 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3D-Stereo: A Multiple-Medium and Multiple-Degradation Dataset for Stereo Image Restoration
Apr 14, 2026Image restoration under adverse conditions, such as underwater, haze or fog, and low-light environments, remains a highly challenging problem due to complex physical degradations and severe information loss. Existing datasets are predominantly limited to a single degradation type or heavily rely on synthetic data without stereo consistency, inherently restricting their applicability in real-world scenarios. To address this, we introduce M3D-Stereo, a stereo dataset with 7904 high-resolution image pairs for image restoration research acquired in multiple media with multiple controlled degradation levels. It encompasses four degradation scenarios: underwater scatter, haze/fog, underwater low-light, and haze low-light. Each scenario forms a subset, and is divided into six levels of progressive degradation, allowing fine-grained evaluations of restoration methods with increasing severity of degradation. Collected via a laboratory setup, the dataset provides aligned stereo image pairs along with their pixel-wise consistent clear ground truths. Two restoration tasks, single-level and mixed-level degradation, were performed to verify its validity. M3D-Stereo establishes a better controlled and more realistic benchmark to evaluate image restoration and stereo matching methods in complex degradation environments. It is made public under LGPLv3 license.
TS-Diff: Two-Stage Diffusion Model for Low-Light RAW Image Enhancement
May 07, 2025This paper presents a novel Two-Stage Diffusion Model (TS-Diff) for enhancing extremely low-light RAW images. In the pre-training stage, TS-Diff synthesizes noisy images by constructing multiple virtual cameras based on a noise space. Camera Feature Integration (CFI) modules are then designed to enable the model to learn generalizable features across diverse virtual cameras. During the aligning stage, CFIs are averaged to create a target-specific CFI$^T$, which is fine-tuned using a small amount of real RAW data to adapt to the noise characteristics of specific cameras. A structural reparameterization technique further simplifies CFI$^T$ for efficient deployment. To address color shifts during the diffusion process, a color corrector is introduced to ensure color consistency by dynamically adjusting global color distributions. Additionally, a novel dataset, QID, is constructed, featuring quantifiable illumination levels and a wide dynamic range, providing a comprehensive benchmark for training and evaluation under extreme low-light conditions. Experimental results demonstrate that TS-Diff achieves state-of-the-art performance on multiple datasets, including QID, SID, and ELD, excelling in denoising, generalization, and color consistency across various cameras and illumination levels. These findings highlight the robustness and versatility of TS-Diff, making it a practical solution for low-light imaging applications. Source codes and models are available at https://github.com/CircccleK/TS-Diff
HDiffTG: A Lightweight Hybrid Diffusion-Transformer-GCN Architecture for 3D Human Pose Estimation
May 07, 2025We propose HDiffTG, a novel 3D Human Pose Estimation (3DHPE) method that integrates Transformer, Graph Convolutional Network (GCN), and diffusion model into a unified framework. HDiffTG leverages the strengths of these techniques to significantly improve pose estimation accuracy and robustness while maintaining a lightweight design. The Transformer captures global spatiotemporal dependencies, the GCN models local skeletal structures, and the diffusion model provides step-by-step optimization for fine-tuning, achieving a complementary balance between global and local features. This integration enhances the model's ability to handle pose estimation under occlusions and in complex scenarios. Furthermore, we introduce lightweight optimizations to the integrated model and refine the objective function design to reduce computational overhead without compromising performance. Evaluation results on the Human3.6M and MPI-INF-3DHP datasets demonstrate that HDiffTG achieves state-of-the-art (SOTA) performance on the MPI-INF-3DHP dataset while excelling in both accuracy and computational efficiency. Additionally, the model exhibits exceptional robustness in noisy and occluded environments. Source codes and models are available at https://github.com/CirceJie/HDiffTG
Perception Reinforcement Using Auxiliary Learning Feature Fusion: A Modified Yolov8 for Head Detection
Oct 14, 2023



Head detection provides distribution information of pedestrian, which is crucial for scene statistical analysis, traffic management, and risk assessment and early warning. However, scene complexity and large-scale variation in the real world make accurate detection more difficult. Therefore, we present a modified Yolov8 which improves head detection performance through reinforcing target perception. An Auxiliary Learning Feature Fusion (ALFF) module comprised of LSTM and convolutional blocks is used as the auxiliary task to help the model perceive targets. In addition, we introduce Noise Calibration into Distribution Focal Loss to facilitate model fitting and improve the accuracy of detection. Considering the requirements of high accuracy and speed for the head detection task, our method is adapted with two kinds of backbone, namely Yolov8n and Yolov8m. The results demonstrate the superior performance of our approach in improving detection accuracy and robustness.
Global Context Aware Convolutions for 3D Point Cloud Understanding
Aug 07, 2020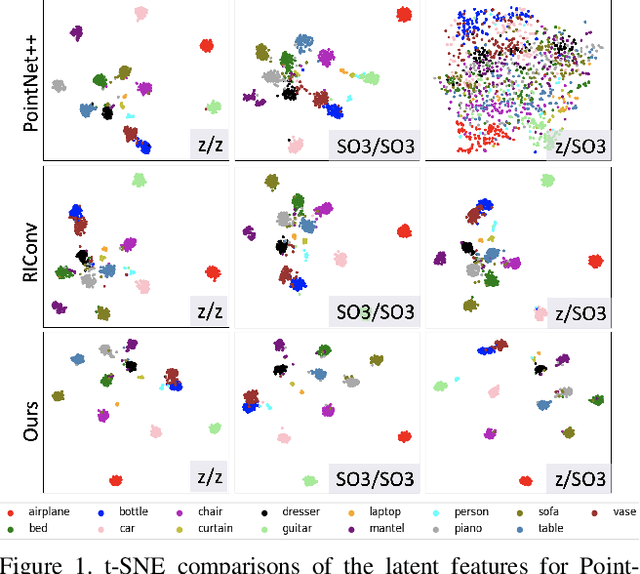
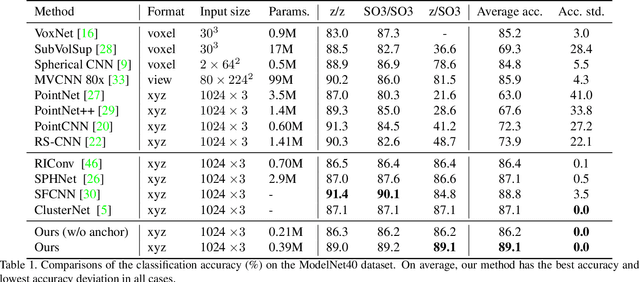
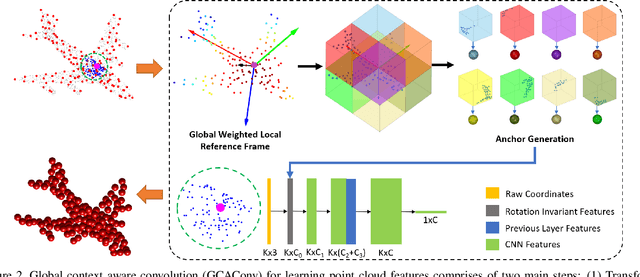

Recent advances in deep learning for 3D point clouds have shown great promises in scene understanding tasks thanks to the introduction of convolution operators to consume 3D point clouds directly in a neural network. Point cloud data, however, could have arbitrary rotations, especially those acquired from 3D scanning. Recent works show that it is possible to design point cloud convolutions with rotation invariance property, but such methods generally do not perform as well as translation-invariant only convolution. We found that a key reason is that compared to point coordinates, rotation-invariant features consumed by point cloud convolution are not as distinctive. To address this problem, we propose a novel convolution operator that enhances feature distinction by integrating global context information from the input point cloud to the convolution. To this end, a globally weighted local reference frame is constructed in each point neighborhood in which the local point set is decomposed into bins. Anchor points are generated in each bin to represent global shape features. A convolution can then be performed to transform the points and anchor features into final rotation-invariant features. We conduct several experiments on point cloud classification, part segmentation, shape retrieval, and normals estimation to evaluate our convolution, which achieves state-of-the-art accuracy under challenging rotations.