 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoVeritas: AI-Generated Video Detection via Perception Pretext Reinforcement Learning
Feb 09, 2026The growing capability of video generation poses escalating security risks, making reliable detection increasingly essential. In this paper, we introduce VideoVeritas, a framework that integrates fine-grained perception and fact-based reasoning. We observe that while current multi-modal large language models (MLLMs) exhibit strong reasoning capacity, their granular perception ability remains limited. To mitigate this, we introduce Joint Preference Alignment and Perception Pretext Reinforcement Learning (PPRL). Specifically, rather than directly optimizing for detection task, we adopt general spatiotemporal grounding and self-supervised object counting in the RL stage, enhancing detection performance with simple perception pretext tasks. To facilitate robust evaluation, we further introduce MintVid, a light yet high-quality dataset containing 3K videos from 9 state-of-the-art generators, along with a real-world collected subset that has factual errors in content. Experimental results demonstrate that existing methods tend to bias towards either superficial reasoning or mechanical analysis, while VideoVeritas achieves more balanced performance across diverse benchmarks.
UniSurg: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
Feb 05, 2026While foundation models have advanced surgical video analysis, current approaches rely predominantly on pixel-level reconstruction objectives that waste model capacity on low-level visual details - such as smoke, specular reflections, and fluid motion - rather than semantic structures essential for surgical understanding. We present UniSurg, a video-native foundation model that shifts the learning paradigm from pixel-level reconstruction to latent motion prediction. Built on the Video Joint Embedding Predictive Architecture (V-JEPA), UniSurg introduces three key technical innovations tailored to surgical videos: 1) motion-guided latent prediction to prioritize semantically meaningful regions, 2) spatiotemporal affinity self-distillation to enforce relational consistency, and 3) feature diversity regularization to prevent representation collapse in texture-sparse surgical scenes. To enable large-scale pretraining, we curate UniSurg-15M, the largest surgical video dataset to date, comprising 3,658 hours of video from 50 sources across 13 anatomical regions. Extensive experiments across 17 benchmarks demonstrate that UniSurg significantly outperforms state-of-the-art methods on surgical workflow recognition (+14.6% F1 on EgoSurgery, +10.3% on PitVis), action triplet recognition (39.54% mAP-IVT on CholecT50), skill assessment, polyp segmentation, and depth estimation. These results establish UniSurg as a new standard for universal, motion-oriented surgical video understanding.
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
UPA: Unsupervised Prompt Agent via Tree-Based Search and Selection
Jan 30, 2026Prompt agents have recently emerged as a promising paradigm for automated prompt optimization, framing refinement as a sequential decision-making problem over a structured prompt space. While this formulation enables the use of advanced planning algorithms, these methods typically assume access to supervised reward signals, which are often unavailable in practical scenarios. In this work, we propose UPA, an Unsupervised Prompt Agent that realizes structured search and selection without relying on supervised feedback. Specifically, during search, UPA iteratively constructs an evolving tree structure to navigate the prompt space, guided by fine-grained and order-invariant pairwise comparisons from Large Language Models (LLMs). Crucially, as these local comparisons do not inherently yield a consistent global scale, we decouple systematic prompt exploration from final selection, introducing a two-stage framework grounded in the Bradley-Terry-Luce (BTL) model. This framework first performs path-wise Bayesian aggregation of local comparisons to filter candidates under uncertainty, followed by global tournament-style comparisons to infer latent prompt quality and identify the optimal prompt. Experiments across multiple tasks demonstrate that UPA consistently outperforms existing prompt optimization methods, showing that agent-style optimization remains highly effective even in fully unsupervised settings.
Veritas: Generalizable Deepfake Detection via Pattern-Aware Reasoning
Aug 28, 2025



Deepfake detection remains a formidable challenge due to the complex and evolving nature of fake content in real-world scenarios. However, existing academic benchmarks suffer from severe discrepancies from industrial practice, typically featuring homogeneous training sources and low-quality testing images, which hinder the practical deployments of current detectors. To mitigate this gap, we introduce HydraFake, a dataset that simulates real-world challenges with hierarchical generalization testing. Specifically, HydraFake involves diversified deepfake techniques and in-the-wild forgeries, along with rigorous training and evaluation protocol, covering unseen model architectures, emerging forgery techniques and novel data domains. Building on this resource, we propose Veritas, a multi-modal large language model (MLLM) based deepfake detector. Different from vanilla chain-of-thought (CoT), we introduce pattern-aware reasoning that involves critical reasoning patterns such as "planning" and "self-reflection" to emulate human forensic process. We further propose a two-stage training pipeline to seamlessly internalize such deepfake reasoning capacities into current MLLMs. Experiments on HydraFake dataset reveal that although previous detectors show great generalization on cross-model scenarios, they fall short on unseen forgeries and data domains. Our Veritas achieves significant gains across different OOD scenarios, and is capable of delivering transparent and faithful detection outputs.
Pose-RFT: Enhancing MLLMs for 3D Pose Generation via Hybrid Action Reinforcement Fine-Tuning
Aug 11, 2025Generating 3D human poses from multimodal inputs such as images or text requires models to capture both rich spatial and semantic correspondences. While pose-specific multimodal large language models (MLLMs) have shown promise in this task, they are typically trained with supervised objectives such as SMPL parameter regression or token-level prediction, which struggle to model the inherent ambiguity and achieve task-specific alignment required for accurate 3D pose generation. To address these limitations, we propose Pose-RFT, a reinforcement fine-tuning framework tailored for 3D human pose generation in MLLMs. We formulate the task as a hybrid action reinforcement learning problem that jointly optimizes discrete language prediction and continuous pose generation. To this end, we introduce HyGRPO, a hybrid reinforcement learning algorithm that performs group-wise reward normalization over sampled responses to guide joint optimization of discrete and continuous actions. Pose-RFT further incorporates task-specific reward functions to guide optimization towards spatial alignment in image-to-pose generation and semantic consistency in text-to-pose generation. Extensive experiments on multiple pose generation benchmarks demonstrate that Pose-RFT significantly improves performance over existing pose-specific MLLMs, validating the effectiveness of hybrid action reinforcement fine-tuning for 3D pose generation.
MM2CT: MR-to-CT translation for multi-modal image fusion with mamba
Aug 07, 2025Magnetic resonance (MR)-to-computed tomography (CT) translation offers significant advantages, including the elimination of radiation exposure associated with CT scans and the mitigation of imaging artifacts caused by patient motion. The existing approaches are based on single-modality MR-to-CT translation, with limited research exploring multimodal fusion. To address this limitation, we introduce Multi-modal MR to CT (MM2CT) translation method by leveraging multimodal T1- and T2-weighted MRI data, an innovative Mamba-based framework for multi-modal medical image synthesis. Mamba effectively overcomes the limited local receptive field in CNNs and the high computational complexity issues in Transformers. MM2CT leverages this advantage to maintain long-range dependencies modeling capabilities while achieving multi-modal MR feature integration. Additionally, we incorporate a dynamic local convolution module and a dynamic enhancement module to improve MRI-to-CT synthesis. The experiments on a public pelvis dataset demonstrate that MM2CT achieves state-of-the-art performance in terms of Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR). Our code is publicly available at https://github.com/Gots-ch/MM2CT.
Multimodal Causal-Driven Representation Learning for Generalizable Medical Image Segmentation
Aug 07, 2025Vision-Language Models (VLMs), such as CLIP, have demonstrated remarkable zero-shot capabilities in various computer vision tasks. However, their application to medical imaging remains challenging due to the high variability and complexity of medical data. Specifically, medical images often exhibit significant domain shifts caused by various confounders, including equipment differences, procedure artifacts, and imaging modes, which can lead to poor generalization when models are applied to unseen domains. To address this limitation, we propose Multimodal Causal-Driven Representation Learning (MCDRL), a novel framework that integrates causal inference with the VLM to tackle domain generalization in medical image segmentation. MCDRL is implemented in two steps: first, it leverages CLIP's cross-modal capabilities to identify candidate lesion regions and construct a confounder dictionary through text prompts, specifically designed to represent domain-specific variations; second, it trains a causal intervention network that utilizes this dictionary to identify and eliminate the influence of these domain-specific variations while preserving the anatomical structural information critical for segmentation tasks. Extensive experiments demonstrate that MCDRL consistently outperforms competing methods, yielding superior segmentation accuracy and exhibiting robust generalizability.
F2PASeg: Feature Fusion for Pituitary Anatomy Segmentation in Endoscopic Surgery
Aug 07, 2025Pituitary tumors often cause deformation or encapsulation of adjacent vital structures. Anatomical structure segmentation can provide surgeons with early warnings of regions that pose surgical risks, thereby enhancing the safety of pituitary surgery. However, pixel-level annotated video stream datasets for pituitary surgeries are extremely rare. To address this challenge, we introduce a new dataset for Pituitary Anatomy Segmentation (PAS). PAS comprises 7,845 time-coherent images extracted from 120 videos. To mitigate class imbalance, we apply data augmentation techniques that simulate the presence of surgical instruments in the training data. One major challenge in pituitary anatomy segmentation is the inconsistency in feature representation due to occlusions, camera motion, and surgical bleeding. By incorporating a Feature Fusion module, F2PASeg is proposed to refine anatomical structure segmentation by leveraging both high-resolution image features and deep semantic embeddings, enhancing robustness against intraoperative variations. Experimental results demonstrate that F2PASeg consistently segments critical anatomical structures in real time, providing a reliable solution for intraoperative pituitary surgery planning. Code: https://github.com/paulili08/F2PASeg.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025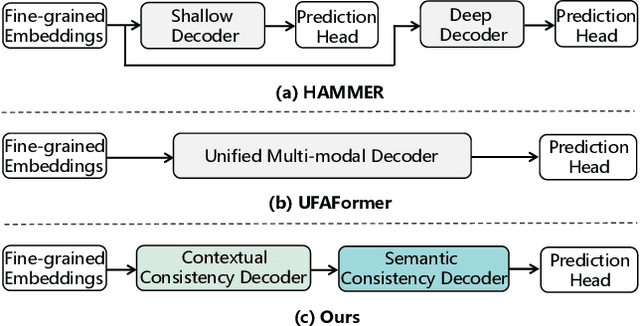
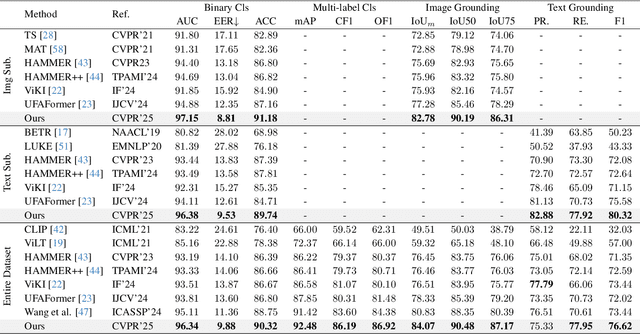
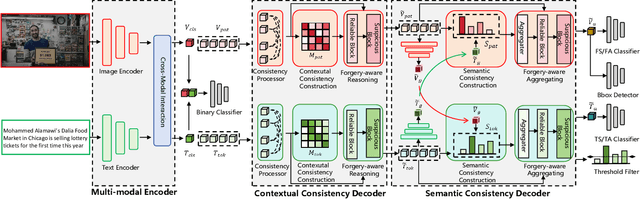
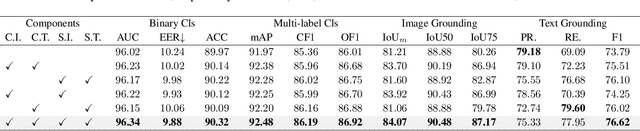
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.