model that is robust to partial occlusion and mask attacks. Our model is learned in two steps. First, a standard DCNN is trained for image classification. Subsequently, we cluster the DCNN features into dictionaries. We show that the dictionary components resemble object part detectors and learn the spatial distribution of parts for each object class. We propose mixtures of compositional models to account for large changes in the spatial activation patterns (e.g. due to changes in the 3D pose of an object). At runtime, an image is first classified by the DCNN in a feedforward manner. The prediction uncertainty is used to detect partially occluded objects, which in turn are classified by the compositional model. Our experimental results demonstrate that such compositional convolutional networks resolve a fundamental problem of current deep learning approaches to computer vision: They recognize occluded objects with exceptional performance, even when they have not been exposed to occluded objects during training, while at the same time maintaining high discriminative performance for non-occluded objects.
Learning Transferable Adversarial Examples via Ghost Networks
Dec 09, 2018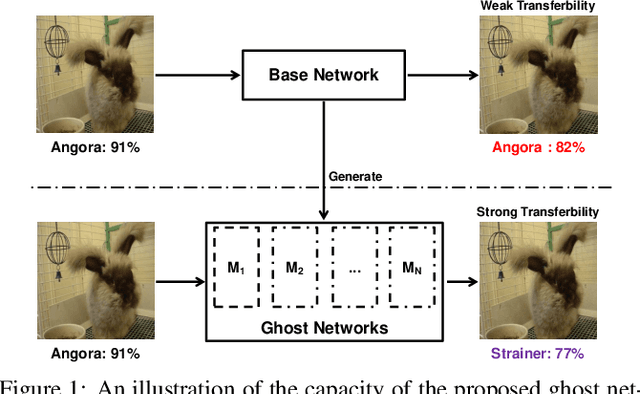


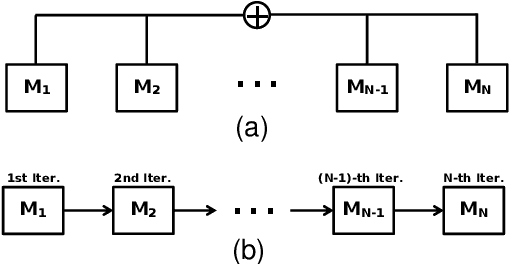
The recent development of adversarial attack has proven that ensemble-based methods can perform black-box attack better than the traditional, non-ensemble ones. However, those methods generally suffer from high complexity. They require a family of diverse models, and ensembling them afterward, both of which are computationally expensive. In this paper, we propose Ghost Networks to efficiently learn transferable adversarial examples. The key principle of ghost networks is to perturb an existing model, which potentially generates a huge set of diverse models. Those models are subsequently fused by longitudinal ensemble. Both steps almost require no extra time and space consumption. Extensive experimental results suggest that the number of networks is essential for improving the transferability of adversarial examples, but it is less necessary to independently train different networks and then ensemble them in an intensive aggregation way. Instead, our work can be a computationally cheap plug-in, which can be easily applied to improve adversarial approaches both in single-model attack and multi-model attack, compatible with both residual and non-residual networks. In particular, by re-producing the NIPS 2017 adversarial competition, our work outperforms the No.1 attack submission by a large margin, which demonstrates its effectiveness and efficiency.
Robust Face Detection via Learning Small Faces on Hard Images
Nov 28, 2018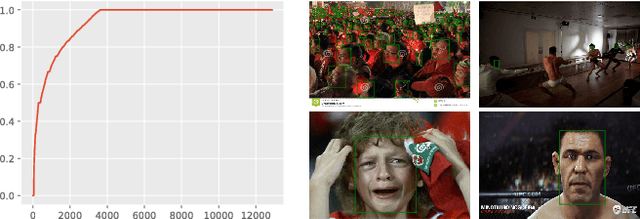
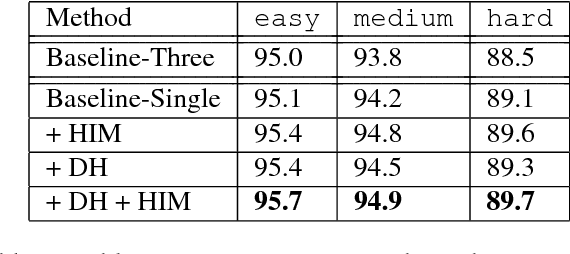
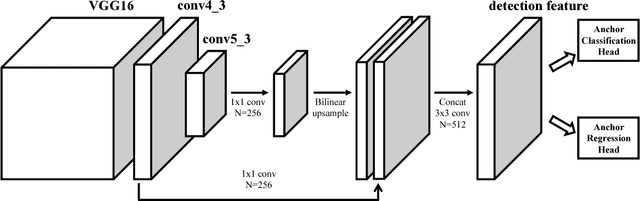
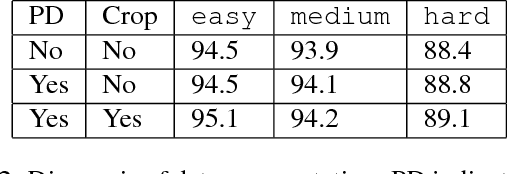
Recent anchor-based deep face detectors have achieved promising performance, but they are still struggling to detect hard faces, such as small, blurred and partially occluded faces. A reason is that they treat all images and faces equally, without putting more effort on hard ones; however, many training images only contain easy faces, which are less helpful to achieve better performance on hard images. In this paper, we propose that the robustness of a face detector against hard faces can be improved by learning small faces on hard images. Our intuitions are (1) hard images are the images which contain at least one hard face, thus they facilitate training robust face detectors; (2) most hard faces are small faces and other types of hard faces can be easily converted to small faces by shrinking. We build an anchor-based deep face detector, which only output a single feature map with small anchors, to specifically learn small faces and train it by a novel hard image mining strategy. Extensive experiments have been conducted on WIDER FACE, FDDB, Pascal Faces, and AFW datasets to show the effectiveness of our method. Our method achieves APs of 95.7, 94.9 and 89.7 on easy, medium and hard WIDER FACE val dataset respectively, which surpass the previous state-of-the-arts, especially on the hard subset. Code and model are available at https://github.com/bairdzhang/smallhardface.
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
Jun 27, 2018CleverHans is a software library that provides standardized reference implementations of adversarial example construction techniques and adversarial training. The library may be used to develop more robust machine learning models and to provide standardized benchmarks of models' performance in the adversarial setting. Benchmarks constructed without a standardized implementation of adversarial example construction are not comparable to each other, because a good result may indicate a robust model or it may merely indicate a weak implementation of the adversarial example construction procedure. This technical report is structured as follows. Section 1 provides an overview of adversarial examples in machine learning and of the CleverHans software. Section 2 presents the core functionalities of the library: namely the attacks based on adversarial examples and defenses to improve the robustness of machine learning models to these attacks. Section 3 describes how to report benchmark results using the library. Section 4 describes the versioning system.
Improving Transferability of Adversarial Examples with Input Diversity
Jun 11, 2018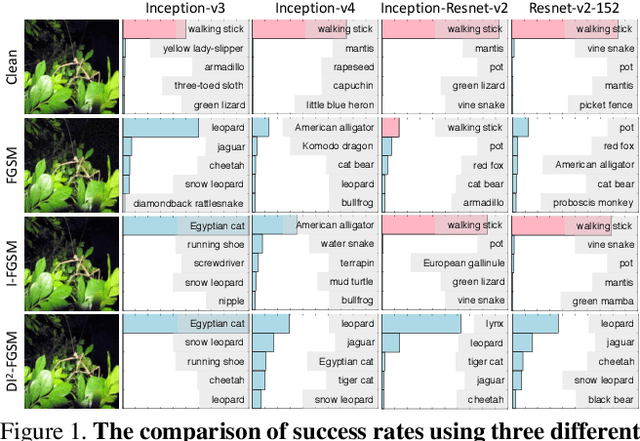
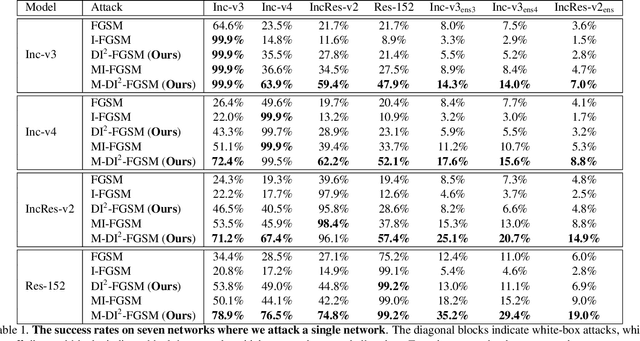
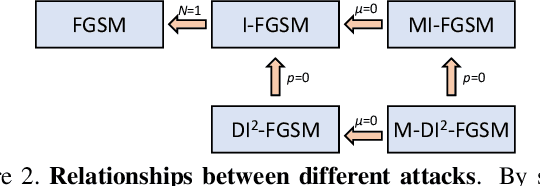

Though convolutional neural networks have achieved state-of-the-art performance on various vision tasks, they are extremely vulnerable to adversarial examples, which are obtained by adding human-imperceptible perturbations to the original images. Adversarial examples can thus be used as an useful tool to evaluate and select the most robust models in safety-critical applications. However, most of the existing adversarial attacks only achieve relatively low success rates under the challenging black-box setting, where the attackers have no knowledge of the model structure and parameters. To this end, we propose to improve the transferability of adversarial examples by creating diverse input patterns. Instead of only using the original images to generate adversarial examples, our method applies random transformations to the input images at each iteration. Extensive experiments on ImageNet show that the proposed attack method can generate adversarial examples that transfer much better to different networks than existing baselines. To further improve the transferability, we (1) integrate the recently proposed momentum method into the attack process; and (2) attack an ensemble of networks simultaneously. By evaluating our method against top defense submissions and official baselines from NIPS 2017 adversarial competition, this enhanced attack reaches an average success rate of 73.0%, which outperforms the top 1 attack submission in the NIPS competition by a large margin of 6.6%. We hope that our proposed attack strategy can serve as a benchmark for evaluating the robustness of networks to adversaries and the effectiveness of different defense methods in future. The code is public available at https://github.com/cihangxie/DI-2-FGSM.
Single-Shot Object Detection with Enriched Semantics
Apr 08, 2018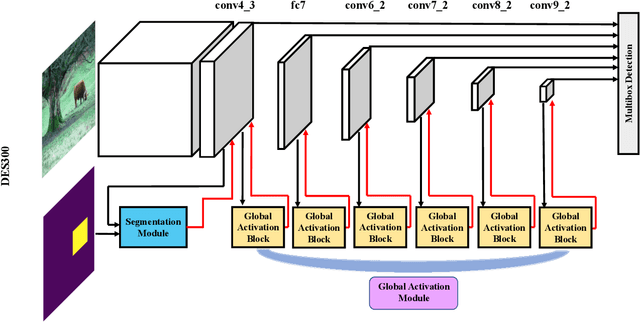
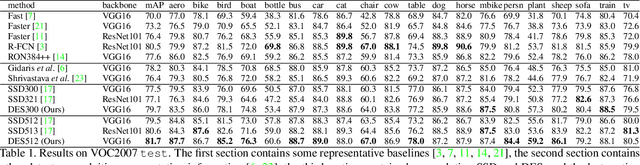
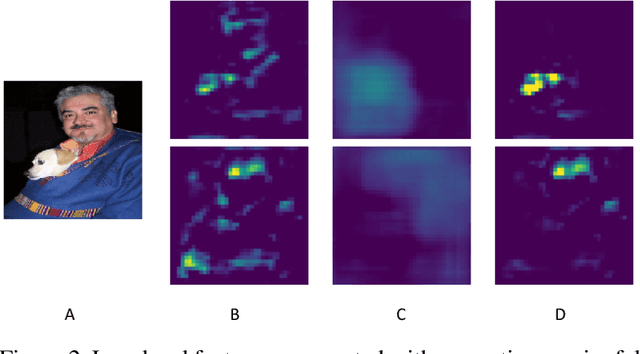
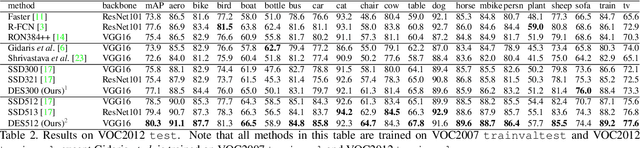
We propose a novel single shot object detection network named Detection with Enriched Semantics (DES). Our motivation is to enrich the semantics of object detection features within a typical deep detector, by a semantic segmentation branch and a global activation module. The segmentation branch is supervised by weak segmentation ground-truth, i.e., no extra annotation is required. In conjunction with that, we employ a global activation module which learns relationship between channels and object classes in a self-supervised manner. Comprehensive experimental results on both PASCAL VOC and MS COCO detection datasets demonstrate the effectiveness of the proposed method. In particular, with a VGG16 based DES, we achieve an mAP of 81.7 on VOC2007 test and an mAP of 32.8 on COCO test-dev with an inference speed of 31.5 milliseconds per image on a Titan Xp GPU. With a lower resolution version, we achieve an mAP of 79.7 on VOC2007 with an inference speed of 13.0 milliseconds per image.
Adversarial Attacks and Defences Competition
Mar 31, 2018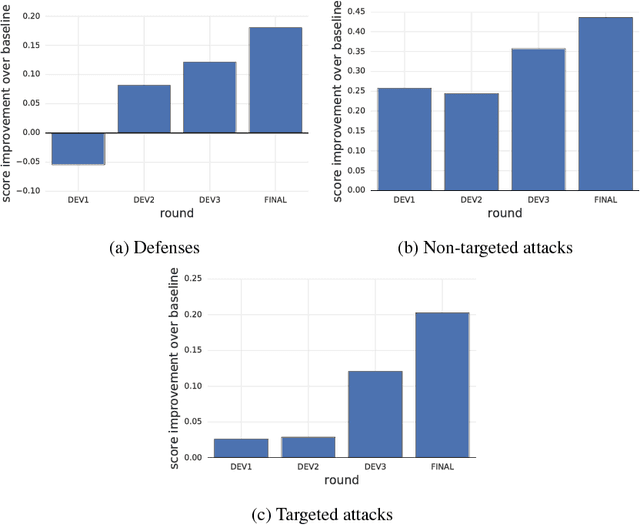
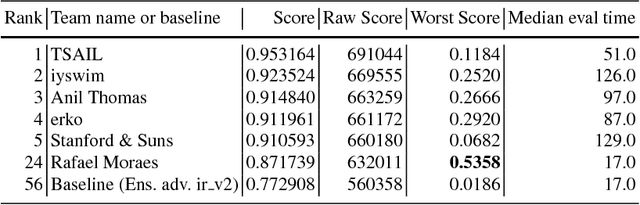
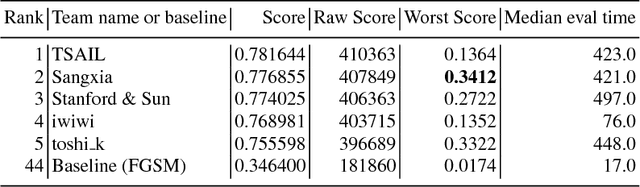
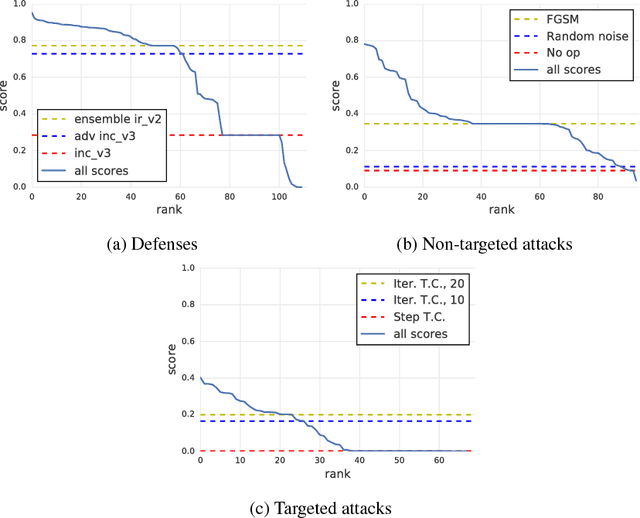
To accelerate research on adversarial examples and robustness of machine learning classifiers, Google Brain organized a NIPS 2017 competition that encouraged researchers to develop new methods to generate adversarial examples as well as to develop new ways to defend against them. In this chapter, we describe the structure and organization of the competition and the solutions developed by several of the top-placing teams.