 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLK-REW: A Unified Block-based DNN Pruning Framework using Reweighted Regularization Method
Feb 22, 2020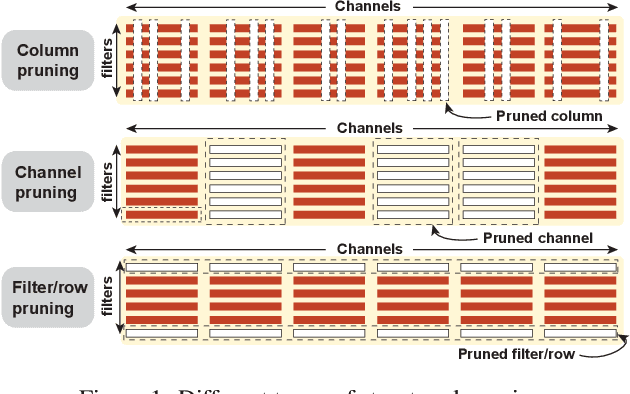
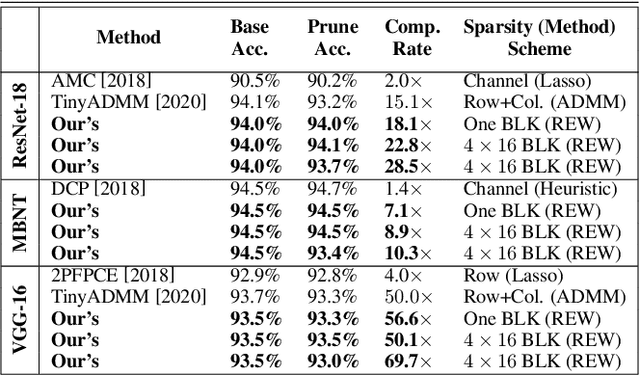
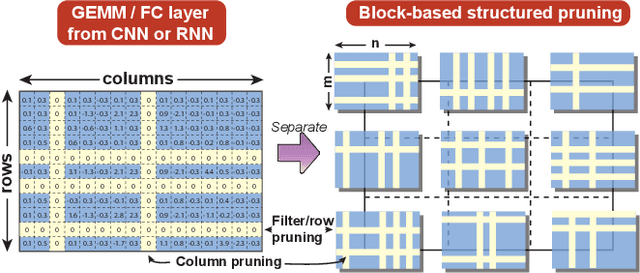
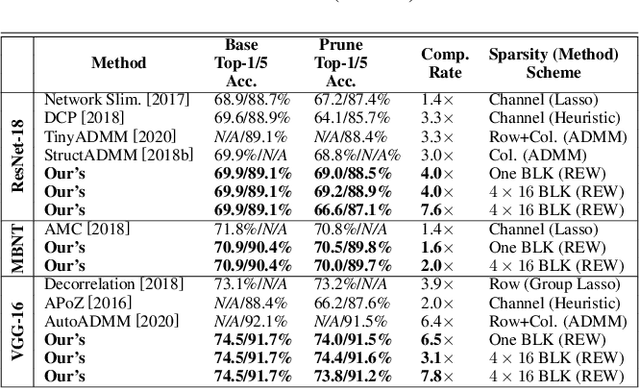
Accelerating DNN execution on various resource-limited computing platforms has been a long-standing problem. Prior works utilize l1-based group lasso or dynamic regularization such as ADMM to perform structured pruning on DNN models to leverage the parallel computing architectures. However, both of the pruning dimensions and pruning methods lack universality, which leads to degraded performance and limited applicability. To solve the problem, we propose a new block-based pruning framework that comprises a general and flexible structured pruning dimension as well as a powerful and efficient reweighted regularization method. Our framework is universal, which can be applied to both CNNs and RNNs, implying complete support for the two major kinds of computation-intensive layers (i.e., CONV and FC layers). To complete all aspects of the pruning-for-acceleration task, we also integrate compiler-based code optimization into our framework that can perform DNN inference in a real-time manner. To the best of our knowledge, it is the first time that the weight pruning framework achieves universal coverage for both CNNs and RNNs with real-time mobile acceleration and no accuracy compromise.
RTMobile: Beyond Real-Time Mobile Acceleration of RNNs for Speech Recognition
Feb 19, 2020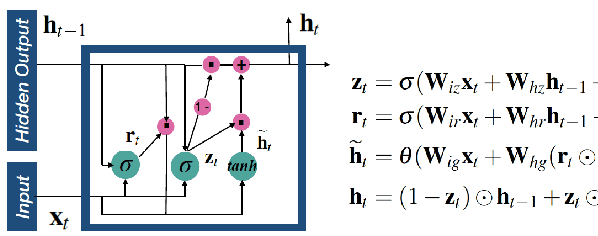
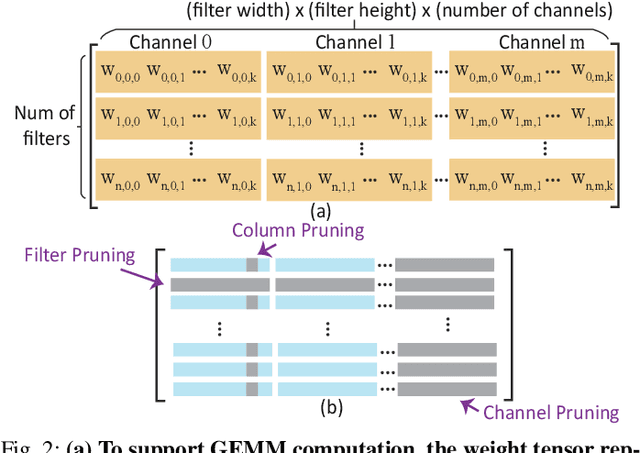
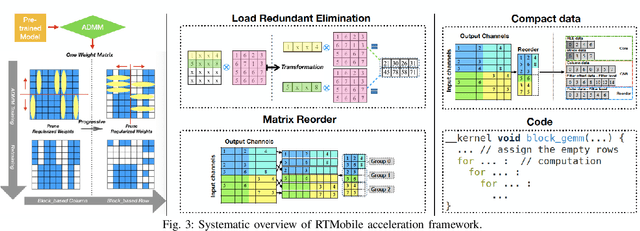
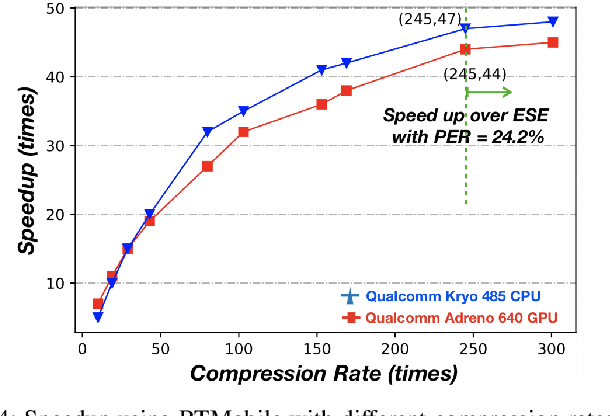
Recurrent neural networks (RNNs) based automatic speech recognition has nowadays become prevalent on mobile devices such as smart phones. However, previous RNN compression techniques either suffer from hardware performance overhead due to irregularity or significant accuracy loss due to the preserved regularity for hardware friendliness. In this work, we propose RTMobile that leverages both a novel block-based pruning approach and compiler optimizations to accelerate RNN inference on mobile devices. Our proposed RTMobile is the first work that can achieve real-time RNN inference on mobile platforms. Experimental results demonstrate that RTMobile can significantly outperform existing RNN hardware acceleration methods in terms of inference accuracy and time. Compared with prior work on FPGA, RTMobile using Adreno 640 embedded GPU on GRU can improve the energy-efficiency by about 40$\times$ while maintaining the same inference time.
SS-Auto: A Single-Shot, Automatic Structured Weight Pruning Framework of DNNs with Ultra-High Efficiency
Jan 23, 2020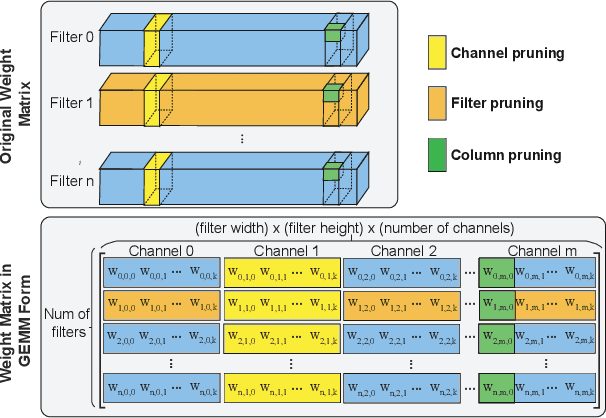
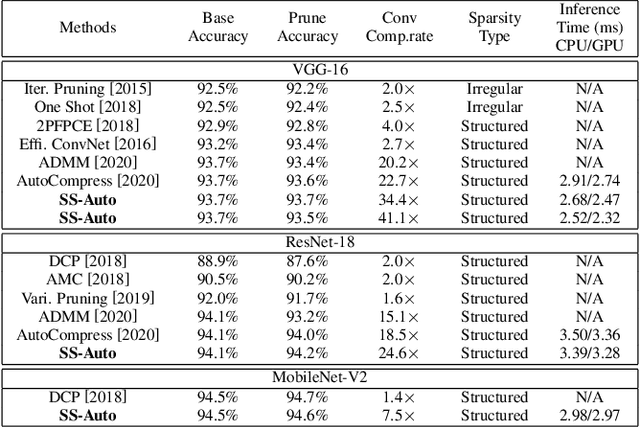
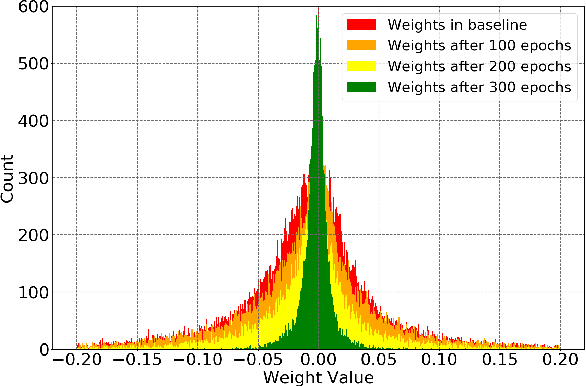
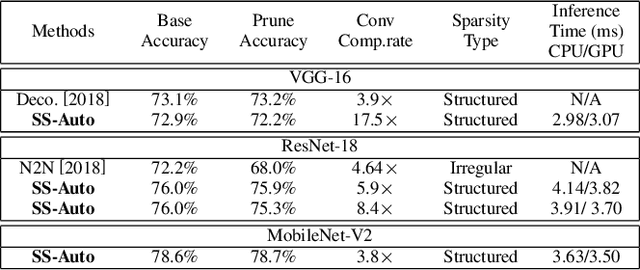
Structured weight pruning is a representative model compression technique of DNNs for hardware efficiency and inference accelerations. Previous works in this area leave great space for improvement since sparse structures with combinations of different structured pruning schemes are not exploited fully and efficiently. To mitigate the limitations, we propose SS-Auto, a single-shot, automatic structured pruning framework that can achieve row pruning and column pruning simultaneously. We adopt soft constraint-based formulation to alleviate the strong non-convexity of l0-norm constraints used in state-of-the-art ADMM-based methods for faster convergence and fewer hyperparameters. Instead of solving the problem directly, a Primal-Proximal solution is proposed to avoid the pitfall of penalizing all weights equally, thereby enhancing the accuracy. Extensive experiments on CIFAR-10 and CIFAR-100 datasets demonstrate that the proposed framework can achieve ultra-high pruning rates while maintaining accuracy. Furthermore, significant inference speedup has been observed from the proposed framework through actual measurements on the smartphone.
A SOT-MRAM-based Processing-In-Memory Engine for Highly Compressed DNN Implementation
Nov 24, 2019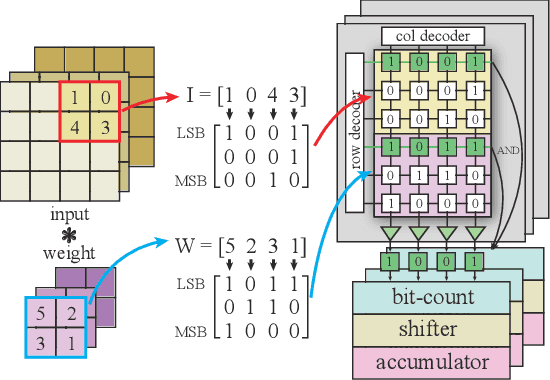
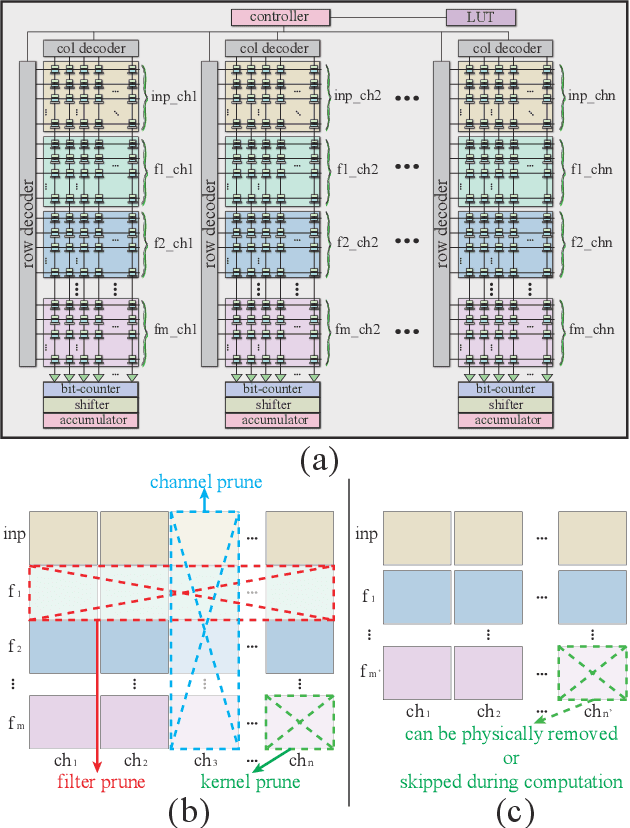
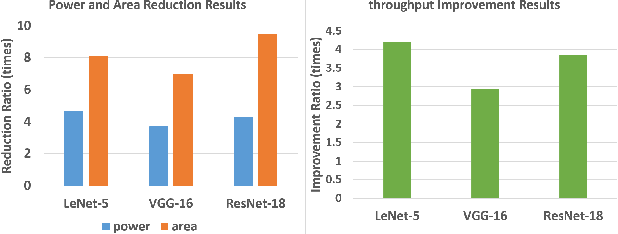
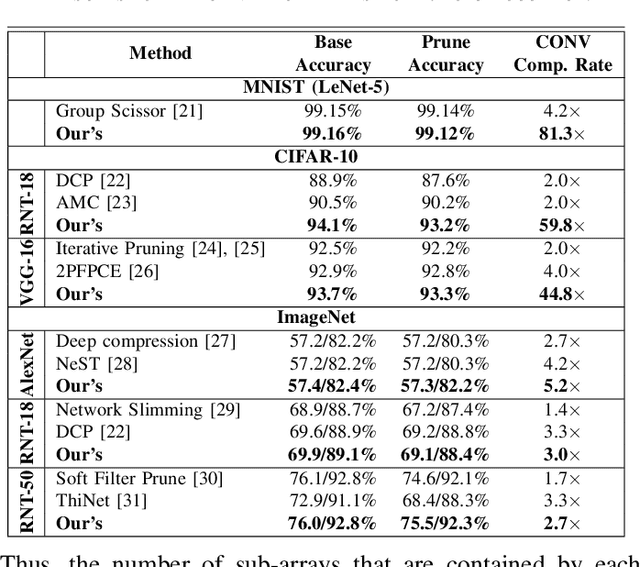
The computing wall and data movement challenges of deep neural networks (DNNs) have exposed the limitations of conventional CMOS-based DNN accelerators. Furthermore, the deep structure and large model size will make DNNs prohibitive to embedded systems and IoT devices, where low power consumption are required. To address these challenges, spin orbit torque magnetic random-access memory (SOT-MRAM) and SOT-MRAM based Processing-In-Memory (PIM) engines have been used to reduce the power consumption of DNNs since SOT-MRAM has the characteristic of near-zero standby power, high density, none-volatile. However, the drawbacks of SOT-MRAM based PIM engines such as high writing latency and requiring low bit-width data decrease its popularity as a favorable energy efficient DNN accelerator. To mitigate these drawbacks, we propose an ultra energy efficient framework by using model compression techniques including weight pruning and quantization from the software level considering the architecture of SOT-MRAM PIM. And we incorporate the alternating direction method of multipliers (ADMM) into the training phase to further guarantee the solution feasibility and satisfy SOT-MRAM hardware constraints. Thus, the footprint and power consumption of SOT-MRAM PIM can be reduced, while increasing the overall system throughput at the meantime, making our proposed ADMM-based SOT-MRAM PIM more energy efficiency and suitable for embedded systems or IoT devices. Our experimental results show the accuracy and compression rate of our proposed framework is consistently outperforming the reference works, while the efficiency (area \& power) and throughput of SOT-MRAM PIM engine is significantly improved.
Non-structured DNN Weight Pruning Considered Harmful
Jul 03, 2019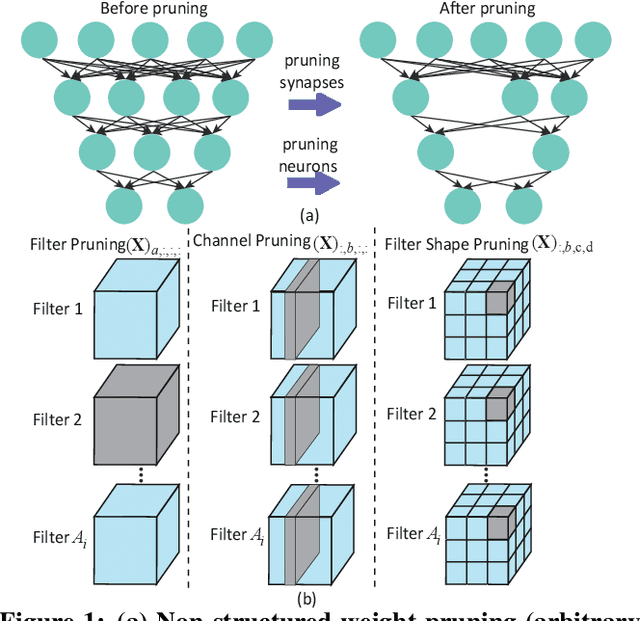
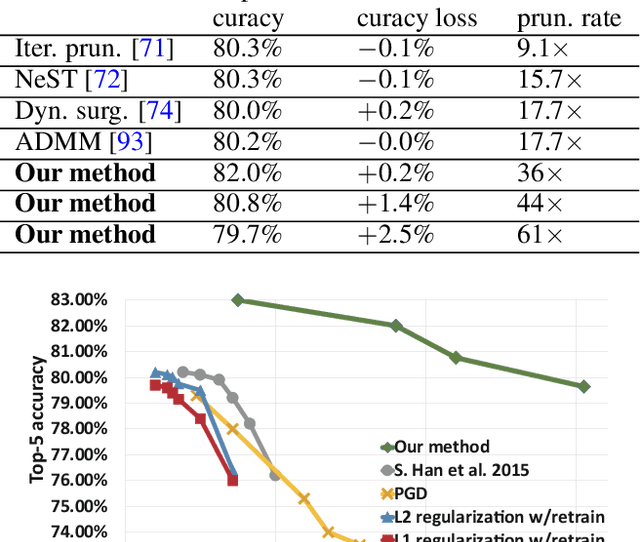
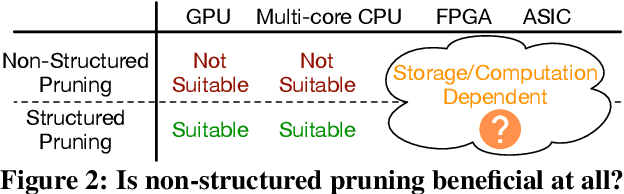
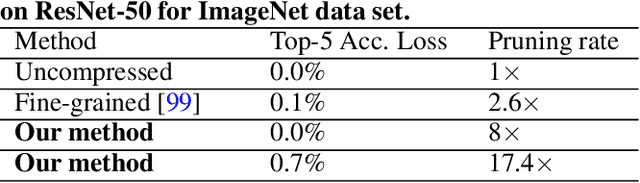
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compression with two main approaches. Weight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate but incurs index accesses due to irregular weights, or structured manner, which preserves the full matrix structure with lower pruning rate. Weight quantization leverages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly, and has become a "must-do" step for FPGA and ASIC implementations. This paper provides a definitive answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework. Second, we develop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency. Our results show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348x, 36x, and 8x overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respectively, with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study. Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structrued pruning is not competitive in terms of both storage and computation efficiency. Thus, we conclude that non-structured pruning is considered harmful. We urge the community not to continue the DNN inference acceleration for non-structured sparsity.
ResNet Can Be Pruned 60x: Introducing Network Purification and Unused Path Removal after Weight Pruning
Apr 30, 2019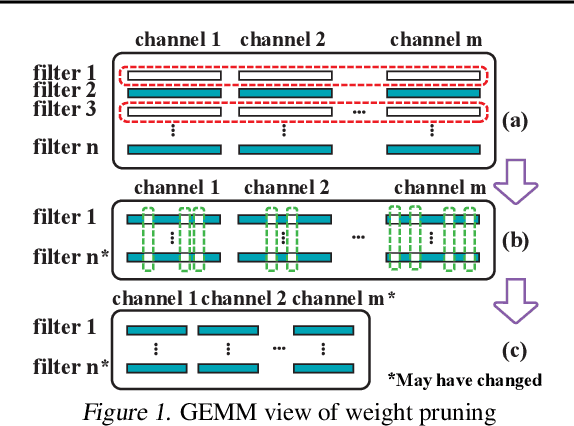
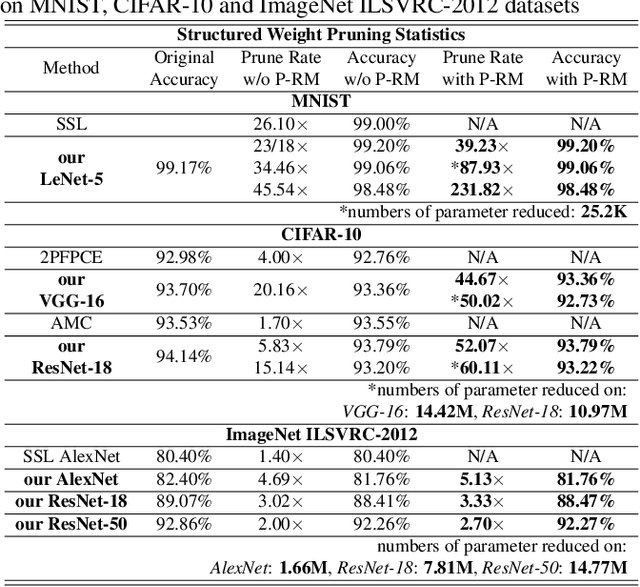
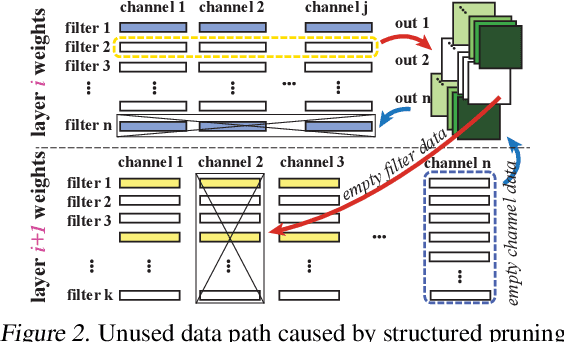
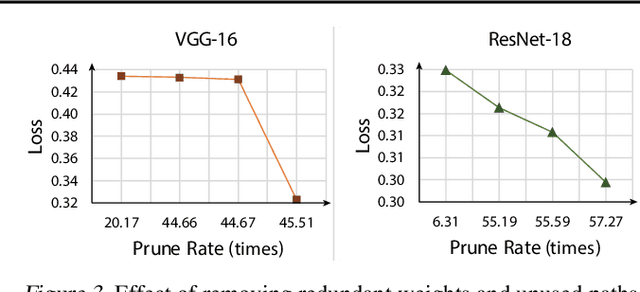
The state-of-art DNN structures involve high computation and great demand for memory storage which pose intensive challenge on DNN framework resources. To mitigate the challenges, weight pruning techniques has been studied. However, high accuracy solution for extreme structured pruning that combines different types of structured sparsity still waiting for unraveling due to the extremely reduced weights in DNN networks. In this paper, we propose a DNN framework which combines two different types of structured weight pruning (filter and column prune) by incorporating alternating direction method of multipliers (ADMM) algorithm for better prune performance. We are the first to find non-optimality of ADMM process and unused weights in a structured pruned model, and further design an optimization framework which contains the first proposed Network Purification and Unused Path Removal algorithms which are dedicated to post-processing an structured pruned model after ADMM steps. Some high lights shows we achieve 232x compression on LeNet-5, 60x compression on ResNet-18 CIFAR-10 and over 5x compression on AlexNet. We share our models at anonymous link http://bit.ly/2VJ5ktv.
Progressive DNN Compression: A Key to Achieve Ultra-High Weight Pruning and Quantization Rates using ADMM
Mar 30, 2019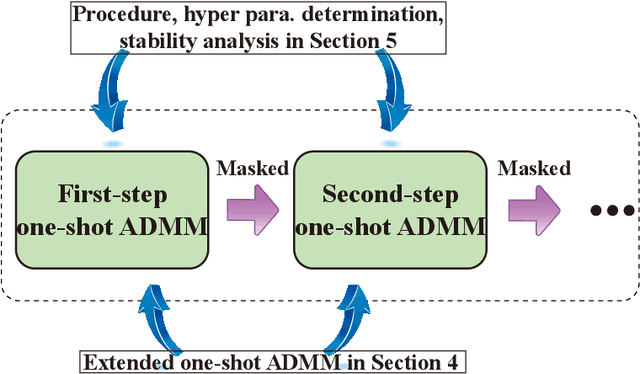
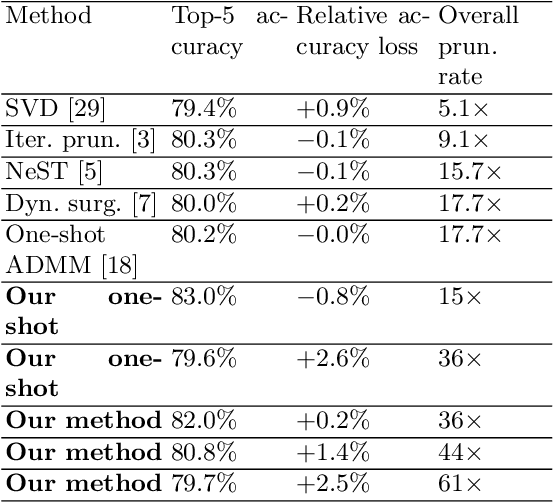
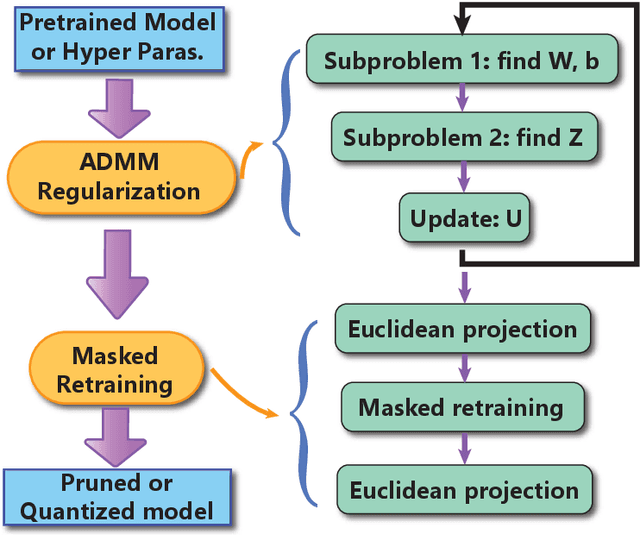
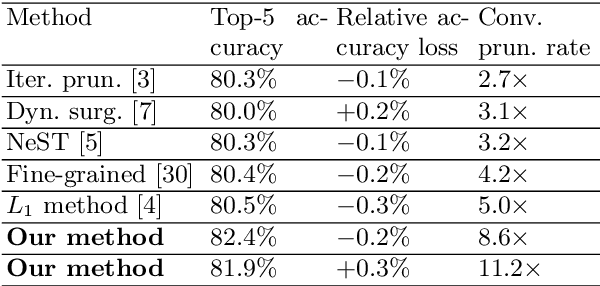
Weight pruning and weight quantization are two important categories of DNN model compression. Prior work on these techniques are mainly based on heuristics. A recent work developed a systematic frame-work of DNN weight pruning using the advanced optimization technique ADMM (Alternating Direction Methods of Multipliers), achieving one of state-of-art in weight pruning results. In this work, we first extend such one-shot ADMM-based framework to guarantee solution feasibility and provide fast convergence rate, and generalize to weight quantization as well. We have further developed a multi-step, progressive DNN weight pruning and quantization framework, with dual benefits of (i) achieving further weight pruning/quantization thanks to the special property of ADMM regularization, and (ii) reducing the search space within each step. Extensive experimental results demonstrate the superior performance compared with prior work. Some highlights: (i) we achieve 246x,36x, and 8x weight pruning on LeNet-5, AlexNet, and ResNet-50 models, respectively, with (almost) zero accuracy loss; (ii) even a significant 61x weight pruning in AlexNet (ImageNet) results in only minor degradation in actual accuracy compared with prior work; (iii) we are among the first to derive notable weight pruning results for ResNet and MobileNet models; (iv) we derive the first lossless, fully binarized (for all layers) LeNet-5 for MNIST and VGG-16 for CIFAR-10; and (v) we derive the first fully binarized (for all layers) ResNet for ImageNet with reasonable accuracy loss.