 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJacQuant: STE-Free Quantization-Aware Training via Learned Jacobian Surrogates
May 25, 2026Quantization-aware training (QAT) is widely deployed but typically relies on the Straight-Through Estimator (STE), which passes gradients through non-differentiable quantizers by fiat. This often makes training brittle near bin boundaries and weakly aligned with the actual behavior of the low-precision model. We introduce JacQuant, a QAT framework that learns a lightweight surrogate of the model's local sensitivity to parameter changes and uses it to stabilize and accelerate training within standard variance-reduced optimizers. The surrogate is inexpensive (diagonal or block-diagonal), data-driven, and compatible with common weight and activation quantizers. On code-preserving training phases, we prove convergence for non-convex objectives and obtain linear rates under a PL condition, and we relate the learned sensitivity to end-to-end output fidelity via a simple calibration argument. Across LLM benchmarks at $\leq 2$ bits, JacQuant consistently reaches higher accuracy than STE-based QAT, and the runtime analyses on various models show that the added cost remains negligible under practical group sizes. The method is drop-in and requires no changes to the forward quantizers; our empirical claims are scoped to ultra-low-bit LLM QAT.
CARE: A Molecular-Guided Foundation Model with Adaptive Region Modeling for Whole Slide Image Analysis
Feb 25, 2026Foundation models have recently achieved impressive success in computational pathology, demonstrating strong generalization across diverse histopathology tasks. However, existing models overlook the heterogeneous and non-uniform organization of pathological regions of interest (ROIs) because they rely on natural image backbones not tailored for tissue morphology. Consequently, they often fail to capture the coherent tissue architecture beyond isolated patches, limiting interpretability and clinical relevance. To address these challenges, we present Cross-modal Adaptive Region Encoder (CARE), a foundation model for pathology that automatically partitions WSIs into several morphologically relevant regions. Specifically, CARE employs a two-stage pretraining strategy: (1) a self-supervised unimodal pretraining stage that learns morphological representations from 34,277 whole-slide images (WSIs) without segmentation annotations, and (2) a cross-modal alignment stage that leverages RNA and protein profiles to refine the construction and representation of adaptive regions. This molecular guidance enables CARE to identify biologically relevant patterns and generate irregular yet coherent tissue regions, selecting the most representative area as ROI. CARE supports a broad range of pathology-related tasks, using either the ROI feature or the slide-level feature obtained by aggregating adaptive regions. Based on only one-tenth of the pretraining data typically used by mainstream foundation models, CARE achieves superior average performance across 33 downstream benchmarks, including morphological classification, molecular prediction, and survival analysis, and outperforms other foundation model baselines overall.
Strategies for Improving Communication Efficiency in Distributed and Federated Learning: Compression, Local Training, and Personalization
Sep 10, 2025



Distributed and federated learning are essential paradigms for training models across decentralized data sources while preserving privacy, yet communication overhead remains a major bottleneck. This dissertation explores strategies to improve communication efficiency, focusing on model compression, local training, and personalization. We establish a unified framework for biased and unbiased compression operators with convergence guarantees, then propose adaptive local training strategies that incorporate personalization to accelerate convergence and mitigate client drift. In particular, Scafflix balances global and personalized objectives, achieving superior performance under both IID and non-IID settings. We further introduce privacy-preserving pruning frameworks that optimize sparsity while minimizing communication costs, with Cohort-Squeeze leveraging hierarchical aggregation to reduce cross-device overhead. Finally, SymWanda, a symmetric post-training pruning method, enhances robustness under high sparsity and maintains accuracy without retraining. Extensive experiments on benchmarks and large-scale language models demonstrate favorable trade-offs among accuracy, convergence, and communication, offering theoretical and practical insights for scalable, efficient distributed learning.
A Lightweight Convolution and Vision Transformer integrated model with Multi-scale Self-attention Mechanism
Aug 23, 2025Vision Transformer (ViT) has prevailed in computer vision tasks due to its strong long-range dependency modelling ability. However, its large model size with high computational cost and weak local feature modeling ability hinder its application in real scenarios. To balance computation efficiency and performance, we propose SAEViT (Sparse-Attention-Efficient-ViT), a lightweight ViT based model with convolution blocks, in this paper to achieve efficient downstream vision tasks. Specifically, SAEViT introduces a Sparsely Aggregated Attention (SAA) module that performs adaptive sparse sampling based on image redundancy and recovers the feature map via deconvolution operation, which significantly reduces the computational complexity of attention operations. In addition, a Channel-Interactive Feed-Forward Network (CIFFN) layer is developed to enhance inter-channel information exchange through feature decomposition and redistribution, mitigating redundancy in traditional feed-forward networks (FNN). Finally, a hierarchical pyramid structure with embedded depth-wise separable convolutional blocks (DWSConv) is devised to further strengthen convolutional features. Extensive experiments on mainstream datasets show that SAEViT achieves Top-1 accuracies of 76.3\% and 79.6\% on the ImageNet-1K classification task with only 0.8 GFLOPs and 1.3 GFLOPs, respectively, demonstrating a lightweight solution for various fundamental vision tasks.
How Particle System Theory Enhances Hypergraph Message Passing
May 24, 2025Hypergraphs effectively model higher-order relationships in natural phenomena, capturing complex interactions beyond pairwise connections. We introduce a novel hypergraph message passing framework inspired by interacting particle systems, where hyperedges act as fields inducing shared node dynamics. By incorporating attraction, repulsion, and Allen-Cahn forcing terms, particles of varying classes and features achieve class-dependent equilibrium, enabling separability through the particle-driven message passing. We investigate both first-order and second-order particle system equations for modeling these dynamics, which mitigate over-smoothing and heterophily thus can capture complete interactions. The more stable second-order system permits deeper message passing. Furthermore, we enhance deterministic message passing with stochastic element to account for interaction uncertainties. We prove theoretically that our approach mitigates over-smoothing by maintaining a positive lower bound on the hypergraph Dirichlet energy during propagation and thus to enable hypergraph message passing to go deep. Empirically, our models demonstrate competitive performance on diverse real-world hypergraph node classification tasks, excelling on both homophilic and heterophilic datasets.
Symmetric Pruning of Large Language Models
Jan 31, 2025Popular post-training pruning methods such as Wanda and RIA are known for their simple, yet effective, designs that have shown exceptional empirical performance. Wanda optimizes performance through calibrated activations during pruning, while RIA emphasizes the relative, rather than absolute, importance of weight elements. Despite their practical success, a thorough theoretical foundation explaining these outcomes has been lacking. This paper introduces new theoretical insights that redefine the standard minimization objective for pruning, offering a deeper understanding of the factors contributing to their success. Our study extends beyond these insights by proposing complementary strategies that consider both input activations and weight significance. We validate these approaches through rigorous experiments, demonstrating substantial enhancements over existing methods. Furthermore, we introduce a novel training-free fine-tuning approach $R^2$-DSnoT that incorporates relative weight importance and a regularized decision boundary within a dynamic pruning-and-growing framework, significantly outperforming strong baselines and establishing a new state of the art.
Score-matching-based Structure Learning for Temporal Data on Networks
Dec 10, 2024



Causal discovery is a crucial initial step in establishing causality from empirical data and background knowledge. Numerous algorithms have been developed for this purpose. Among them, the score-matching method has demonstrated superior performance across various evaluation metrics, particularly for the commonly encountered Additive Nonlinear Causal Models. However, current score-matching-based algorithms are primarily designed to analyze independent and identically distributed (i.i.d.) data. More importantly, they suffer from high computational complexity due to the pruning step required for handling dense Directed Acyclic Graphs (DAGs). To enhance the scalability of score matching, we have developed a new parent-finding subroutine for leaf nodes in DAGs, significantly accelerating the most time-consuming part of the process: the pruning step. This improvement results in an efficiency-lifted score matching algorithm, termed Parent Identification-based Causal structure learning for both i.i.d. and temporal data on networKs, or PICK. The new score-matching algorithm extends the scope of existing algorithms and can handle static and temporal data on networks with weak network interference. Our proposed algorithm can efficiently cope with increasingly complex datasets that exhibit spatial and temporal dependencies, commonly encountered in academia and industry. The proposed algorithm can accelerate score-matching-based methods while maintaining high accuracy in real-world applications.
MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects
Dec 06, 2024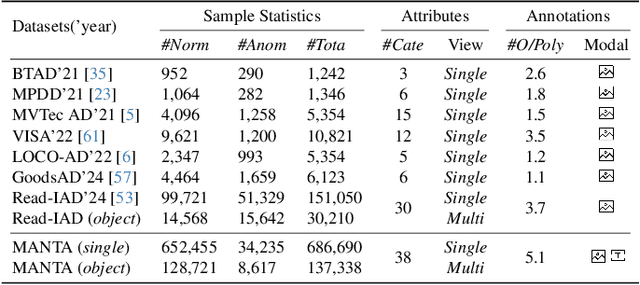
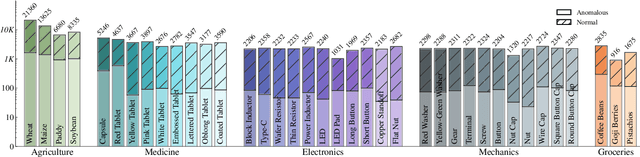

We present MANTA, a visual-text anomaly detection dataset for tiny objects. The visual component comprises over 137.3K images across 38 object categories spanning five typical domains, of which 8.6K images are labeled as anomalous with pixel-level annotations. Each image is captured from five distinct viewpoints to ensure comprehensive object coverage. The text component consists of two subsets: Declarative Knowledge, including 875 words that describe common anomalies across various domains and specific categories, with detailed explanations for < what, why, how>, including causes and visual characteristics; and Constructivist Learning, providing 2K multiple-choice questions with varying levels of difficulty, each paired with images and corresponded answer explanations. We also propose a baseline for visual-text tasks and conduct extensive benchmarking experiments to evaluate advanced methods across different settings, highlighting the challenges and efficacy of our dataset.
Cohort Squeeze: Beyond a Single Communication Round per Cohort in Cross-Device Federated Learning
Jun 03, 2024



Virtually all federated learning (FL) methods, including FedAvg, operate in the following manner: i) an orchestrating server sends the current model parameters to a cohort of clients selected via certain rule, ii) these clients then independently perform a local training procedure (e.g., via SGD or Adam) using their own training data, and iii) the resulting models are shipped to the server for aggregation. This process is repeated until a model of suitable quality is found. A notable feature of these methods is that each cohort is involved in a single communication round with the server only. In this work we challenge this algorithmic design primitive and investigate whether it is possible to ``squeeze more juice" out of each cohort than what is possible in a single communication round. Surprisingly, we find that this is indeed the case, and our approach leads to up to 74% reduction in the total communication cost needed to train a FL model in the cross-device setting. Our method is based on a novel variant of the stochastic proximal point method (SPPM-AS) which supports a large collection of client sampling procedures some of which lead to further gains when compared to classical client selection approaches.
Prune at the Clients, Not the Server: Accelerated Sparse Training in Federated Learning
May 31, 2024



In the recent paradigm of Federated Learning (FL), multiple clients train a shared model while keeping their local data private. Resource constraints of clients and communication costs pose major problems for training large models in FL. On the one hand, addressing the resource limitations of the clients, sparse training has proven to be a powerful tool in the centralized setting. On the other hand, communication costs in FL can be addressed by local training, where each client takes multiple gradient steps on its local data. Recent work has shown that local training can provably achieve the optimal accelerated communication complexity [Mishchenko et al., 2022]. Hence, one would like an accelerated sparse training algorithm. In this work we show that naive integration of sparse training and acceleration at the server fails, and how to fix it by letting the clients perform these tasks appropriately. We introduce Sparse-ProxSkip, our method developed for the nonconvex setting, inspired by RandProx [Condat and Richt\'arik, 2022], which provably combines sparse training and acceleration in the convex setting. We demonstrate the good performance of Sparse-ProxSkip in extensive experiments.