 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDance Dance Generation: Motion Transfer for Internet Videos
Mar 30, 2019
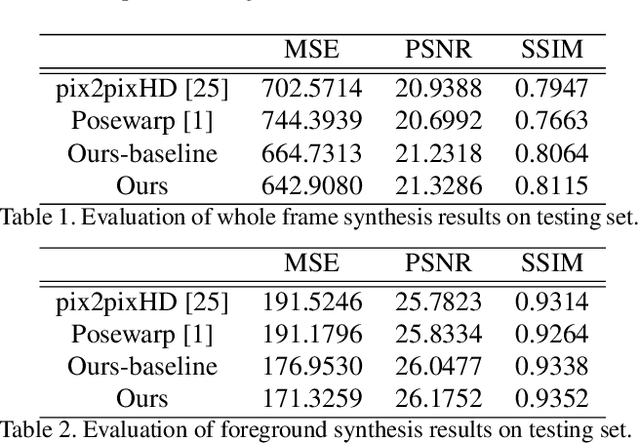

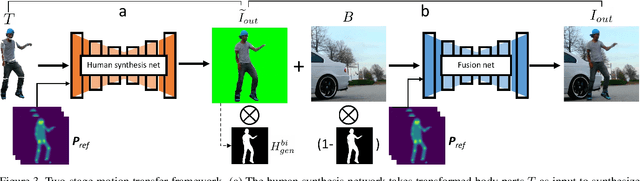
This work presents computational methods for transferring body movements from one person to another with videos collected in the wild. Specifically, we train a personalized model on a single video from the Internet which can generate videos of this target person driven by the motions of other people. Our model is built on two generative networks: a human (foreground) synthesis net which generates photo-realistic imagery of the target person in a novel pose, and a fusion net which combines the generated foreground with the scene (background), adding shadows or reflections as needed to enhance realism. We validate the the efficacy of our proposed models over baselines with qualitative and quantitative evaluations as well as a subjective test.
Image Super-Resolution by Neural Texture Transfer
Mar 06, 2019
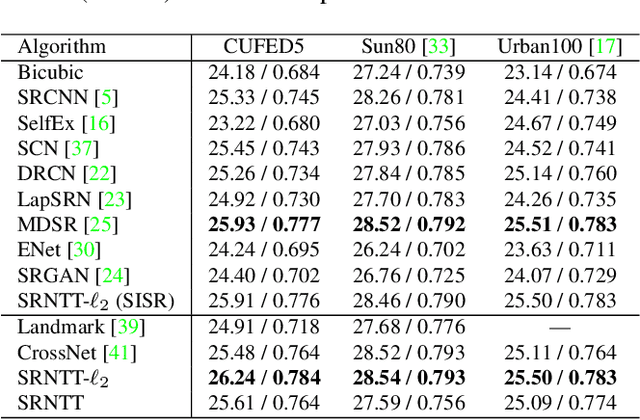
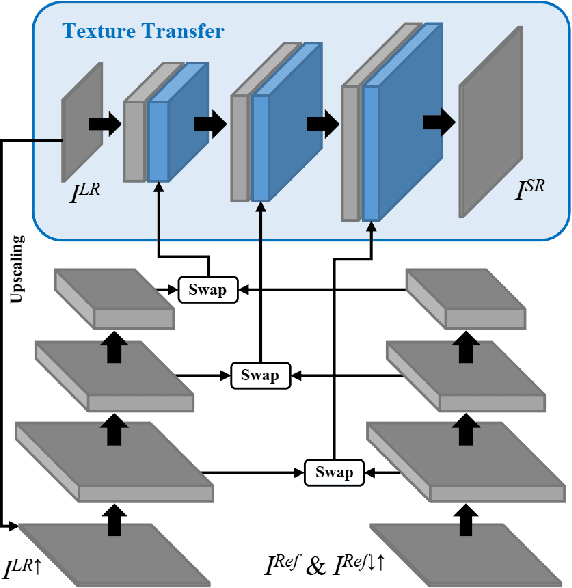

Due to the significant information loss in low-resolution (LR) images, it has become extremely challenging to further advance the state-of-the-art of single image super-resolution (SISR). Reference-based super-resolution (RefSR), on the other hand, has proven to be promising in recovering high-resolution (HR) details when a reference (Ref) image with similar content as that of the LR input is given. However, the quality of RefSR can degrade severely when Ref is less similar. This paper aims to unleash the potential of RefSR by leveraging more texture details from Ref images with stronger robustness even when irrelevant Ref images are provided. Inspired by the recent work on image stylization, we formulate the RefSR problem as neural texture transfer. We design an end-to-end deep model which enriches HR details by adaptively transferring the texture from Ref images according to their textural similarity. Instead of matching content in the raw pixel space as done by previous methods, our key contribution is a multi-level matching conducted in the neural space. This matching scheme facilitates multi-scale neural transfer that allows the model to benefit more from those semantically related Ref patches, and gracefully degrade to SISR performance on the least relevant Ref inputs. We build a benchmark dataset for the general research of RefSR, which contains Ref images paired with LR inputs with varying levels of similarity. Both quantitative and qualitative evaluations demonstrate the superiority of our method over state-of-the-art.
Visual Font Pairing
Nov 19, 2018
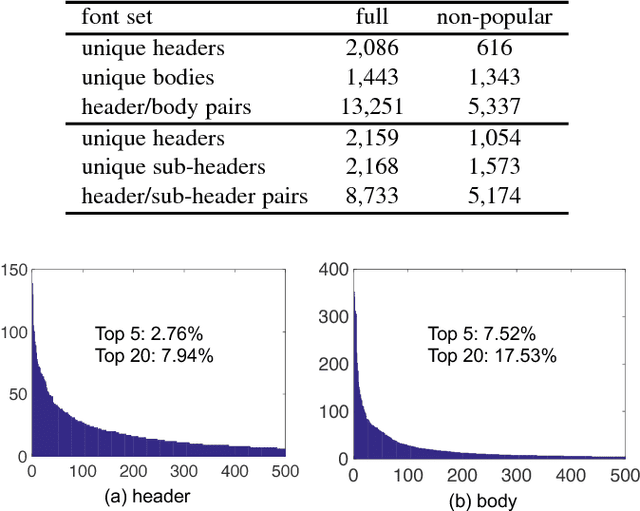

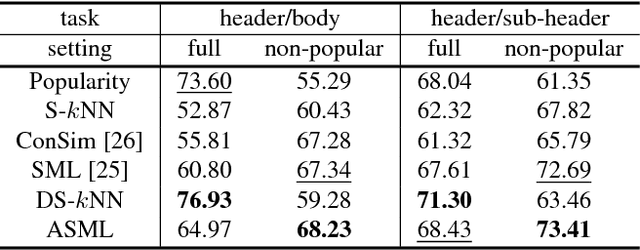
This paper introduces the problem of automatic font pairing. Font pairing is an important design task that is difficult for novices. Given a font selection for one part of a document (e.g., header), our goal is to recommend a font to be used in another part (e.g., body) such that the two fonts used together look visually pleasing. There are three main challenges in font pairing. First, this is a fine-grained problem, in which the subtle distinctions between fonts may be important. Second, rules and conventions of font pairing given by human experts are difficult to formalize. Third, font pairing is an asymmetric problem in that the roles played by header and body fonts are not interchangeable. To address these challenges, we propose automatic font pairing through learning visual relationships from large-scale human-generated font pairs. We introduce a new database for font pairing constructed from millions of PDF documents available on the Internet. We propose two font pairing algorithms: dual-space k-NN and asymmetric similarity metric learning (ASML). These two methods automatically learn fine-grained relationships from large-scale data. We also investigate several baseline methods based on the rules from professional designers. Experiments and user studies demonstrate the effectiveness of our proposed dataset and methods.
Learning to Sketch with Deep Q Networks and Demonstrated Strokes
Oct 14, 2018


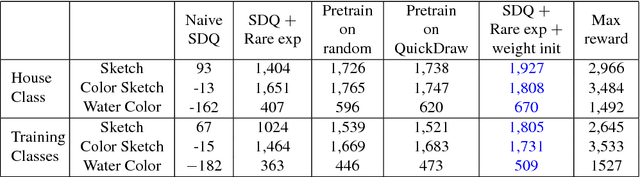
Doodling is a useful and common intelligent skill that people can learn and master. In this work, we propose a two-stage learning framework to teach a machine to doodle in a simulated painting environment via Stroke Demonstration and deep Q-learning (SDQ). The developed system, Doodle-SDQ, generates a sequence of pen actions to reproduce a reference drawing and mimics the behavior of human painters. In the first stage, it learns to draw simple strokes by imitating in supervised fashion from a set of strokeaction pairs collected from artist paintings. In the second stage, it is challenged to draw real and more complex doodles without ground truth actions; thus, it is trained with Qlearning. Our experiments confirm that (1) doodling can be learned without direct stepby- step action supervision and (2) pretraining with stroke demonstration via supervised learning is important to improve performance. We further show that Doodle-SDQ is effective at producing plausible drawings in different media types, including sketch and watercolor.
Wide Activation for Efficient and Accurate Image Super-Resolution
Aug 27, 2018
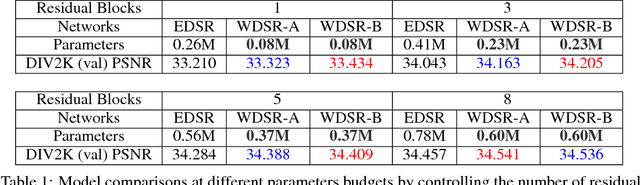

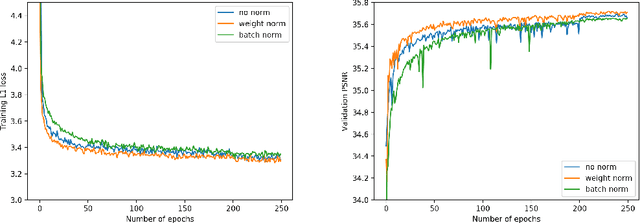
In this report we demonstrate that with same parameters and computational budgets, models with wider features before ReLU activation have significantly better performance for single image super-resolution (SISR). The resulted SR residual network has a slim identity mapping pathway with wider (\(2\times\) to \(4\times\)) channels before activation in each residual block. To further widen activation (\(6\times\) to \(9\times\)) without computational overhead, we introduce linear low-rank convolution into SR networks and achieve even better accuracy-efficiency tradeoffs. In addition, compared with batch normalization or no normalization, we find training with weight normalization leads to better accuracy for deep super-resolution networks. Our proposed SR network \textit{WDSR} achieves better results on large-scale DIV2K image super-resolution benchmark in terms of PSNR with same or lower computational complexity. Based on WDSR, our method also won 1st places in NTIRE 2018 Challenge on Single Image Super-Resolution in all three realistic tracks. Experiments and ablation studies support the importance of wide activation for image super-resolution. Code is released at: https://github.com/JiahuiYu/wdsr_ntire2018
Flow-Grounded Spatial-Temporal Video Prediction from Still Images
Aug 26, 2018

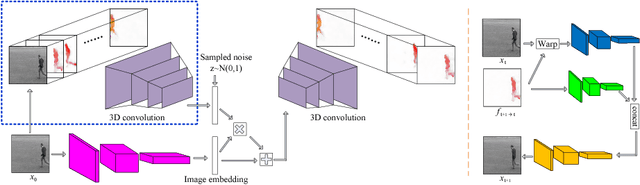

Existing video prediction methods mainly rely on observing multiple historical frames or focus on predicting the next one-frame. In this work, we study the problem of generating consecutive multiple future frames by observing one single still image only. We formulate the multi-frame prediction task as a multiple time step flow (multi-flow) prediction phase followed by a flow-to-frame synthesis phase. The multi-flow prediction is modeled in a variational probabilistic manner with spatial-temporal relationships learned through 3D convolutions. The flow-to-frame synthesis is modeled as a generative process in order to keep the predicted results lying closer to the manifold shape of real video sequence. Such a two-phase design prevents the model from directly looking at the high-dimensional pixel space of the frame sequence and is demonstrated to be more effective in predicting better and diverse results. Extensive experimental results on videos with different types of motion show that the proposed algorithm performs favorably against existing methods in terms of quality, diversity and human perceptual evaluation.
"Factual" or "Emotional": Stylized Image Captioning with Adaptive Learning and Attention
Jul 29, 2018
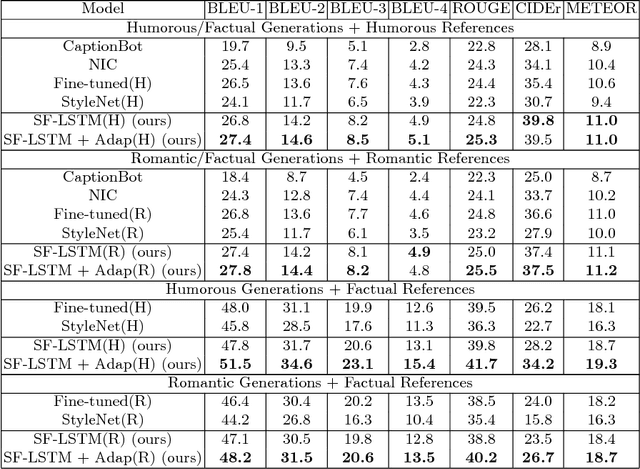
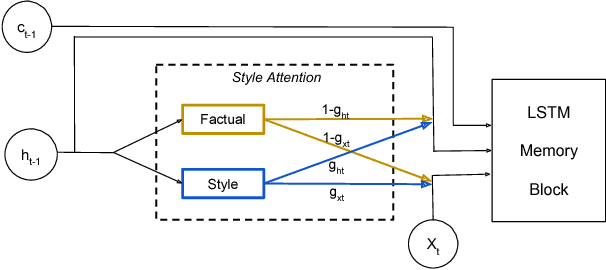
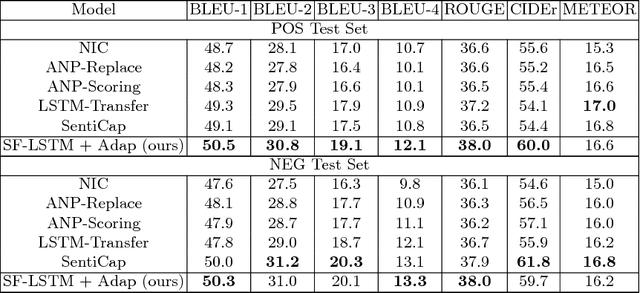
Generating stylized captions for an image is an emerging topic in image captioning. Given an image as input, it requires the system to generate a caption that has a specific style (e.g., humorous, romantic, positive, and negative) while describing the image content semantically accurately. In this paper, we propose a novel stylized image captioning model that effectively takes both requirements into consideration. To this end, we first devise a new variant of LSTM, named style-factual LSTM, as the building block of our model. It uses two groups of matrices to capture the factual and stylized knowledge, respectively, and automatically learns the word-level weights of the two groups based on previous context. In addition, when we train the model to capture stylized elements, we propose an adaptive learning approach based on a reference factual model, it provides factual knowledge to the model as the model learns from stylized caption labels, and can adaptively compute how much information to supply at each time step. We evaluate our model on two stylized image captioning datasets, which contain humorous/romantic captions and positive/negative captions, respectively. Experiments shows that our proposed model outperforms the state-of-the-art approaches, without using extra ground truth supervision.
Towards Privacy-Preserving Visual Recognition via Adversarial Training: A Pilot Study
Jul 22, 2018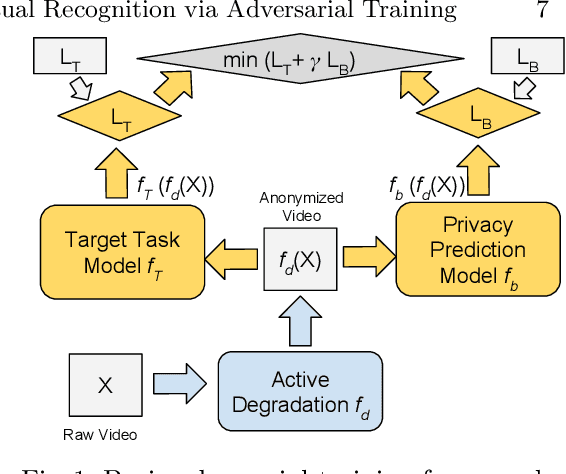
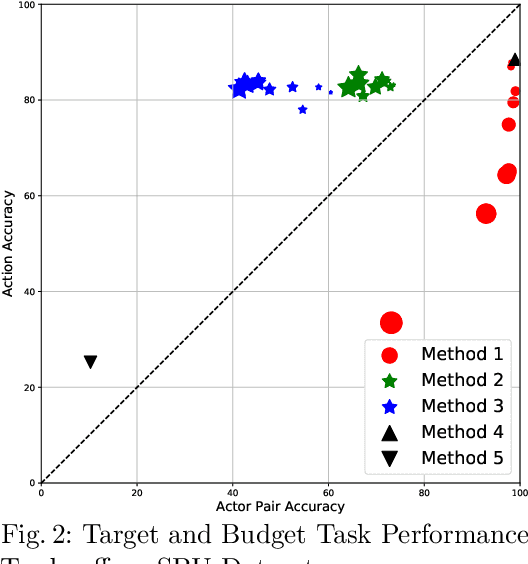
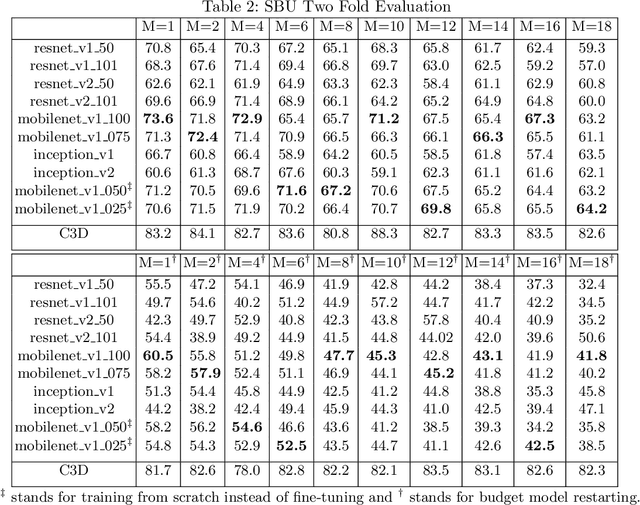
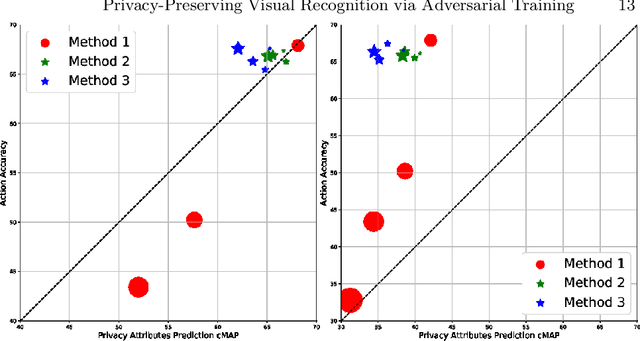
This paper aims to improve privacy-preserving visual recognition, an increasingly demanded feature in smart camera applications, by formulating a unique adversarial training framework. The proposed framework explicitly learns a degradation transform for the original video inputs, in order to optimize the trade-off between target task performance and the associated privacy budgets on the degraded video. A notable challenge is that the privacy budget, often defined and measured in task-driven contexts, cannot be reliably indicated using any single model performance, because a strong protection of privacy has to sustain against any possible model that tries to hack privacy information. Such an uncommon situation has motivated us to propose two strategies, i.e., budget model restarting and ensemble, to enhance the generalization of the learned degradation on protecting privacy against unseen hacker models. Novel training strategies, evaluation protocols, and result visualization methods have been designed accordingly. Two experiments on privacy-preserving action recognition, with privacy budgets defined in various ways, manifest the compelling effectiveness of the proposed framework in simultaneously maintaining high target task (action recognition) performance while suppressing the privacy breach risk.
Visual to Sound: Generating Natural Sound for Videos in the Wild
Jun 01, 2018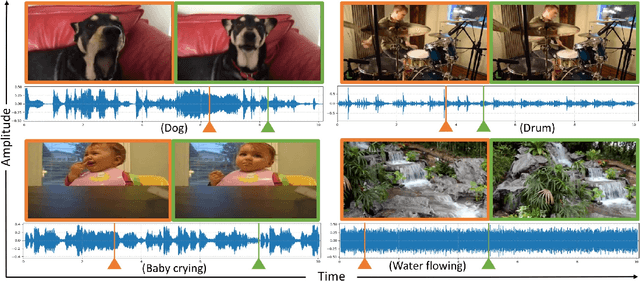

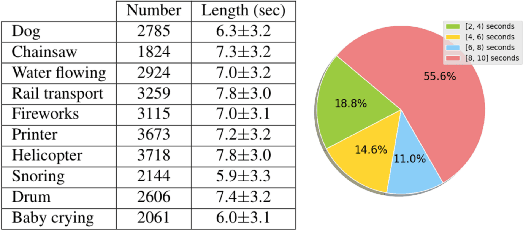
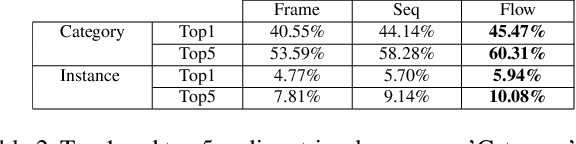
As two of the five traditional human senses (sight, hearing, taste, smell, and touch), vision and sound are basic sources through which humans understand the world. Often correlated during natural events, these two modalities combine to jointly affect human perception. In this paper, we pose the task of generating sound given visual input. Such capabilities could help enable applications in virtual reality (generating sound for virtual scenes automatically) or provide additional accessibility to images or videos for people with visual impairments. As a first step in this direction, we apply learning-based methods to generate raw waveform samples given input video frames. We evaluate our models on a dataset of videos containing a variety of sounds (such as ambient sounds and sounds from people/animals). Our experiments show that the generated sounds are fairly realistic and have good temporal synchronization with the visual inputs.
Speeding up Context-based Sentence Representation Learning with Non-autoregressive Convolutional Decoding
Jun 01, 2018
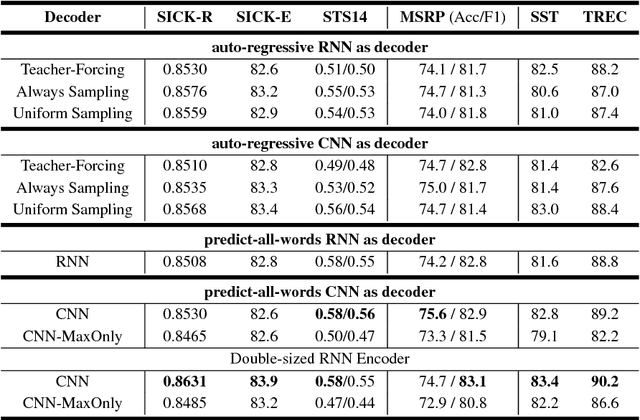
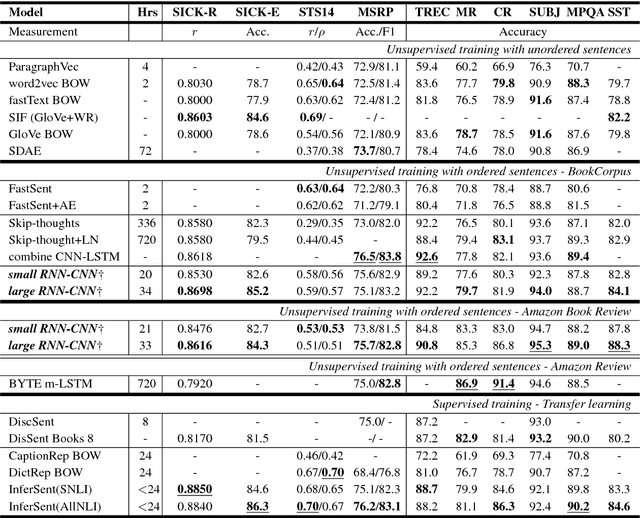
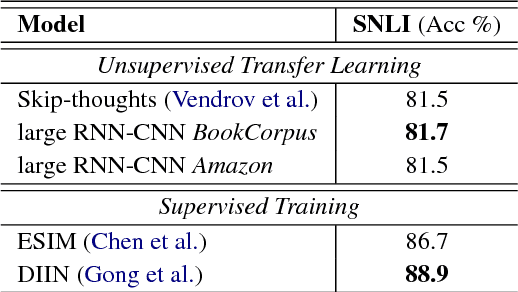
Context plays an important role in human language understanding, thus it may also be useful for machines learning vector representations of language. In this paper, we explore an asymmetric encoder-decoder structure for unsupervised context-based sentence representation learning. We carefully designed experiments to show that neither an autoregressive decoder nor an RNN decoder is required. After that, we designed a model which still keeps an RNN as the encoder, while using a non-autoregressive convolutional decoder. We further combine a suite of effective designs to significantly improve model efficiency while also achieving better performance. Our model is trained on two different large unlabelled corpora, and in both cases the transferability is evaluated on a set of downstream NLP tasks. We empirically show that our model is simple and fast while producing rich sentence representations that excel in downstream tasks.