 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging What the Model Thinks and How It Speaks: Self-Aware Speech Language Models for Expressive Speech Generation
Apr 13, 2026Speech Language Models (SLMs) exhibit strong semantic understanding, yet their generated speech often sounds flat and fails to convey expressive intent, undermining user engagement. We term this mismatch the semantic understanding-acoustic realization gap. We attribute this gap to two key deficiencies: (1) intent transmission failure, where SLMs fail to provide the stable utterance-level intent needed for expressive delivery; and (2) realization-unaware training, where no feedback signal verifies whether acoustic outputs faithfully reflect intended expression. To address these issues, we propose SA-SLM (Self-Aware Speech Language Model), built on the principle that the model should be aware of what it thinks during generation and how it speaks during training. SA-SLM addresses this gap through two core contributions: (1) Intent-Aware Bridging, which uses a Variational Information Bottleneck (VIB) objective to translate the model's internal semantics into temporally smooth expressive intent, making speech generation aware of what the model intends to express; and (2) Realization-Aware Alignment, which repurposes the model as its own critic to verify and align acoustic realization with intended expressive intent via rubric-based feedback. Trained on only 800 hours of expressive speech data, our 3B parameter SA-SLM surpasses all open-source baselines and comes within 0.08 points of GPT-4o-Audio in overall expressiveness on the EchoMind benchmark.
Automatic Recognition of Landmarks on Digital Dental Models
Dec 23, 2020
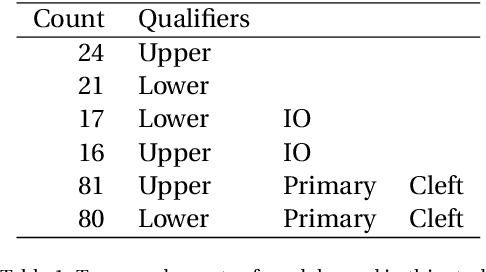
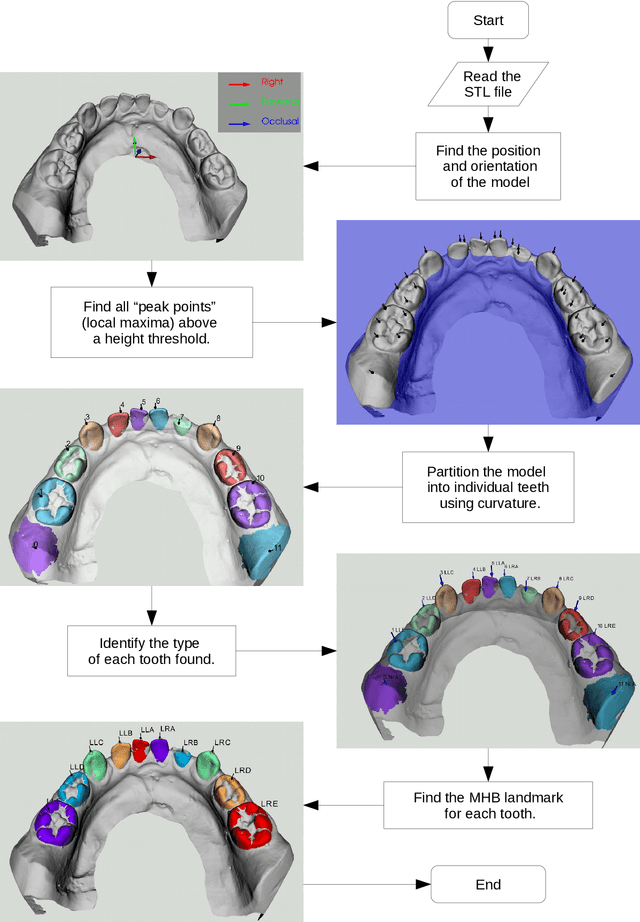
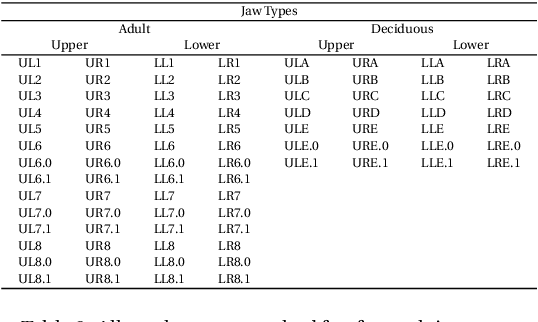
Fundamental to improving Dental and Orthodontic treatments is the ability to quantitatively assess and cross-compare their outcomes. Such assessments require calculating distances and angles from 3D coordinates of dental landmarks. The costly and repetitive task of hand-labelling dental models impedes studies requiring large sample size to penetrate statistical noise. We have developed techniques and software implementing these techniques to map out automatically, 3D dental scans. This process is divided into consecutive steps - determining a model's orientation, separating and identifying the individual tooth and finding landmarks on each tooth - described in this paper. Examples to demonstrate techniques and the software and discussions on remaining issues are provided as well. The software is originally designed to automate Modified Huddard Bodemham (MHB) landmarking for assessing cleft lip/palate patients. Currently only MHB landmarks are supported, but is extendable to any predetermined landmarks. This software, coupled with intra-oral scanning innovation, should supersede the arduous and error prone plaster model and caliper approach to Dental research and provide a stepping-stone towards automation of routine clinical assessments such as "index of orthodontic treatment need" (IOTN).
Generative Adversarial Network with Multi-Branch Discriminator for Cross-Species Image-to-Image Translation
Jan 24, 2019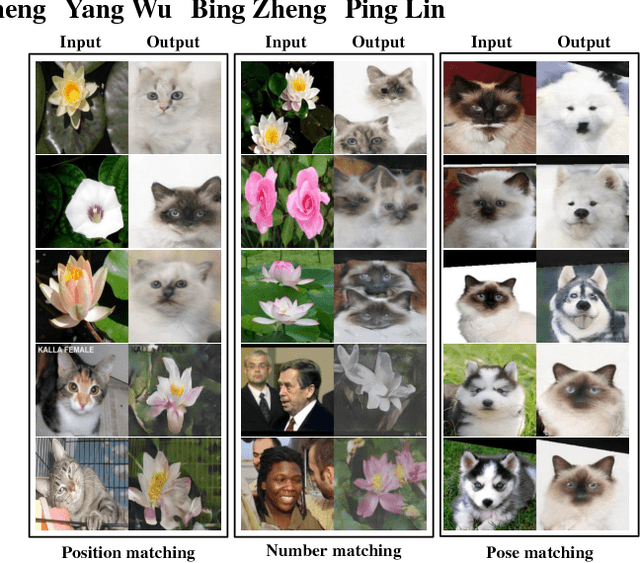
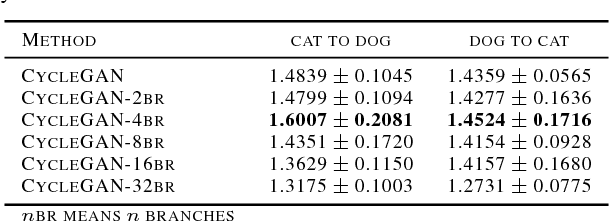
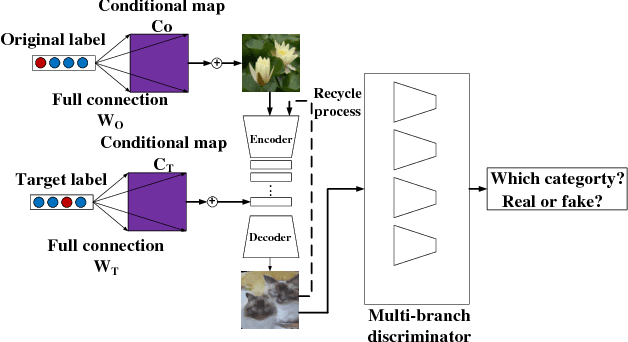

Current approaches have made great progress on image-to-image translation tasks benefiting from the success of image synthesis methods especially generative adversarial networks (GANs). However, existing methods are limited to handling translation tasks between two species while keeping the content matching on the semantic level. A more challenging task would be the translation among more than two species. To explore this new area, we propose a simple yet effective structure of a multi-branch discriminator for enhancing an arbitrary generative adversarial architecture (GAN), named GAN-MBD. It takes advantage of the boosting strategy to break a common discriminator into several smaller ones with fewer parameters, which can enhance the generation and synthesis abilities of GANs efficiently and effectively. Comprehensive experiments show that the proposed multi-branch discriminator can dramatically improve the performance of popular GANs on cross-species image-to-image translation tasks while reducing the number of parameters for computation. The code and some datasets are attached as supplementary materials for reference.