 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
Shopping Companion: A Memory-Augmented LLM Agent for Real-World E-Commerce Tasks
Mar 16, 2026In e-commerce, LLM agents show promise for shopping tasks such as recommendations, budgeting, and bundle deals, where accurately capturing user preferences from long-term conversations is critical. However, two challenges hinder realizing this potential: (1) the absence of benchmarks for evaluating long-term preference-aware shopping tasks, and (2) the lack of end-to-end optimization due to existing designs that treat preference identification and shopping assistance as separate components. In this paper, we introduce a novel benchmark with a long-term memory setup, spanning two shopping tasks over 1.2 million real-world products, and propose Shopping Companion, a unified framework that jointly tackles memory retrieval and shopping assistance while supporting user intervention. To train such capabilities, we develop a dual-reward reinforcement learning strategy with tool-wise rewards to handle the sparse and discontinuous rewards inherent in multi-turn interactions. Experimental results demonstrate that even state-of-the-art models (such as GPT-5) achieve success rates under 70% on our benchmark, highlighting the significant challenges in this domain. Notably, our lightweight LLM, trained with Shopping Companion, consistently outperforms strong baselines, achieving better preference capture and task performance, which validates the effectiveness of our unified design.
VideoVeritas: AI-Generated Video Detection via Perception Pretext Reinforcement Learning
Feb 09, 2026The growing capability of video generation poses escalating security risks, making reliable detection increasingly essential. In this paper, we introduce VideoVeritas, a framework that integrates fine-grained perception and fact-based reasoning. We observe that while current multi-modal large language models (MLLMs) exhibit strong reasoning capacity, their granular perception ability remains limited. To mitigate this, we introduce Joint Preference Alignment and Perception Pretext Reinforcement Learning (PPRL). Specifically, rather than directly optimizing for detection task, we adopt general spatiotemporal grounding and self-supervised object counting in the RL stage, enhancing detection performance with simple perception pretext tasks. To facilitate robust evaluation, we further introduce MintVid, a light yet high-quality dataset containing 3K videos from 9 state-of-the-art generators, along with a real-world collected subset that has factual errors in content. Experimental results demonstrate that existing methods tend to bias towards either superficial reasoning or mechanical analysis, while VideoVeritas achieves more balanced performance across diverse benchmarks.
UniRS: Unifying Multi-temporal Remote Sensing Tasks through Vision Language Models
Dec 30, 2024



The domain gap between remote sensing imagery and natural images has recently received widespread attention and Vision-Language Models (VLMs) have demonstrated excellent generalization performance in remote sensing multimodal tasks. However, current research is still limited in exploring how remote sensing VLMs handle different types of visual inputs. To bridge this gap, we introduce \textbf{UniRS}, the first vision-language model \textbf{uni}fying multi-temporal \textbf{r}emote \textbf{s}ensing tasks across various types of visual input. UniRS supports single images, dual-time image pairs, and videos as input, enabling comprehensive remote sensing temporal analysis within a unified framework. We adopt a unified visual representation approach, enabling the model to accept various visual inputs. For dual-time image pair tasks, we customize a change extraction module to further enhance the extraction of spatiotemporal features. Additionally, we design a prompt augmentation mechanism tailored to the model's reasoning process, utilizing the prior knowledge of the general-purpose VLM to provide clues for UniRS. To promote multi-task knowledge sharing, the model is jointly fine-tuned on a mixed dataset. Experimental results show that UniRS achieves state-of-the-art performance across diverse tasks, including visual question answering, change captioning, and video scene classification, highlighting its versatility and effectiveness in unifying these multi-temporal remote sensing tasks. Our code and dataset will be released soon.
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agents
Jun 11, 2024



An increasing number of models have achieved great performance in remote sensing tasks with the recent development of Large Language Models (LLMs) and Visual Language Models (VLMs). However, these models are constrained to basic vision and language instruction-tuning tasks, facing challenges in complex remote sensing applications. Additionally, these models lack specialized expertise in professional domains. To address these limitations, we propose a LLM-driven remote sensing intelligent agent named RS-Agent. Firstly, RS-Agent is powered by a large language model (LLM) that acts as its "Central Controller," enabling it to understand and respond to various problems intelligently. Secondly, our RS-Agent integrates many high-performance remote sensing image processing tools, facilitating multi-tool and multi-turn conversations. Thirdly, our RS-Agent can answer professional questions by leveraging robust knowledge documents. We conducted experiments using several datasets, e.g., RSSDIVCS, RSVQA, and DOTAv1. The experimental results demonstrate that our RS-Agent delivers outstanding performance in many tasks, i.e., scene classification, visual question answering, and object counting tasks.
Mirror: A Universal Framework for Various Information Extraction Tasks
Nov 26, 2023



Sharing knowledge between information extraction tasks has always been a challenge due to the diverse data formats and task variations. Meanwhile, this divergence leads to information waste and increases difficulties in building complex applications in real scenarios. Recent studies often formulate IE tasks as a triplet extraction problem. However, such a paradigm does not support multi-span and n-ary extraction, leading to weak versatility. To this end, we reorganize IE problems into unified multi-slot tuples and propose a universal framework for various IE tasks, namely Mirror. Specifically, we recast existing IE tasks as a multi-span cyclic graph extraction problem and devise a non-autoregressive graph decoding algorithm to extract all spans in a single step. It is worth noting that this graph structure is incredibly versatile, and it supports not only complex IE tasks, but also machine reading comprehension and classification tasks. We manually construct a corpus containing 57 datasets for model pretraining, and conduct experiments on 30 datasets across 8 downstream tasks. The experimental results demonstrate that our model has decent compatibility and outperforms or reaches competitive performance with SOTA systems under few-shot and zero-shot settings. The code, model weights, and pretraining corpus are available at https://github.com/Spico197/Mirror .
CED: Catalog Extraction from Documents
Apr 28, 2023



Sentence-by-sentence information extraction from long documents is an exhausting and error-prone task. As the indicator of document skeleton, catalogs naturally chunk documents into segments and provide informative cascade semantics, which can help to reduce the search space. Despite their usefulness, catalogs are hard to be extracted without the assist from external knowledge. For documents that adhere to a specific template, regular expressions are practical to extract catalogs. However, handcrafted heuristics are not applicable when processing documents from different sources with diverse formats. To address this problem, we build a large manually annotated corpus, which is the first dataset for the Catalog Extraction from Documents (CED) task. Based on this corpus, we propose a transition-based framework for parsing documents into catalog trees. The experimental results demonstrate that our proposed method outperforms baseline systems and shows a good ability to transfer. We believe the CED task could fill the gap between raw text segments and information extraction tasks on extremely long documents. Data and code are available at \url{https://github.com/Spico197/CatalogExtraction}
Cascade Image Matting with Deformable Graph Refinement
May 08, 2021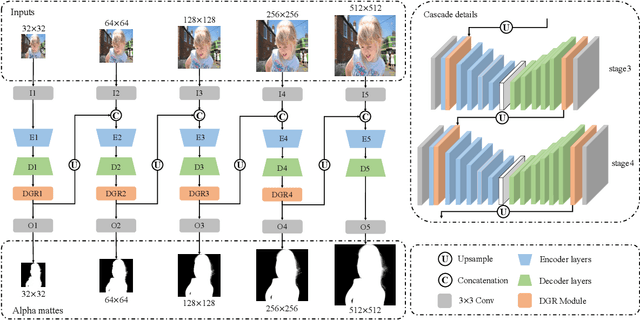
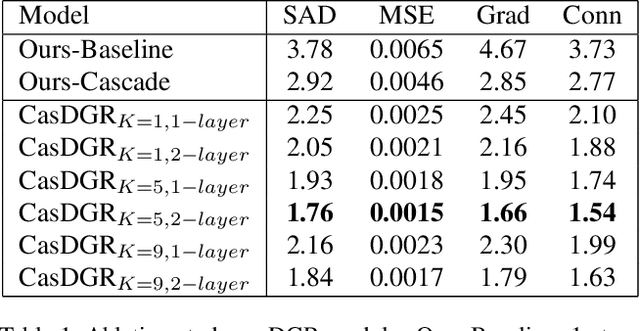
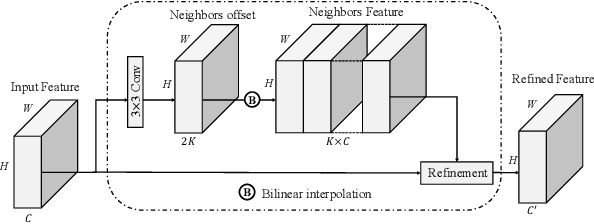
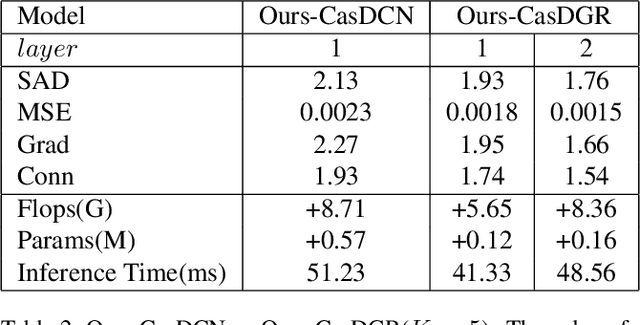
Image matting refers to the estimation of the opacity of foreground objects. It requires correct contours and fine details of foreground objects for the matting results. To better accomplish human image matting tasks, we propose the Cascade Image Matting Network with Deformable Graph Refinement, which can automatically predict precise alpha mattes from single human images without any additional inputs. We adopt a network cascade architecture to perform matting from low-to-high resolution, which corresponds to coarse-to-fine optimization. We also introduce the Deformable Graph Refinement (DGR) module based on graph neural networks (GNNs) to overcome the limitations of convolutional neural networks (CNNs). The DGR module can effectively capture long-range relations and obtain more global and local information to help produce finer alpha mattes. We also reduce the computation complexity of the DGR module by dynamically predicting the neighbors and apply DGR module to higher--resolution features. Experimental results demonstrate the ability of our CasDGR to achieve state-of-the-art performance on synthetic datasets and produce good results on real human images.