 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Visual Prompt Learning for Continual Video Instance Segmentation
Aug 12, 2025
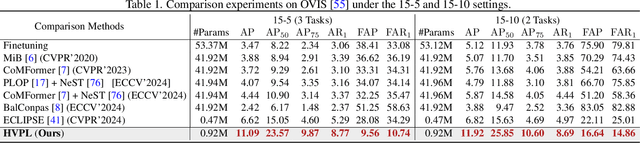


Video instance segmentation (VIS) has gained significant attention for its capability in tracking and segmenting object instances across video frames. However, most of the existing VIS approaches unrealistically assume that the categories of object instances remain fixed over time. Moreover, they experience catastrophic forgetting of old classes when required to continuously learn object instances belonging to new categories. To resolve these challenges, we develop a novel Hierarchical Visual Prompt Learning (HVPL) model that overcomes catastrophic forgetting of previous categories from both frame-level and video-level perspectives. Specifically, to mitigate forgetting at the frame level, we devise a task-specific frame prompt and an orthogonal gradient correction (OGC) module. The OGC module helps the frame prompt encode task-specific global instance information for new classes in each individual frame by projecting its gradients onto the orthogonal feature space of old classes. Furthermore, to address forgetting at the video level, we design a task-specific video prompt and a video context decoder. This decoder first embeds structural inter-class relationships across frames into the frame prompt features, and then propagates task-specific global video contexts from the frame prompt features to the video prompt. Through rigorous comparisons, our HVPL model proves to be more effective than baseline approaches. The code is available at https://github.com/JiahuaDong/HVPL.
From EMR Data to Clinical Insight: An LLM-Driven Framework for Automated Pre-Consultation Questionnaire Generation
Aug 01, 2025



Pre-consultation is a critical component of effective healthcare delivery. However, generating comprehensive pre-consultation questionnaires from complex, voluminous Electronic Medical Records (EMRs) is a challenging task. Direct Large Language Model (LLM) approaches face difficulties in this task, particularly regarding information completeness, logical order, and disease-level synthesis. To address this issue, we propose a novel multi-stage LLM-driven framework: Stage 1 extracts atomic assertions (key facts with timing) from EMRs; Stage 2 constructs personal causal networks and synthesizes disease knowledge by clustering representative networks from an EMR corpus; Stage 3 generates tailored personal and standardized disease-specific questionnaires based on these structured representations. This framework overcomes limitations of direct methods by building explicit clinical knowledge. Evaluated on a real-world EMR dataset and validated by clinical experts, our method demonstrates superior performance in information coverage, diagnostic relevance, understandability, and generation time, highlighting its practical potential to enhance patient information collection.
Combining Knowledge Graphs and Large Language Models
Jul 09, 2024



In recent years, Natural Language Processing (NLP) has played a significant role in various Artificial Intelligence (AI) applications such as chatbots, text generation, and language translation. The emergence of large language models (LLMs) has greatly improved the performance of these applications, showing astonishing results in language understanding and generation. However, they still show some disadvantages, such as hallucinations and lack of domain-specific knowledge, that affect their performance in real-world tasks. These issues can be effectively mitigated by incorporating knowledge graphs (KGs), which organise information in structured formats that capture relationships between entities in a versatile and interpretable fashion. Likewise, the construction and validation of KGs present challenges that LLMs can help resolve. The complementary relationship between LLMs and KGs has led to a trend that combines these technologies to achieve trustworthy results. This work collected 28 papers outlining methods for KG-powered LLMs, LLM-based KGs, and LLM-KG hybrid approaches. We systematically analysed and compared these approaches to provide a comprehensive overview highlighting key trends, innovative techniques, and common challenges. This synthesis will benefit researchers new to the field and those seeking to deepen their understanding of how KGs and LLMs can be effectively combined to enhance AI applications capabilities.
Dual Hyperspectral Mamba for Efficient Spectral Compressive Imaging
Jun 01, 2024



Deep unfolding methods have made impressive progress in restoring 3D hyperspectral images (HSIs) from 2D measurements through convolution neural networks or Transformers in spectral compressive imaging. However, they cannot efficiently capture long-range dependencies using global receptive fields, which significantly limits their performance in HSI reconstruction. Moreover, these methods may suffer from local context neglect if we directly utilize Mamba to unfold a 2D feature map as a 1D sequence for modeling global long-range dependencies. To address these challenges, we propose a novel Dual Hyperspectral Mamba (DHM) to explore both global long-range dependencies and local contexts for efficient HSI reconstruction. After learning informative parameters to estimate degradation patterns of the CASSI system, we use them to scale the linear projection and offer noise level for the denoiser (i.e., our proposed DHM). Specifically, our DHM consists of multiple dual hyperspectral S4 blocks (DHSBs) to restore original HSIs. Particularly, each DHSB contains a global hyperspectral S4 block (GHSB) to model long-range dependencies across the entire high-resolution HSIs using global receptive fields, and a local hyperspectral S4 block (LHSB) to address local context neglect by establishing structured state-space sequence (S4) models within local windows. Experiments verify the benefits of our DHM for HSI reconstruction. The source codes and models will be available at https://github.com/JiahuaDong/DHM.
A Rapid Review of Clustering Algorithms
Jan 14, 2024Clustering algorithms aim to organize data into groups or clusters based on the inherent patterns and similarities within the data. They play an important role in today's life, such as in marketing and e-commerce, healthcare, data organization and analysis, and social media. Numerous clustering algorithms exist, with ongoing developments introducing new ones. Each algorithm possesses its own set of strengths and weaknesses, and as of now, there is no universally applicable algorithm for all tasks. In this work, we analyzed existing clustering algorithms and classify mainstream algorithms across five different dimensions: underlying principles and characteristics, data point assignment to clusters, dataset capacity, predefined cluster numbers and application area. This classification facilitates researchers in understanding clustering algorithms from various perspectives and helps them identify algorithms suitable for solving specific tasks. Finally, we discussed the current trends and potential future directions in clustering algorithms. We also identified and discussed open challenges and unresolved issues in the field.
Leveraging Artificial Intelligence Technology for Mapping Research to Sustainable Development Goals: A Case Study
Nov 09, 2023



The number of publications related to the Sustainable Development Goals (SDGs) continues to grow. These publications cover a diverse spectrum of research, from humanities and social sciences to engineering and health. Given the imperative of funding bodies to monitor outcomes and impacts, linking publications to relevant SDGs is critical but remains time-consuming and difficult given the breadth and complexity of the SDGs. A publication may relate to several goals (interconnection feature of goals), and therefore require multidisciplinary knowledge to tag accurately. Machine learning approaches are promising and have proven particularly valuable for tasks such as manual data labeling and text classification. In this study, we employed over 82,000 publications from an Australian university as a case study. We utilized a similarity measure to map these publications onto Sustainable Development Goals (SDGs). Additionally, we leveraged the OpenAI GPT model to conduct the same task, facilitating a comparative analysis between the two approaches. Experimental results show that about 82.89% of the results obtained by the similarity measure overlap (at least one tag) with the outputs of the GPT model. The adopted model (similarity measure) can complement GPT model for SDG classification. Furthermore, deep learning methods, which include the similarity measure used here, are more accessible and trusted for dealing with sensitive data without the use of commercial AI services or the deployment of expensive computing resources to operate large language models. Our study demonstrates how a crafted combination of the two methods can achieve reliable results for mapping research to the SDGs.
CRFormer: A Cross-Region Transformer for Shadow Removal
Jul 04, 2022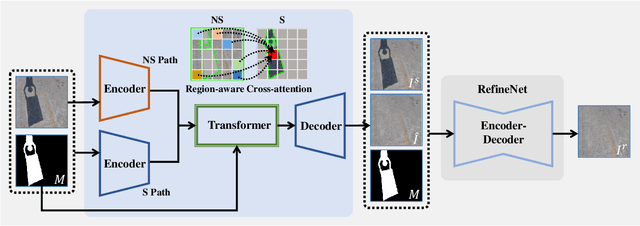
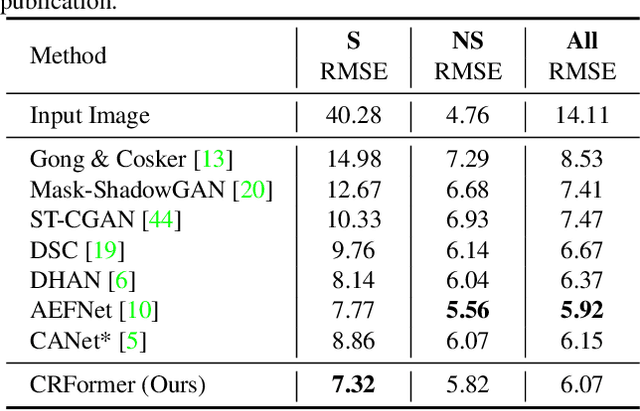
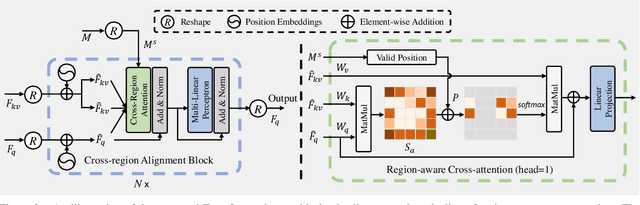
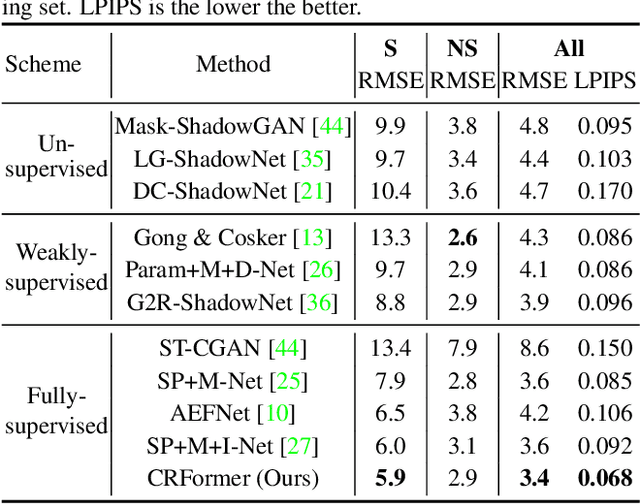
Aiming to restore the original intensity of shadow regions in an image and make them compatible with the remaining non-shadow regions without a trace, shadow removal is a very challenging problem that benefits many downstream image/video-related tasks. Recently, transformers have shown their strong capability in various applications by capturing global pixel interactions and this capability is highly desirable in shadow removal. However, applying transformers to promote shadow removal is non-trivial for the following two reasons: 1) The patchify operation is not suitable for shadow removal due to irregular shadow shapes; 2) shadow removal only needs one-way interaction from the non-shadow region to the shadow region instead of the common two-way interactions among all pixels in the image. In this paper, we propose a novel cross-region transformer, namely CRFormer, for shadow removal which differs from existing transformers by only considering the pixel interactions from the non-shadow region to the shadow region without splitting images into patches. This is achieved by a carefully designed region-aware cross-attention operation that can aggregate the recovered shadow region features conditioned on the non-shadow region features. Extensive experiments on ISTD, AISTD, SRD, and Video Shadow Removal datasets demonstrate the superiority of our method compared to other state-of-the-art methods.
Representation Learning for Short Text Clustering
Sep 21, 2021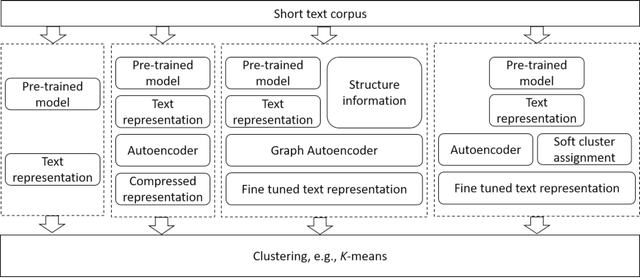
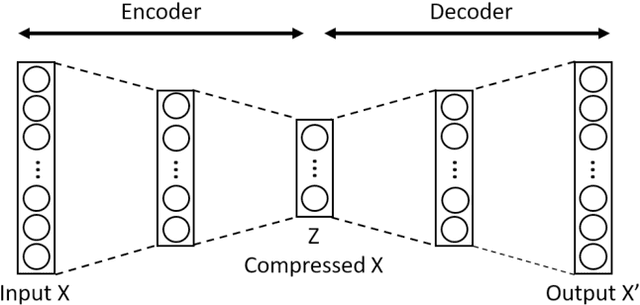
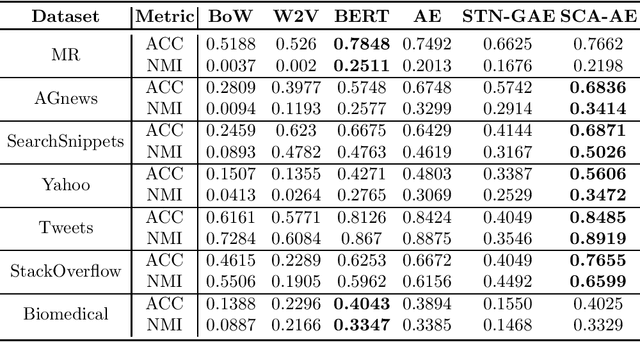
Effective representation learning is critical for short text clustering due to the sparse, high-dimensional and noise attributes of short text corpus. Existing pre-trained models (e.g., Word2vec and BERT) have greatly improved the expressiveness for short text representations with more condensed, low-dimensional and continuous features compared to the traditional Bag-of-Words (BoW) model. However, these models are trained for general purposes and thus are suboptimal for the short text clustering task. In this paper, we propose two methods to exploit the unsupervised autoencoder (AE) framework to further tune the short text representations based on these pre-trained text models for optimal clustering performance. In our first method Structural Text Network Graph Autoencoder (STN-GAE), we exploit the structural text information among the corpus by constructing a text network, and then adopt graph convolutional network as encoder to fuse the structural features with the pre-trained text features for text representation learning. In our second method Soft Cluster Assignment Autoencoder (SCA-AE), we adopt an extra soft cluster assignment constraint on the latent space of autoencoder to encourage the learned text representations to be more clustering-friendly. We tested two methods on seven popular short text datasets, and the experimental results show that when only using the pre-trained model for short text clustering, BERT performs better than BoW and Word2vec. However, as long as we further tune the pre-trained representations, the proposed method like SCA-AE can greatly increase the clustering performance, and the accuracy improvement compared to use BERT alone could reach as much as 14\%.
From Shadow Generation to Shadow Removal
Mar 24, 2021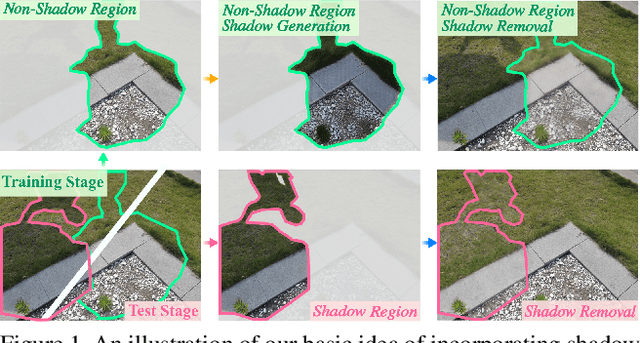
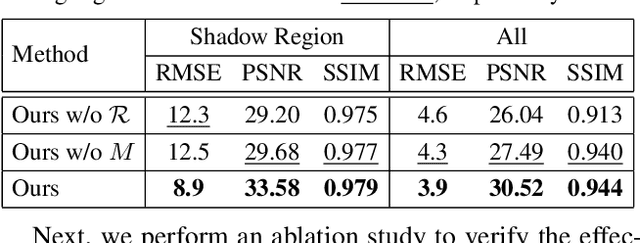
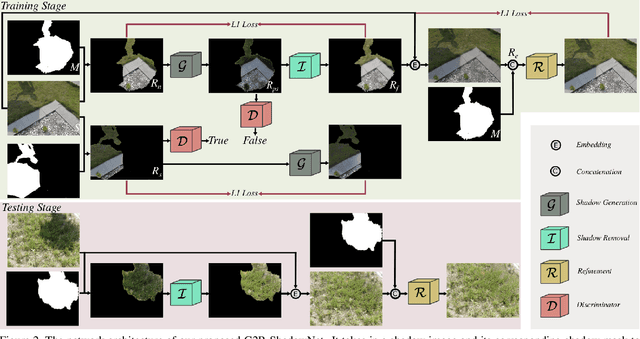
Shadow removal is a computer-vision task that aims to restore the image content in shadow regions. While almost all recent shadow-removal methods require shadow-free images for training, in ECCV 2020 Le and Samaras introduces an innovative approach without this requirement by cropping patches with and without shadows from shadow images as training samples. However, it is still laborious and time-consuming to construct a large amount of such unpaired patches. In this paper, we propose a new G2R-ShadowNet which leverages shadow generation for weakly-supervised shadow removal by only using a set of shadow images and their corresponding shadow masks for training. The proposed G2R-ShadowNet consists of three sub-networks for shadow generation, shadow removal and refinement, respectively and they are jointly trained in an end-to-end fashion. In particular, the shadow generation sub-net stylises non-shadow regions to be shadow ones, leading to paired data for training the shadow-removal sub-net. Extensive experiments on the ISTD dataset and the Video Shadow Removal dataset show that the proposed G2R-ShadowNet achieves competitive performances against the current state of the arts and outperforms Le and Samaras' patch-based shadow-removal method.
Shadow Removal by a Lightness-Guided Network with Training on Unpaired Data
Jun 28, 2020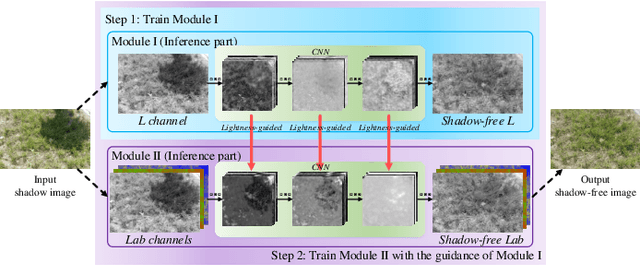
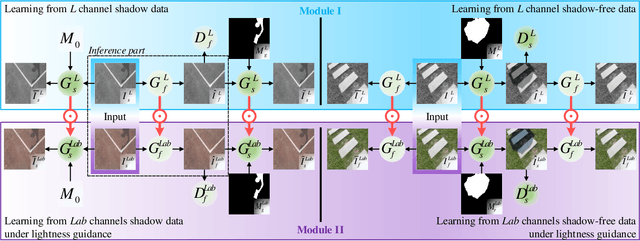
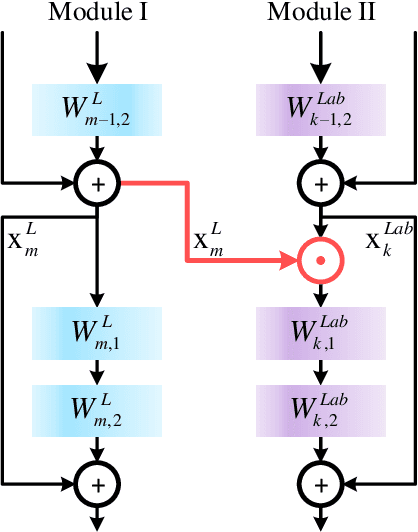
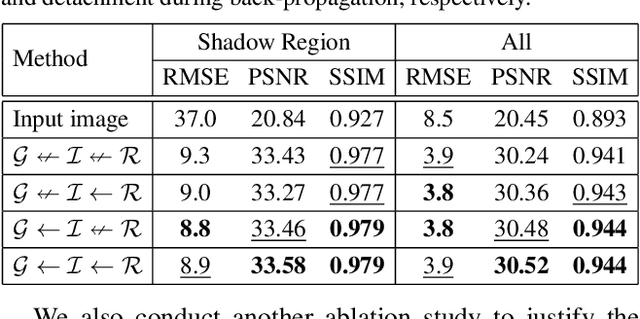
Shadow removal can significantly improve the image visual quality and has many applications in computer vision. Deep learning methods based on CNNs have become the most effective approach for shadow removal by training on either paired data, where both the shadow and underlying shadow-free versions of an image are known, or unpaired data, where shadow and shadow-free training images are totally different with no correspondence. In practice, CNN training on unpaired data is more preferred given the easiness of training data collection. In this paper, we present a new Lightness-Guided Shadow Removal Network (LG-ShadowNet) for shadow removal by training on unpaired data. In this method, we first train a CNN module to compensate for the lightness and then train a second CNN module with the guidance of lightness information from the first CNN module for final shadow removal. We also introduce a loss function to further utilise the colour prior of existing data. Extensive experiments on widely used ISTD, adjusted ISTD and USR datasets demonstrate that the proposed method outperforms the state-of-the-art methods with training on unpaired data.