 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBachGAN: High-Resolution Image Synthesis from Salient Object Layout
Mar 27, 2020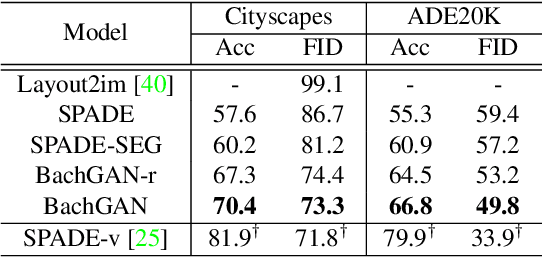
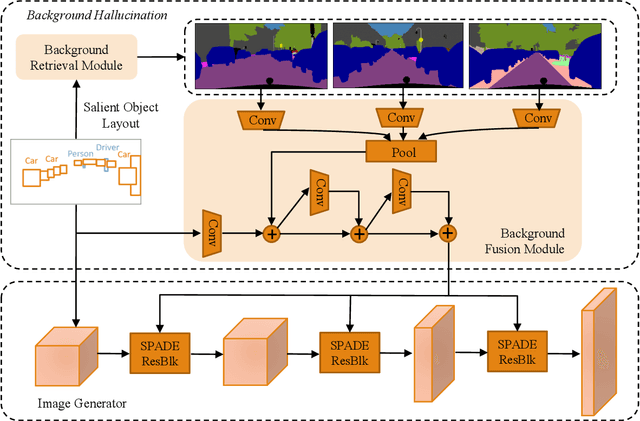


We propose a new task towards more practical application for image generation - high-quality image synthesis from salient object layout. This new setting allows users to provide the layout of salient objects only (i.e., foreground bounding boxes and categories), and lets the model complete the drawing with an invented background and a matching foreground. Two main challenges spring from this new task: (i) how to generate fine-grained details and realistic textures without segmentation map input; and (ii) how to create a background and weave it seamlessly into standalone objects. To tackle this, we propose Background Hallucination Generative Adversarial Network (BachGAN), which first selects a set of segmentation maps from a large candidate pool via a background retrieval module, then encodes these candidate layouts via a background fusion module to hallucinate a suitable background for the given objects. By generating the hallucinated background representation dynamically, our model can synthesize high-resolution images with both photo-realistic foreground and integral background. Experiments on Cityscapes and ADE20K datasets demonstrate the advantage of BachGAN over existing methods, measured on both visual fidelity of generated images and visual alignment between output images and input layouts.
VIOLIN: A Large-Scale Dataset for Video-and-Language Inference
Mar 25, 2020

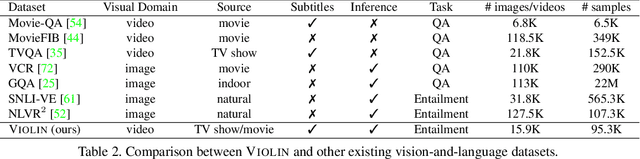
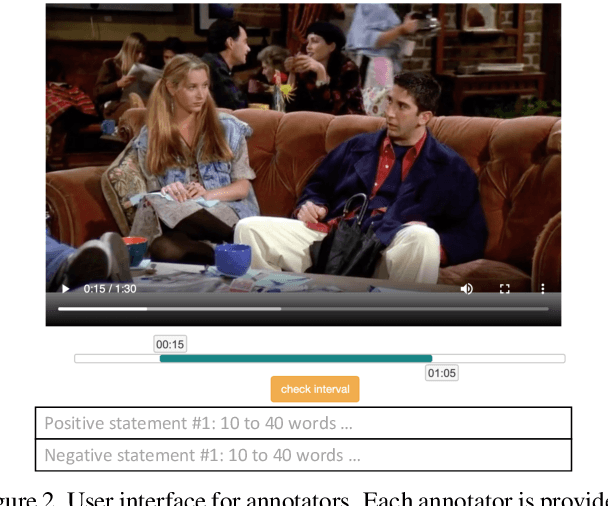
We introduce a new task, Video-and-Language Inference, for joint multimodal understanding of video and text. Given a video clip with aligned subtitles as premise, paired with a natural language hypothesis based on the video content, a model needs to infer whether the hypothesis is entailed or contradicted by the given video clip. A new large-scale dataset, named Violin (VIdeO-and-Language INference), is introduced for this task, which consists of 95,322 video-hypothesis pairs from 15,887 video clips, spanning over 582 hours of video. These video clips contain rich content with diverse temporal dynamics, event shifts, and people interactions, collected from two sources: (i) popular TV shows, and (ii) movie clips from YouTube channels. In order to address our new multimodal inference task, a model is required to possess sophisticated reasoning skills, from surface-level grounding (e.g., identifying objects and characters in the video) to in-depth commonsense reasoning (e.g., inferring causal relations of events in the video). We present a detailed analysis of the dataset and an extensive evaluation over many strong baselines, providing valuable insights on the challenges of this new task.
Nested-Wasserstein Self-Imitation Learning for Sequence Generation
Jan 20, 2020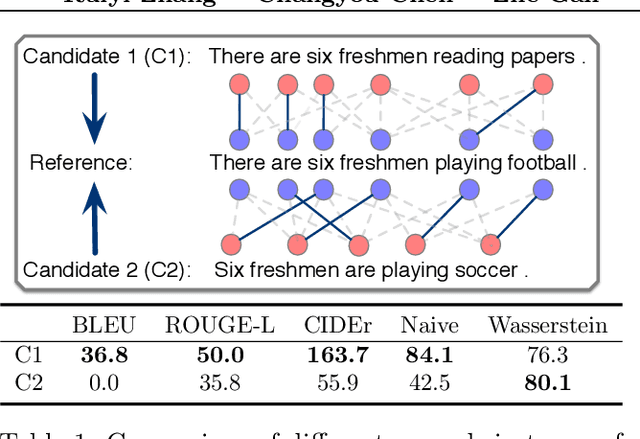
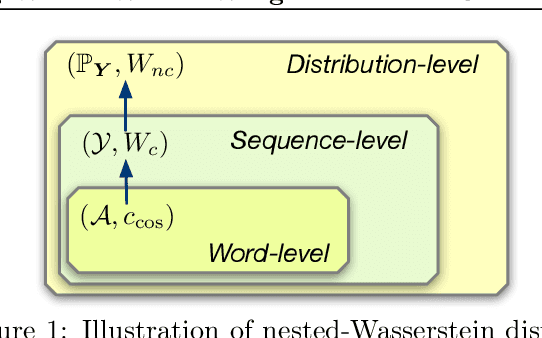
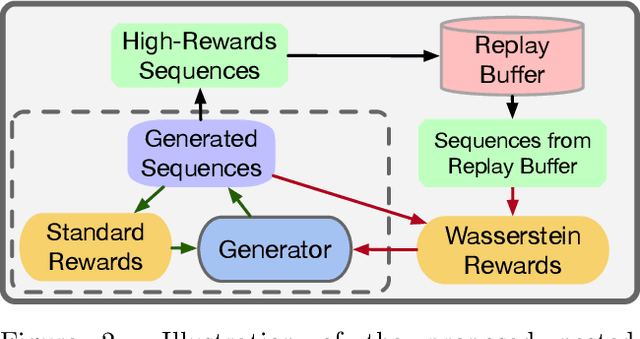
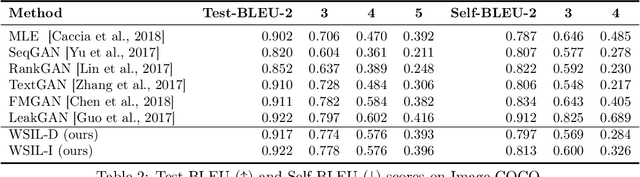
Reinforcement learning (RL) has been widely studied for improving sequence-generation models. However, the conventional rewards used for RL training typically cannot capture sufficient semantic information and therefore render model bias. Further, the sparse and delayed rewards make RL exploration inefficient. To alleviate these issues, we propose the concept of nested-Wasserstein distance for distributional semantic matching. To further exploit it, a novel nested-Wasserstein self-imitation learning framework is developed, encouraging the model to exploit historical high-rewarded sequences for enhanced exploration and better semantic matching. Our solution can be understood as approximately executing proximal policy optimization with Wasserstein trust-regions. Experiments on a variety of unconditional and conditional sequence-generation tasks demonstrate the proposed approach consistently leads to improved performance.
Graph-Driven Generative Models for Heterogeneous Multi-Task Learning
Nov 20, 2019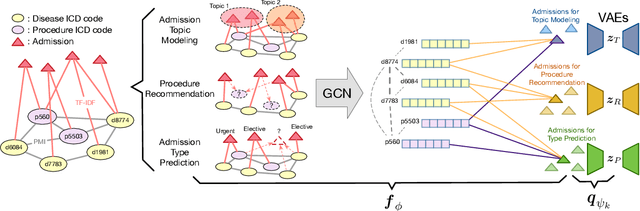

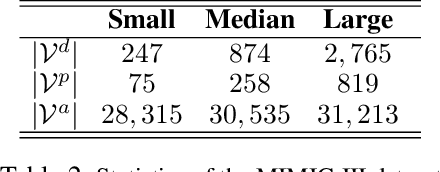

We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.
Meta Module Network for Compositional Visual Reasoning
Nov 18, 2019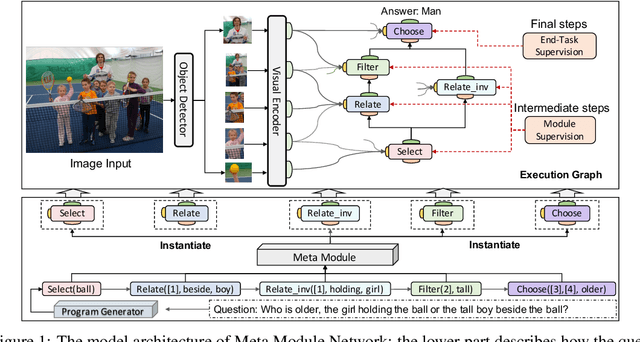
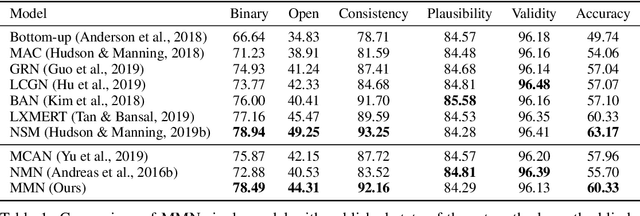
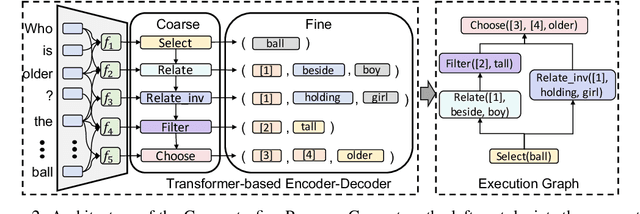
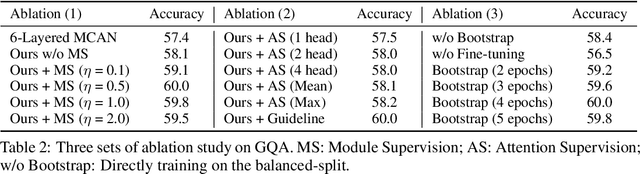
There are two main lines of research on visual reasoning: neural module network (NMN) with explicit multi-hop reasoning through handcrafted neural modules, and monolithic network with implicit reasoning in the latent feature space. The former excels in interpretability and compositionality, while the latter usually achieves better performance due to model flexibility and parameter efficiency. In order to bridge the gap between the two and leverage the merits of both, we present Meta Module Network (MMN), a novel hybrid approach that can utilize a Meta Module to perform versatile functionalities, while preserving compositionality and interpretability through modularized design. The proposed model first parses an input question into a functional program through a Program Generator. Instead of handcrafting a task-specific network to represent each function similar to traditional NMN, we propose a Meta Module, which can read a recipe (function specifications) to dynamically instantiate the task-specific Instance Modules for compositional reasoning. To endow different instance modules with designated functionalities, we design a symbolic teacher which can execute against provided scene graphs to generate guidelines for the instantiated modules (student) to follow during training. Experiments conducted on the GQA benchmark demonstrates that MMN outperforms both NMN and monolithic network baselines, with good generalization ability to handle unseen functions.
Distilling the Knowledge of BERT for Text Generation
Nov 10, 2019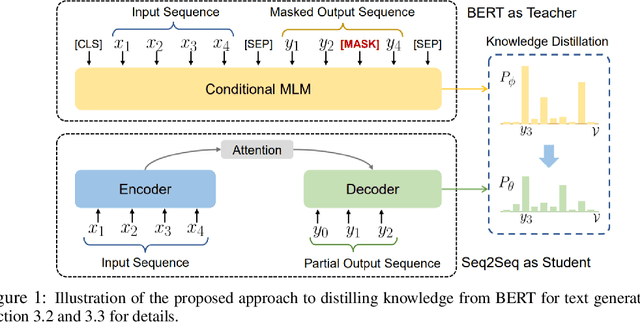
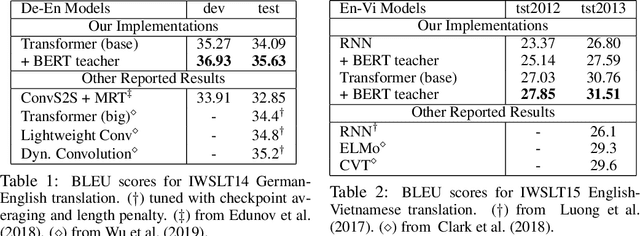
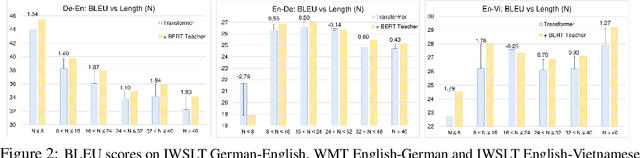
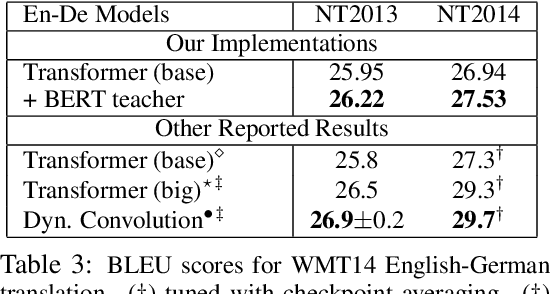
Large-scale pre-trained language model, such as BERT, has recently achieved great success in a wide range of language understanding tasks. However, it remains an open question how to utilize BERT for text generation tasks. In this paper, we present a novel approach to addressing this challenge in a generic sequence-to-sequence (Seq2Seq) setting. We first propose a new task, Conditional Masked Language Modeling (C-MLM), to enable fine-tuning of BERT on target text-generation dataset. The fine-tuned BERT (i.e., teacher) is then exploited as extra supervision to improve conventional Seq2Seq models (i.e., student) for text generation. By leveraging BERT's idiosyncratic bidirectional nature, distilling the knowledge learned from BERT can encourage auto-regressive Seq2Seq models to plan ahead, imposing global sequence-level supervision for coherent text generation. Experiments show that the proposed approach significantly outperforms strong baselines of Transformer on multiple text generation tasks, including machine translation (MT) and text summarization. Our proposed model also achieves new state-of-the-art results on the IWSLT German-English and English-Vietnamese MT datasets.
Hierarchical Graph Network for Multi-hop Question Answering
Nov 09, 2019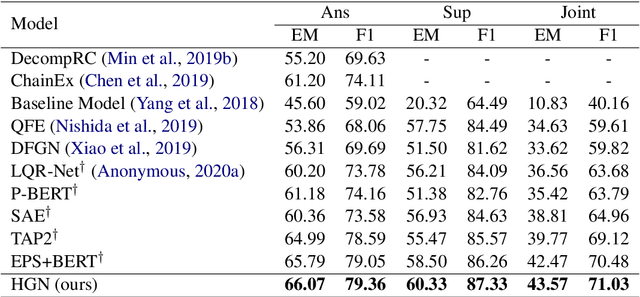
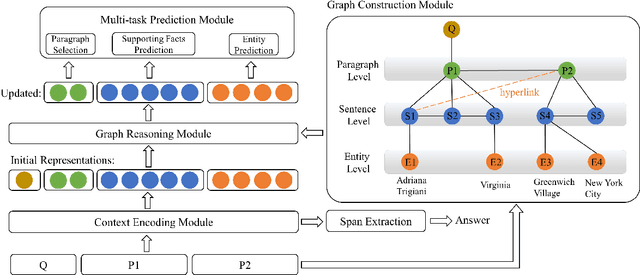
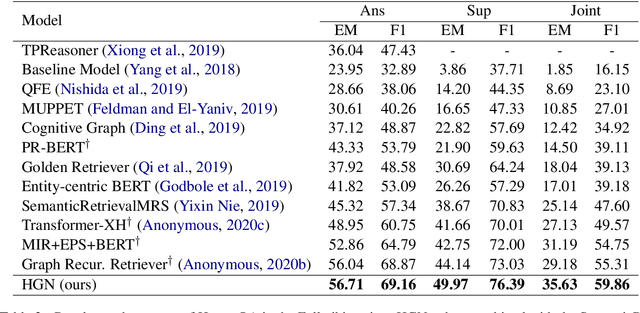
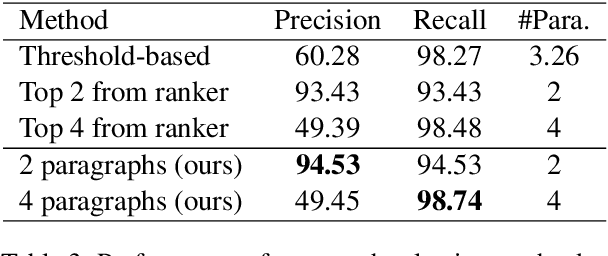
In this paper, we present Hierarchical Graph Network (HGN) for multi-hop question answering. To aggregate clues from scattered texts across multiple paragraphs, a hierarchical graph is created by constructing nodes from different levels of granularity (i.e., questions, paragraphs, sentences, and entities), the representations of which are initialized with BERT-based context encoders. By weaving heterogeneous nodes in an integral unified graph, this characteristic hierarchical differentiation of node granularity enables HGN to support different question answering sub-tasks simultaneously (e.g., paragraph selection, supporting facts extraction, and answer prediction). Given a constructed hierarchical graph for each question, the initial node representations are updated through graph propagation; and for each sub-task, multi-hop reasoning is performed by traversing through graph edges. Extensive experiments on the HotpotQA benchmark demonstrate that the proposed HGN approach significantly outperforms prior state-of-the-art methods by a large margin in both Distractor and Fullwiki settings.
Discourse-Aware Neural Extractive Model for Text Summarization
Oct 30, 2019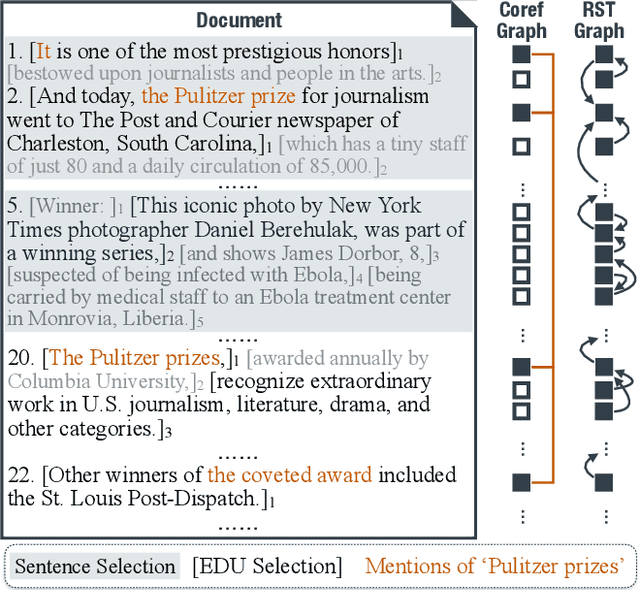
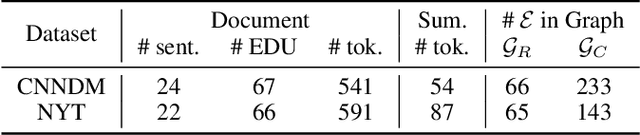
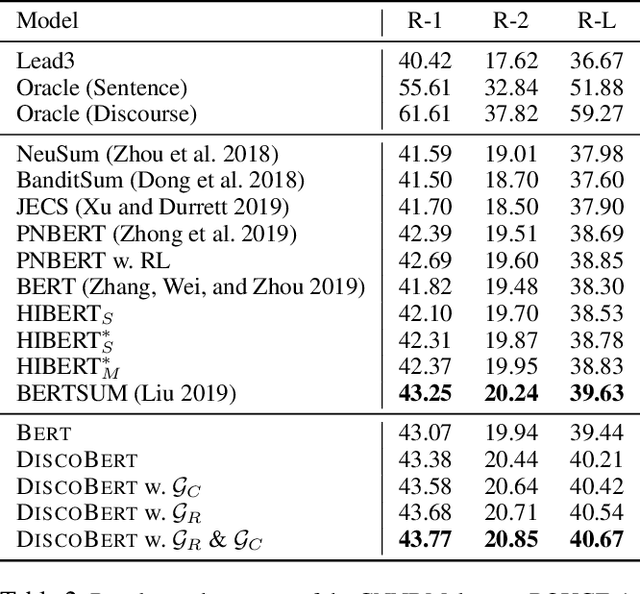
Recently BERT has been adopted in state-of-the-art text summarization models for document encoding. However, such BERT-based extractive models use the sentence as the minimal selection unit, which often results in redundant or uninformative phrases in the generated summaries. As BERT is pre-trained on sentence pairs, not documents, the long-range dependencies between sentences are not well captured. To address these issues, we present a graph-based discourse-aware neural summarization model - DiscoBert. By utilizing discourse segmentation to extract discourse units (instead of sentences) as candidates, DiscoBert provides a fine-grained granularity for extractive selection, which helps reduce redundancy in extracted summaries. Based on this, two discourse graphs are further proposed: ($i$) RST Graph based on RST discourse trees; and ($ii$) Coreference Graph based on coreference mentions in the document. DiscoBert first encodes the extracted discourse units with BERT, and then uses a graph convolutional network to capture the long-range dependencies among discourse units through the constructed graphs. Experimental results on two popular summarization datasets demonstrate that DiscoBert outperforms state-of-the-art methods by a significant margin.
FreeLB: Enhanced Adversarial Training for Language Understanding
Oct 05, 2019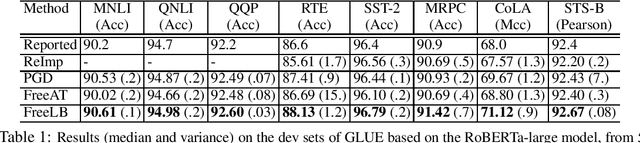
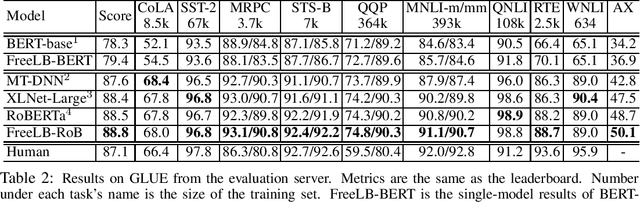
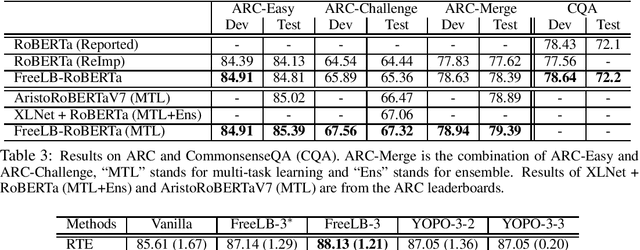

Adversarial training, which minimizes the maximal risk for label-preserving input perturbations, has proved to be effective for improving the generalization of language models. In this work, we propose a novel adversarial training algorithm - FreeLB, that promotes higher robustness and invariance in the embedding space, by adding adversarial perturbations to word embeddings and minimizing the resultant adversarial risk inside different regions around input samples. To validate the effectiveness of the proposed approach, we apply it to Transformer-based models for natural language understanding and commonsense reasoning tasks. Experiments on the GLUE benchmark show that when applied only to the finetuning stage, it is able to improve the overall test scores of BERT-based model from 78.3 to 79.4, and RoBERTa-large model from 88.5 to 88.8. In addition, the proposed approach achieves state-of-the-art single-model test accuracies of 85.44% and 67.75% on ARC-Easy and ARC-Challenge. Experiments on CommonsenseQA benchmark further demonstrate that FreeLB can be generalized and boost the performance of RoBERTa-large model on other tasks as well.
Improving Textual Network Learning with Variational Homophilic Embeddings
Sep 30, 2019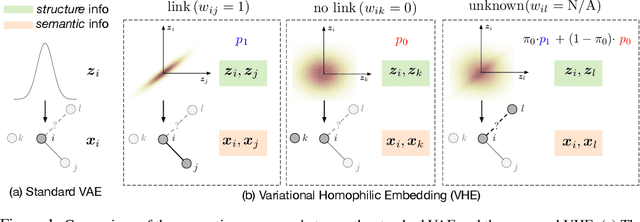
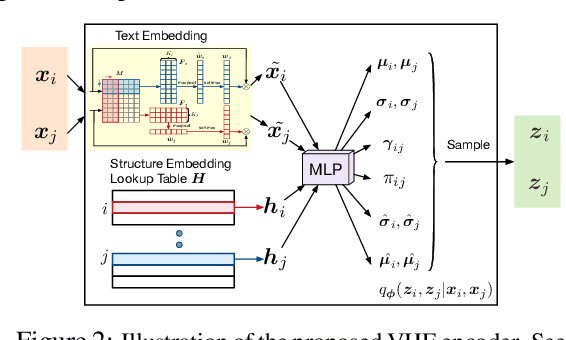
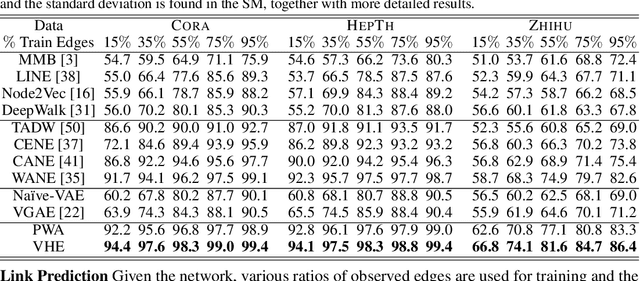
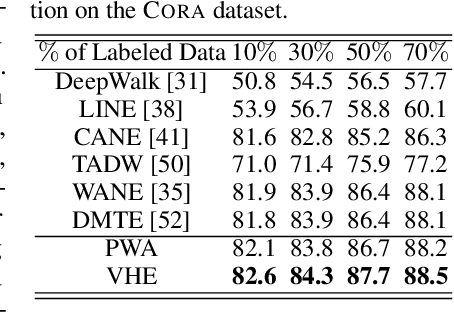
The performance of many network learning applications crucially hinges on the success of network embedding algorithms, which aim to encode rich network information into low-dimensional vertex-based vector representations. This paper considers a novel variational formulation of network embeddings, with special focus on textual networks. Different from most existing methods that optimize a discriminative objective, we introduce Variational Homophilic Embedding (VHE), a fully generative model that learns network embeddings by modeling the semantic (textual) information with a variational autoencoder, while accounting for the structural (topology) information through a novel homophilic prior design. Homophilic vertex embeddings encourage similar embedding vectors for related (connected) vertices. The proposed VHE promises better generalization for downstream tasks, robustness to incomplete observations, and the ability to generalize to unseen vertices. Extensive experiments on real-world networks, for multiple tasks, demonstrate that the proposed method consistently achieves superior performance relative to competing state-of-the-art approaches.