 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Point: Exploring Point-Language Models for Zero-Shot 3D Anomaly Detection
Mar 23, 2026Zero-shot (ZS) 3D anomaly detection is crucial for reliable industrial inspection, as it enables detecting and localizing defects without requiring any target-category training data. Existing approaches render 3D point clouds into 2D images and leverage pre-trained Vision-Language Models (VLMs) for anomaly detection. However, such strategies inevitably discard geometric details and exhibit limited sensitivity to local anomalies. In this paper, we revisit intrinsic 3D representations and explore the potential of pre-trained Point-Language Models (PLMs) for ZS 3D anomaly detection. We propose BTP (Back To Point), a novel framework that effectively aligns 3D point cloud and textual embeddings. Specifically, BTP aligns multi-granularity patch features with textual representations for localized anomaly detection, while incorporating geometric descriptors to enhance sensitivity to structural anomalies. Furthermore, we introduce a joint representation learning strategy that leverages auxiliary point cloud data to improve robustness and enrich anomaly semantics. Extensive experiments on Real3D-AD and Anomaly-ShapeNet demonstrate that BTP achieves superior performance in ZS 3D anomaly detection. Code will be available at \href{https://github.com/wistful-8029/BTP-3DAD}{https://github.com/wistful-8029/BTP-3DAD}.
Exploring Multimodal Prompts For Unsupervised Continuous Anomaly Detection
Mar 23, 2026Unsupervised Continuous Anomaly Detection (UCAD) is gaining attention for effectively addressing the catastrophic forgetting and heavy computational burden issues in traditional Unsupervised Anomaly Detection (UAD). However, existing UCAD approaches that rely solely on visual information are insufficient to capture the manifold of normality in complex scenes, thereby impeding further gains in anomaly detection accuracy. To overcome this limitation, we propose an unsupervised continual anomaly detection framework grounded in multimodal prompting. Specifically, we introduce a Continual Multimodal Prompt Memory Bank (CMPMB) that progressively distills and retains prototypical normal patterns from both visual and textual domains across consecutive tasks, yielding a richer representation of normality. Furthermore, we devise a Defect-Semantic-Guided Adaptive Fusion Mechanism (DSG-AFM) that integrates an Adaptive Normalization Module (ANM) with a Dynamic Fusion Strategy (DFS) to jointly enhance detection accuracy and adversarial robustness. Benchmark experiments on MVTec AD and VisA datasets show that our approach achieves state-of-the-art (SOTA) performance on image-level AUROC and pixel-level AUPR metrics.
Graph of Verification: Structured Verification of LLM Reasoning with Directed Acyclic Graphs
Jun 14, 2025



Verifying the reliability of complex, multi-step reasoning in Large Language Models (LLMs) remains a fundamental challenge, as existing methods often lack both faithfulness and precision. To address this issue, we propose the Graph of Verification (GoV) framework. GoV offers three key contributions: First, it explicitly models the underlying deductive process as a directed acyclic graph (DAG), whether this structure is implicit or explicitly constructed. Second, it enforces a topological order over the DAG to guide stepwise verification. Third, GoV introduces the notion of customizable node blocks, which flexibly define the verification granularity, from atomic propositions to full paragraphs, while ensuring that all requisite premises derived from the graph are provided as contextual input for each verification unit. We evaluate GoV on the Number Triangle Summation task and the ProcessBench benchmark with varying levels of reasoning complexity. Experimental results show that GoV substantially improves verification accuracy, faithfulness, and error localization when compared to conventional end-to-end verification approaches. Our code and data are available at https://github.com/Frevor/Graph-of-Verification.
CRFormer: A Cross-Region Transformer for Shadow Removal
Jul 04, 2022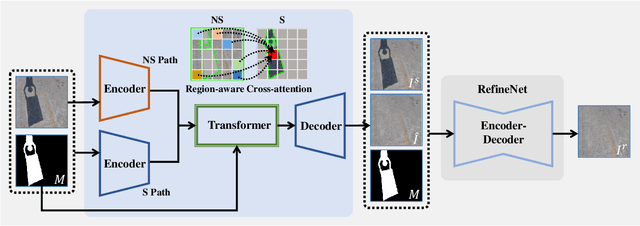
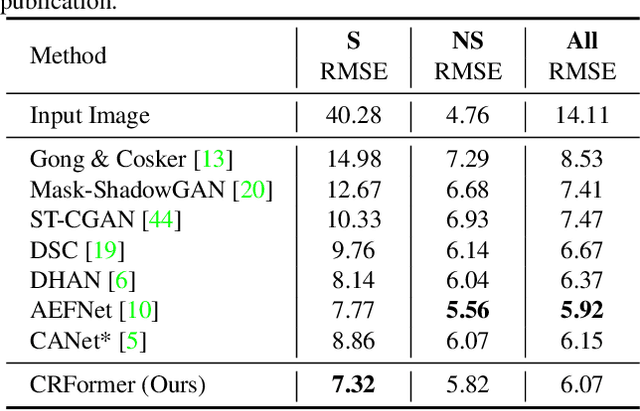
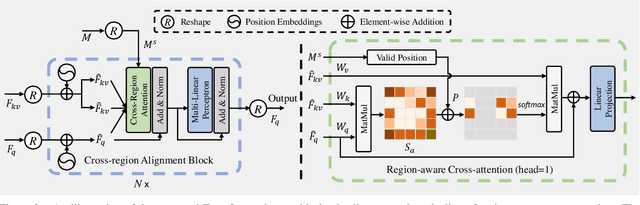
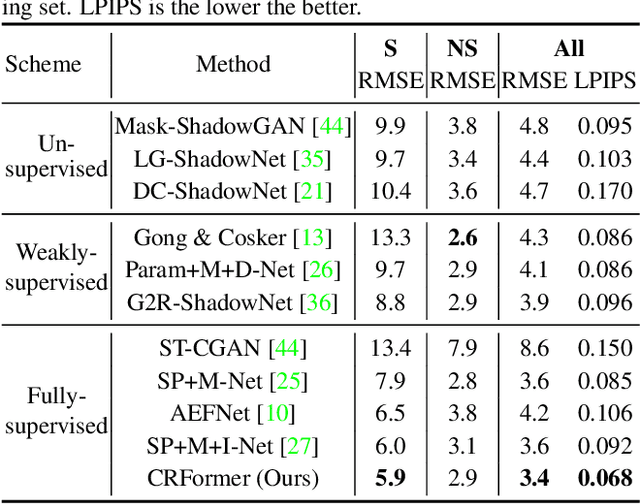
Aiming to restore the original intensity of shadow regions in an image and make them compatible with the remaining non-shadow regions without a trace, shadow removal is a very challenging problem that benefits many downstream image/video-related tasks. Recently, transformers have shown their strong capability in various applications by capturing global pixel interactions and this capability is highly desirable in shadow removal. However, applying transformers to promote shadow removal is non-trivial for the following two reasons: 1) The patchify operation is not suitable for shadow removal due to irregular shadow shapes; 2) shadow removal only needs one-way interaction from the non-shadow region to the shadow region instead of the common two-way interactions among all pixels in the image. In this paper, we propose a novel cross-region transformer, namely CRFormer, for shadow removal which differs from existing transformers by only considering the pixel interactions from the non-shadow region to the shadow region without splitting images into patches. This is achieved by a carefully designed region-aware cross-attention operation that can aggregate the recovered shadow region features conditioned on the non-shadow region features. Extensive experiments on ISTD, AISTD, SRD, and Video Shadow Removal datasets demonstrate the superiority of our method compared to other state-of-the-art methods.