 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualVector: Unsupervised Vector Font Synthesis with Dual-Part Representation
May 17, 2023



Automatic generation of fonts can be an important aid to typeface design. Many current approaches regard glyphs as pixelated images, which present artifacts when scaling and inevitable quality losses after vectorization. On the other hand, existing vector font synthesis methods either fail to represent the shape concisely or require vector supervision during training. To push the quality of vector font synthesis to the next level, we propose a novel dual-part representation for vector glyphs, where each glyph is modeled as a collection of closed "positive" and "negative" path pairs. The glyph contour is then obtained by boolean operations on these paths. We first learn such a representation only from glyph images and devise a subsequent contour refinement step to align the contour with an image representation to further enhance details. Our method, named DualVector, outperforms state-of-the-art methods in vector font synthesis both quantitatively and qualitatively. Our synthesized vector fonts can be easily converted to common digital font formats like TrueType Font for practical use. The code is released at https://github.com/thuliu-yt16/dualvector.
Improving Diffusion Models for Scene Text Editing with Dual Encoders
Apr 12, 2023



Scene text editing is a challenging task that involves modifying or inserting specified texts in an image while maintaining its natural and realistic appearance. Most previous approaches to this task rely on style-transfer models that crop out text regions and feed them into image transfer models, such as GANs. However, these methods are limited in their ability to change text style and are unable to insert texts into images. Recent advances in diffusion models have shown promise in overcoming these limitations with text-conditional image editing. However, our empirical analysis reveals that state-of-the-art diffusion models struggle with rendering correct text and controlling text style. To address these problems, we propose DIFFSTE to improve pre-trained diffusion models with a dual encoder design, which includes a character encoder for better text legibility and an instruction encoder for better style control. An instruction tuning framework is introduced to train our model to learn the mapping from the text instruction to the corresponding image with either the specified style or the style of the surrounding texts in the background. Such a training method further brings our method the zero-shot generalization ability to the following three scenarios: generating text with unseen font variation, e.g., italic and bold, mixing different fonts to construct a new font, and using more relaxed forms of natural language as the instructions to guide the generation task. We evaluate our approach on five datasets and demonstrate its superior performance in terms of text correctness, image naturalness, and style controllability. Our code is publicly available. https://github.com/UCSB-NLP-Chang/DiffSTE
Align and Attend: Multimodal Summarization with Dual Contrastive Losses
Mar 13, 2023The goal of multimodal summarization is to extract the most important information from different modalities to form summaries. Unlike unimodal summarization, the multimodal summarization task explicitly leverages cross-modal information to help generate more reliable and high-quality summaries. However, existing methods fail to leverage the temporal correspondence between different modalities and ignore the intrinsic correlation between different samples. To address this issue, we introduce Align and Attend Multimodal Summarization (A2Summ), a unified multimodal transformer-based model which can effectively align and attend the multimodal input. In addition, we propose two novel contrastive losses to model both inter-sample and intra-sample correlations. Extensive experiments on two standard video summarization datasets (TVSum and SumMe) and two multimodal summarization datasets (Daily Mail and CNN) demonstrate the superiority of A2Summ, achieving state-of-the-art performances on all datasets. Moreover, we collected a large-scale multimodal summarization dataset BLiSS, which contains livestream videos and transcribed texts with annotated summaries. Our code and dataset are publicly available at ~\url{https://boheumd.github.io/A2Summ/}.
LiveSeg: Unsupervised Multimodal Temporal Segmentation of Long Livestream Videos
Oct 12, 2022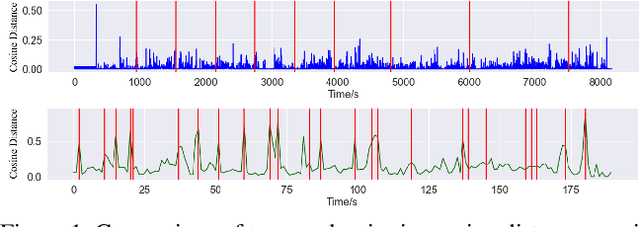
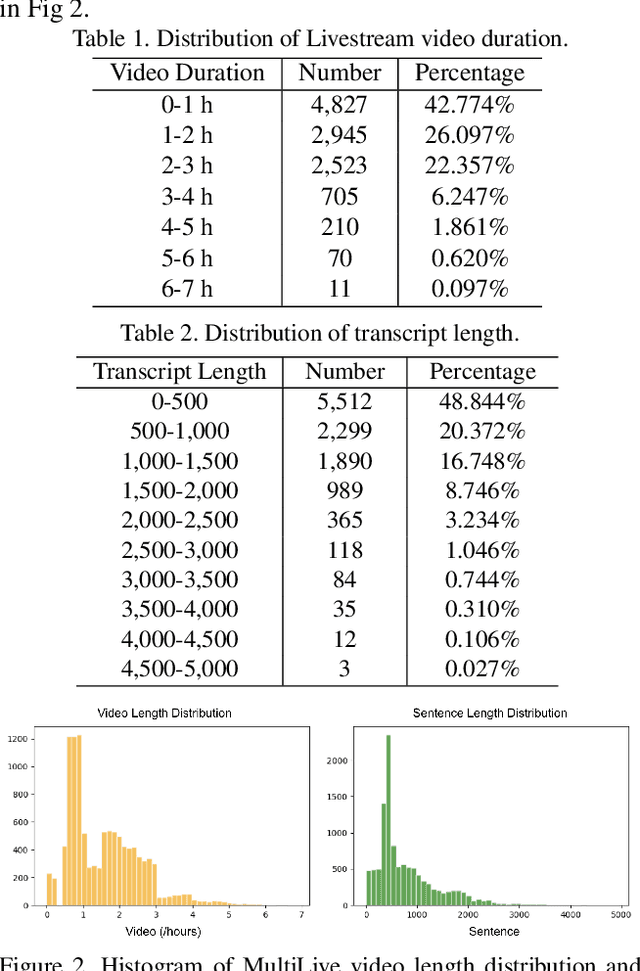
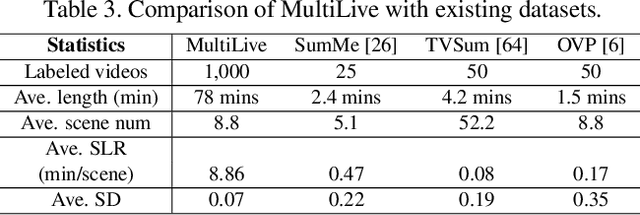
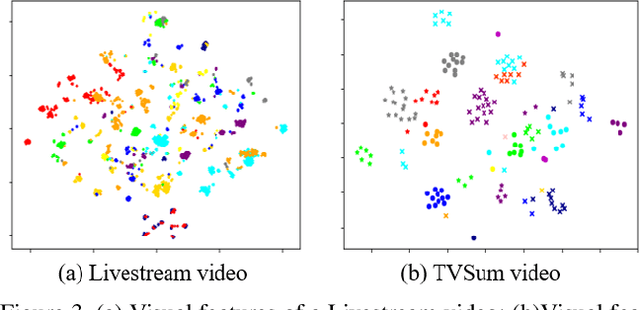
Livestream videos have become a significant part of online learning, where design, digital marketing, creative painting, and other skills are taught by experienced experts in the sessions, making them valuable materials. However, Livestream tutorial videos are usually hours long, recorded, and uploaded to the Internet directly after the live sessions, making it hard for other people to catch up quickly. An outline will be a beneficial solution, which requires the video to be temporally segmented according to topics. In this work, we introduced a large Livestream video dataset named MultiLive, and formulated the temporal segmentation of the long Livestream videos (TSLLV) task. We propose LiveSeg, an unsupervised Livestream video temporal Segmentation solution, which takes advantage of multimodal features from different domains. Our method achieved a $16.8\%$ F1-score performance improvement compared with the state-of-the-art method.
Semantics-Consistent Cross-domain Summarization via Optimal Transport Alignment
Oct 10, 2022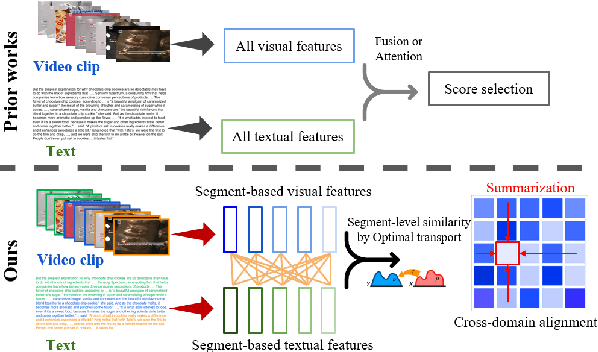
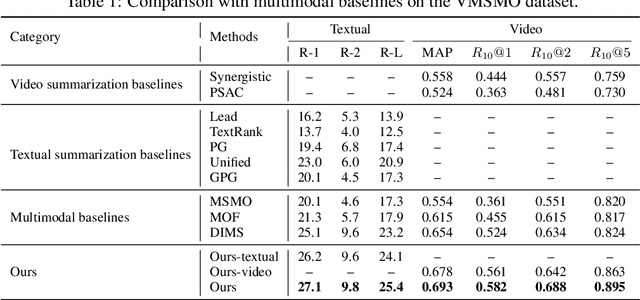
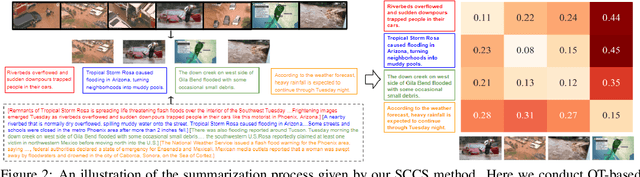
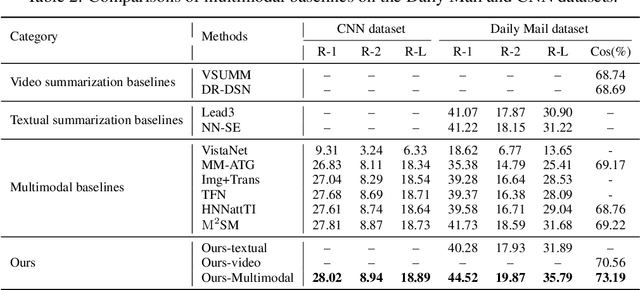
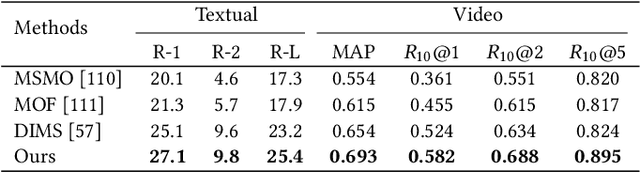
Multimedia summarization with multimodal output (MSMO) is a recently explored application in language grounding. It plays an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. However, existing methods extract features from the whole video and article and use fusion methods to select the representative one, thus usually ignoring the critical structure and varying semantics. In this work, we propose a Semantics-Consistent Cross-domain Summarization (SCCS) model based on optimal transport alignment with visual and textual segmentation. In specific, our method first decomposes both video and article into segments in order to capture the structural semantics, respectively. Then SCCS follows a cross-domain alignment objective with optimal transport distance, which leverages multimodal interaction to match and select the visual and textual summary. We evaluated our method on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.
Toward Understanding WordArt: Corner-Guided Transformer for Scene Text Recognition
Jul 31, 2022
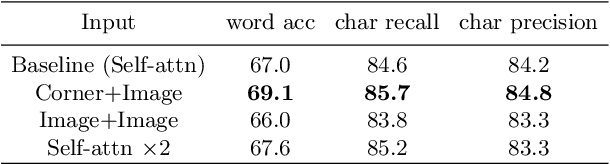
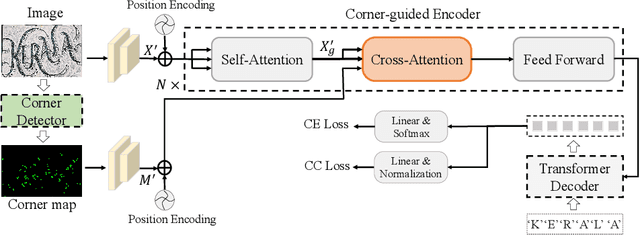
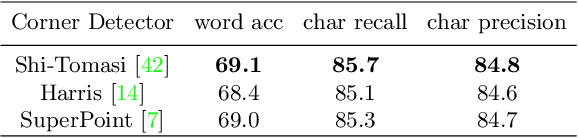
Artistic text recognition is an extremely challenging task with a wide range of applications. However, current scene text recognition methods mainly focus on irregular text while have not explored artistic text specifically. The challenges of artistic text recognition include the various appearance with special-designed fonts and effects, the complex connections and overlaps between characters, and the severe interference from background patterns. To alleviate these problems, we propose to recognize the artistic text at three levels. Firstly, corner points are applied to guide the extraction of local features inside characters, considering the robustness of corner structures to appearance and shape. In this way, the discreteness of the corner points cuts off the connection between characters, and the sparsity of them improves the robustness for background interference. Secondly, we design a character contrastive loss to model the character-level feature, improving the feature representation for character classification. Thirdly, we utilize Transformer to learn the global feature on image-level and model the global relationship of the corner points, with the assistance of a corner-query cross-attention mechanism. Besides, we provide an artistic text dataset to benchmark the performance. Experimental results verify the significant superiority of our proposed method on artistic text recognition and also achieve state-of-the-art performance on several blurred and perspective datasets.
MHMS: Multimodal Hierarchical Multimedia Summarization
Apr 07, 2022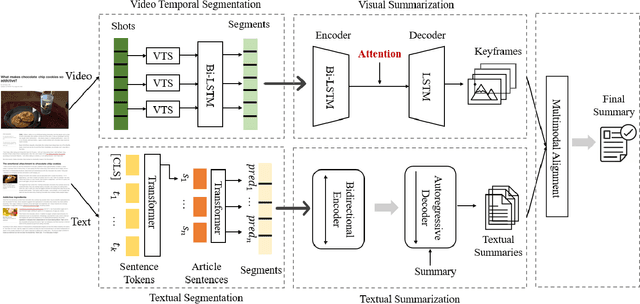
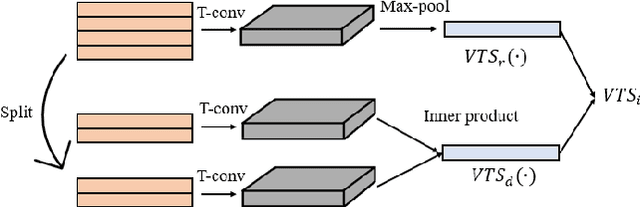

Multimedia summarization with multimodal output can play an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. In this work, we propose a multimodal hierarchical multimedia summarization (MHMS) framework by interacting visual and language domains to generate both video and textual summaries. Our MHMS method contains video and textual segmentation and summarization module, respectively. It formulates a cross-domain alignment objective with optimal transport distance which leverages cross-domain interaction to generate the representative keyframe and textual summary. We evaluated MHMS on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.
Melody Harmonization with Controllable Harmonic Rhythm
Dec 21, 2021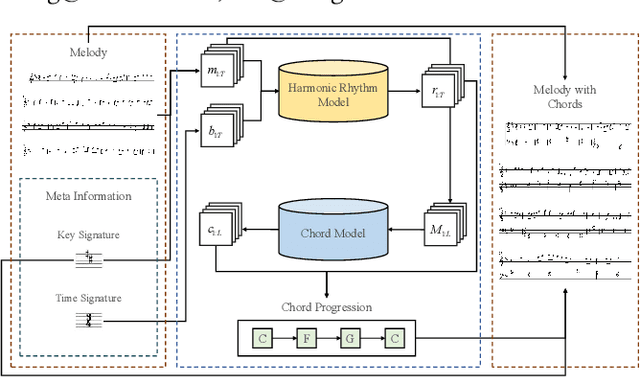

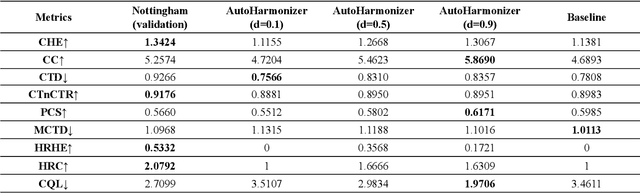
Melody harmonization, namely generating a chord progression for a user-given melody, remains a challenging task to this day. Although previous neural network-based systems can effectively generate an appropriate chord progression for a melody, few studies focus on controllable melody harmonization, and none of them can generate flexible harmonic rhythms. To achieve harmonic rhythm-controllable melody harmonization, we propose AutoHarmonizer, a neural network-based melody harmonization system that can generate denser or sparser chord progressions with the use of a new sampling method for controllable generation proposed in this paper. This system mainly consists of two parts: a harmonic rhythm model provides coarse-grained chord onset information, while a chord model generates specific pitches for chords based on the given melody and the corresponding harmonic rhythm sequence previously generated. To evaluate the performance of AutoHarmonizer, we use nine metrics to compare the chord progressions from humans, the system proposed in this paper and the baseline. Experimental results show that AutoHarmonizer not only generates harmonic rhythms comparable to the human level, but generates chords with overall better quality than baseline at different settings. In addition, we use AutoHarmonizer to harmonize the Session Dataset (which were originally chordless), and ended with 40,925 traditional Irish folk songs with harmonies, named the Session Lead Sheet Dataset, which is the largest lead sheet dataset to date.
STALP: Style Transfer with Auxiliary Limited Pairing
Oct 20, 2021We present an approach to example-based stylization of images that uses a single pair of a source image and its stylized counterpart. We demonstrate how to train an image translation network that can perform real-time semantically meaningful style transfer to a set of target images with similar content as the source image. A key added value of our approach is that it considers also consistency of target images during training. Although those have no stylized counterparts, we constrain the translation to keep the statistics of neural responses compatible with those extracted from the stylized source. In contrast to concurrent techniques that use a similar input, our approach better preserves important visual characteristics of the source style and can deliver temporally stable results without the need to explicitly handle temporal consistency. We demonstrate its practical utility on various applications including video stylization, style transfer to panoramas, faces, and 3D models.
Font Completion and Manipulation by Cycling Between Multi-Modality Representations
Aug 30, 2021

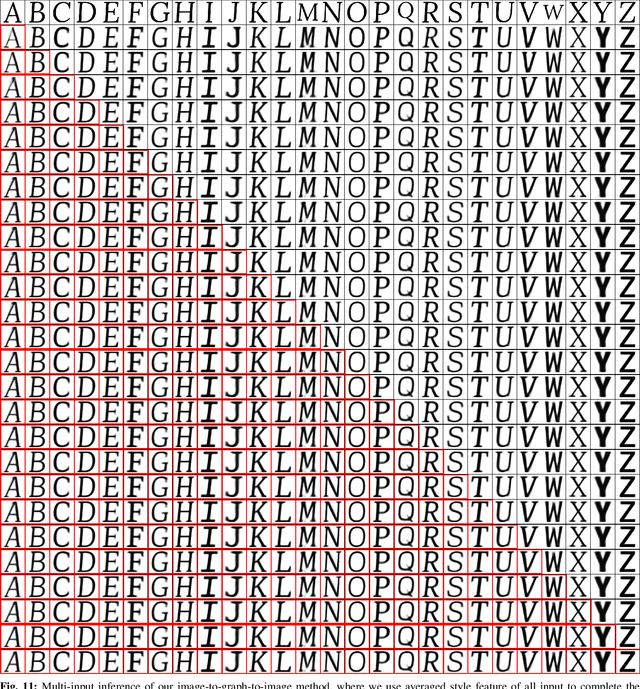

Generating font glyphs of consistent style from one or a few reference glyphs, i.e., font completion, is an important task in topographical design. As the problem is more well-defined than general image style transfer tasks, thus it has received interest from both vision and machine learning communities. Existing approaches address this problem as a direct image-to-image translation task. In this work, we innovate to explore the generation of font glyphs as 2D graphic objects with the graph as an intermediate representation, so that more intrinsic graphic properties of font styles can be captured. Specifically, we formulate a cross-modality cycled image-to-image model structure with a graph constructor between an image encoder and an image renderer. The novel graph constructor maps a glyph's latent code to its graph representation that matches expert knowledge, which is trained to help the translation task. Our model generates improved results than both image-to-image baseline and previous state-of-the-art methods for glyph completion. Furthermore, the graph representation output by our model also provides an intuitive interface for users to do local editing and manipulation. Our proposed cross-modality cycled representation learning has the potential to be applied to other domains with prior knowledge from different data modalities. Our code is available at https://github.com/VITA-Group/Font_Completion_Graph.