 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2Seg: Pointly-supervised Segmentation via Mutual Distillation
Jan 18, 2024Point-level Supervised Instance Segmentation (PSIS) aims to enhance the applicability and scalability of instance segmentation by utilizing low-cost yet instance-informative annotations. Existing PSIS methods usually rely on positional information to distinguish objects, but predicting precise boundaries remains challenging due to the lack of contour annotations. Nevertheless, weakly supervised semantic segmentation methods are proficient in utilizing intra-class feature consistency to capture the boundary contours of the same semantic regions. In this paper, we design a Mutual Distillation Module (MDM) to leverage the complementary strengths of both instance position and semantic information and achieve accurate instance-level object perception. The MDM consists of Semantic to Instance (S2I) and Instance to Semantic (I2S). S2I is guided by the precise boundaries of semantic regions to learn the association between annotated points and instance contours. I2S leverages discriminative relationships between instances to facilitate the differentiation of various objects within the semantic map. Extensive experiments substantiate the efficacy of MDM in fostering the synergy between instance and semantic information, consequently improving the quality of instance-level object representations. Our method achieves 55.7 mAP$_{50}$ and 17.6 mAP on the PASCAL VOC and MS COCO datasets, significantly outperforming recent PSIS methods and several box-supervised instance segmentation competitors.
Semantic-aware SAM for Point-Prompted Instance Segmentation
Dec 26, 2023



Single-point annotation in visual tasks, with the goal of minimizing labelling costs, is becoming increasingly prominent in research. Recently, visual foundation models, such as Segment Anything (SAM), have gained widespread usage due to their robust zero-shot capabilities and exceptional annotation performance. However, SAM's class-agnostic output and high confidence in local segmentation introduce 'semantic ambiguity', posing a challenge for precise category-specific segmentation. In this paper, we introduce a cost-effective category-specific segmenter using SAM. To tackle this challenge, we have devised a Semantic-Aware Instance Segmentation Network (SAPNet) that integrates Multiple Instance Learning (MIL) with matching capability and SAM with point prompts. SAPNet strategically selects the most representative mask proposals generated by SAM to supervise segmentation, with a specific focus on object category information. Moreover, we introduce the Point Distance Guidance and Box Mining Strategy to mitigate inherent challenges: 'group' and 'local' issues in weakly supervised segmentation. These strategies serve to further enhance the overall segmentation performance. The experimental results on Pascal VOC and COCO demonstrate the promising performance of our proposed SAPNet, emphasizing its semantic matching capabilities and its potential to advance point-prompted instance segmentation. The code will be made publicly available.
Weakly Supervised Video Individual CountingWeakly Supervised Video Individual Counting
Dec 10, 2023



Video Individual Counting (VIC) aims to predict the number of unique individuals in a single video. % Existing methods learn representations based on trajectory labels for individuals, which are annotation-expensive. % To provide a more realistic reflection of the underlying practical challenge, we introduce a weakly supervised VIC task, wherein trajectory labels are not provided. Instead, two types of labels are provided to indicate traffic entering the field of view (inflow) and leaving the field view (outflow). % We also propose the first solution as a baseline that formulates the task as a weakly supervised contrastive learning problem under group-level matching. In doing so, we devise an end-to-end trainable soft contrastive loss to drive the network to distinguish inflow, outflow, and the remaining. % To facilitate future study in this direction, we generate annotations from the existing VIC datasets SenseCrowd and CroHD and also build a new dataset, UAVVIC. % Extensive results show that our baseline weakly supervised method outperforms supervised methods, and thus, little information is lost in the transition to the more practically relevant weakly supervised task. The code and trained model will be public at \href{https://github.com/streamer-AP/CGNet}{CGNet}
Boosting Segment Anything Model Towards Open-Vocabulary Learning
Dec 06, 2023



The recent Segment Anything Model (SAM) has emerged as a new paradigmatic vision foundation model, showcasing potent zero-shot generalization and flexible prompting. Despite SAM finding applications and adaptations in various domains, its primary limitation lies in the inability to grasp object semantics. In this paper, we present Sambor to seamlessly integrate SAM with the open-vocabulary object detector in an end-to-end framework. While retaining all the remarkable capabilities inherent to SAM, we enhance it with the capacity to detect arbitrary objects based on human inputs like category names or reference expressions. To accomplish this, we introduce a novel SideFormer module that extracts SAM features to facilitate zero-shot object localization and inject comprehensive semantic information for open-vocabulary recognition. In addition, we devise an open-set region proposal network (Open-set RPN), enabling the detector to acquire the open-set proposals generated by SAM. Sambor demonstrates superior zero-shot performance across benchmarks, including COCO and LVIS, proving highly competitive against previous SoTA methods. We aspire for this work to serve as a meaningful endeavor in endowing SAM to recognize diverse object categories and advancing open-vocabulary learning with the support of vision foundation models.
P2RBox: A Single Point is All You Need for Oriented Object Detection
Nov 22, 2023



Oriented object detection, a specialized subfield in computer vision, finds applications across diverse scenarios, excelling particularly when dealing with objects of arbitrary orientations. Conversely, point annotation, which treats objects as single points, offers a cost-effective alternative to rotated and horizontal bounding boxes but sacrifices performance due to the loss of size and orientation information. In this study, we introduce the P2RBox network, which leverages point annotations and a mask generator to create mask proposals, followed by filtration through our Inspector Module and Constrainer Module. This process selects high-quality masks, which are subsequently converted into rotated box annotations for training a fully supervised detector. Specifically, we've thoughtfully crafted an Inspector Module rooted in multi-instance learning principles to evaluate the semantic score of masks. We've also proposed a more robust mask quality assessment in conjunction with the Constrainer Module. Furthermore, we've introduced a Symmetry Axis Estimation (SAE) Module inspired by the spectral theorem for symmetric matrices to transform the top-performing mask proposal into rotated bounding boxes. P2RBox performs well with three fully supervised rotated object detectors: RetinaNet, Rotated FCOS, and Oriented R-CNN. By combining with Oriented R-CNN, P2RBox achieves 62.26% on DOTA-v1.0 test dataset. As far as we know, this is the first attempt at training an oriented object detector with point supervision.
Spatial Self-Distillation for Object Detection with Inaccurate Bounding Boxes
Aug 15, 2023



Object detection via inaccurate bounding boxes supervision has boosted a broad interest due to the expensive high-quality annotation data or the occasional inevitability of low annotation quality (\eg tiny objects). The previous works usually utilize multiple instance learning (MIL), which highly depends on category information, to select and refine a low-quality box. Those methods suffer from object drift, group prediction and part domination problems without exploring spatial information. In this paper, we heuristically propose a \textbf{Spatial Self-Distillation based Object Detector (SSD-Det)} to mine spatial information to refine the inaccurate box in a self-distillation fashion. SSD-Det utilizes a Spatial Position Self-Distillation \textbf{(SPSD)} module to exploit spatial information and an interactive structure to combine spatial information and category information, thus constructing a high-quality proposal bag. To further improve the selection procedure, a Spatial Identity Self-Distillation \textbf{(SISD)} module is introduced in SSD-Det to obtain spatial confidence to help select the best proposals. Experiments on MS-COCO and VOC datasets with noisy box annotation verify our method's effectiveness and achieve state-of-the-art performance. The code is available at https://github.com/ucas-vg/PointTinyBenchmark/tree/SSD-Det.
CircleNet: Reciprocating Feature Adaptation for Robust Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially when the scene contains significant occlusion and/or low resolution of the pedestrians to be detected. Existing methods are unable to adapt to these difficult cases while maintaining acceptable performance. In this paper we propose a novel feature learning model, referred to as CircleNet, to achieve feature adaptation by mimicking the process humans looking at low resolution and occluded objects: focusing on it again, at a finer scale, if the object can not be identified clearly for the first time. CircleNet is implemented as a set of feature pyramids and uses weight sharing path augmentation for better feature fusion. It targets at reciprocating feature adaptation and iterative object detection using multiple top-down and bottom-up pathways. To take full advantage of the feature adaptation capability in CircleNet, we design an instance decomposition training strategy to focus on detecting pedestrian instances of various resolutions and different occlusion levels in each cycle. Specifically, CircleNet implements feature ensemble with the idea of hard negative boosting in an end-to-end manner. Experiments on two pedestrian detection datasets, Caltech and CityPersons, show that CircleNet improves the performance of occluded and low-resolution pedestrians with significant margins while maintaining good performance on normal instances.
Consistency-Aware Anchor Pyramid Network for Crowd Localization
Dec 08, 2022



Crowd localization aims to predict the spatial position of humans in a crowd scenario. We observe that the performance of existing methods is challenged from two aspects: (i) ranking inconsistency between test and training phases; and (ii) fixed anchor resolution may underfit or overfit crowd densities of local regions. To address these problems, we design a supervision target reassignment strategy for training to reduce ranking inconsistency and propose an anchor pyramid scheme to adaptively determine the anchor density in each image region. Extensive experimental results on three widely adopted datasets (ShanghaiTech A\&B, JHU-CROWD++, UCF-QNRF) demonstrate the favorable performance against several state-of-the-art methods.
Multi-Attention Network for Compressed Video Referring Object Segmentation
Jul 26, 2022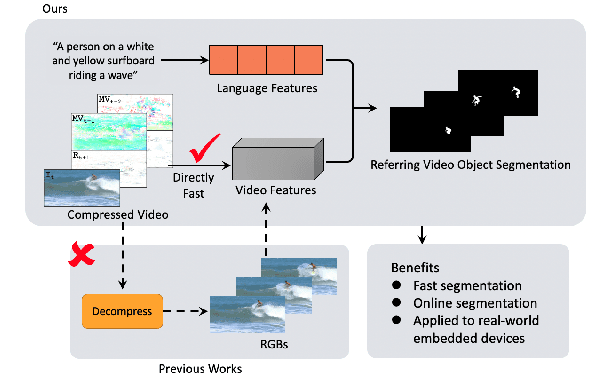
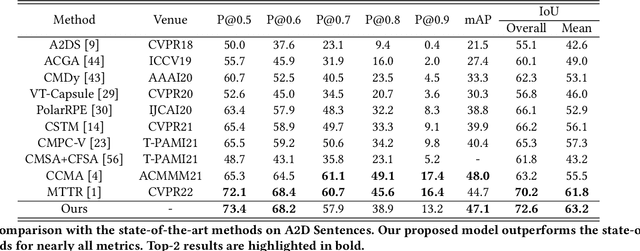
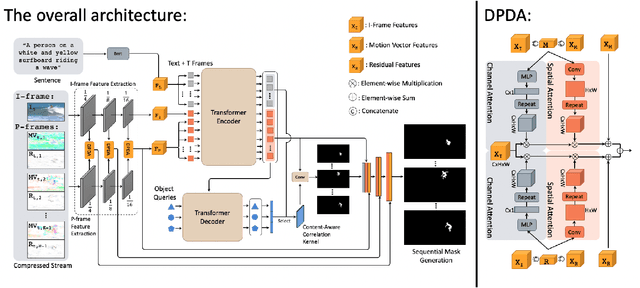
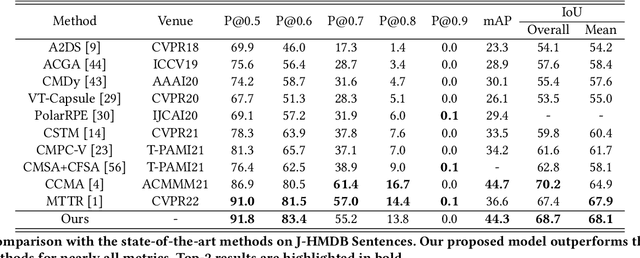
Referring video object segmentation aims to segment the object referred by a given language expression. Existing works typically require compressed video bitstream to be decoded to RGB frames before being segmented, which increases computation and storage requirements and ultimately slows the inference down. This may hamper its application in real-world computing resource limited scenarios, such as autonomous cars and drones. To alleviate this problem, in this paper, we explore the referring object segmentation task on compressed videos, namely on the original video data flow. Besides the inherent difficulty of the video referring object segmentation task itself, obtaining discriminative representation from compressed video is also rather challenging. To address this problem, we propose a multi-attention network which consists of dual-path dual-attention module and a query-based cross-modal Transformer module. Specifically, the dual-path dual-attention module is designed to extract effective representation from compressed data in three modalities, i.e., I-frame, Motion Vector and Residual. The query-based cross-modal Transformer firstly models the correlation between linguistic and visual modalities, and then the fused multi-modality features are used to guide object queries to generate a content-aware dynamic kernel and to predict final segmentation masks. Different from previous works, we propose to learn just one kernel, which thus removes the complicated post mask-matching procedure of existing methods. Extensive promising experimental results on three challenging datasets show the effectiveness of our method compared against several state-of-the-art methods which are proposed for processing RGB data. Source code is available at: https://github.com/DexiangHong/MANet.
Point-to-Box Network for Accurate Object Detection via Single Point Supervision
Jul 14, 2022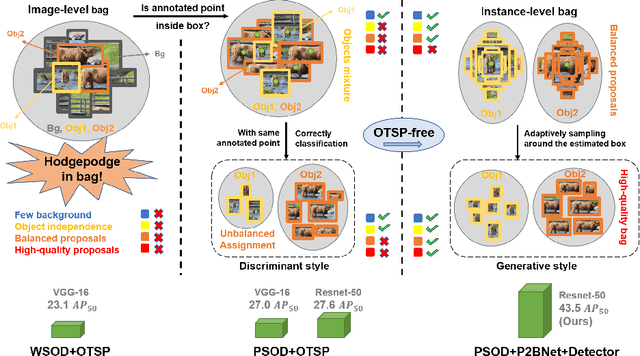
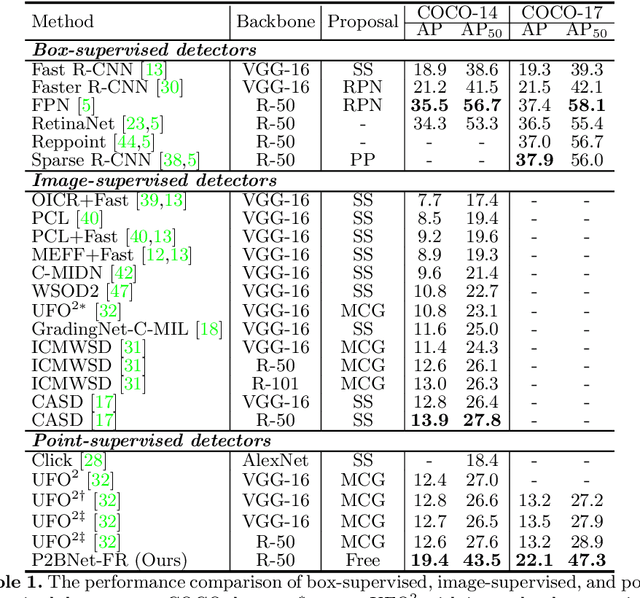
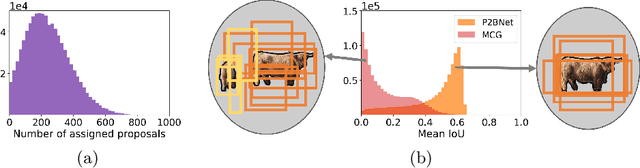
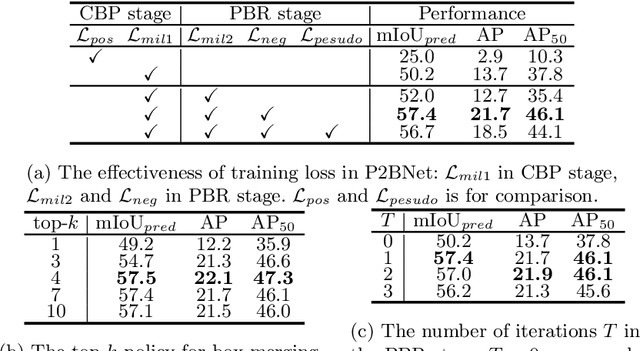
Object detection using single point supervision has received increasing attention over the years. In this paper, we attribute such a large performance gap to the failure of generating high-quality proposal bags which are crucial for multiple instance learning (MIL). To address this problem, we introduce a lightweight alternative to the off-the-shelf proposal (OTSP) method and thereby create the Point-to-Box Network (P2BNet), which can construct an inter-objects balanced proposal bag by generating proposals in an anchor-like way. By fully investigating the accurate position information, P2BNet further constructs an instance-level bag, avoiding the mixture of multiple objects. Finally, a coarse-to-fine policy in a cascade fashion is utilized to improve the IoU between proposals and ground-truth (GT). Benefiting from these strategies, P2BNet is able to produce high-quality instance-level bags for object detection. P2BNet improves the mean average precision (AP) by more than 50% relative to the previous best PSOD method on the MS COCO dataset. It also demonstrates the great potential to bridge the performance gap between point supervised and bounding-box supervised detectors. The code will be released at github.com/ucas-vg/P2BNet.