 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Robust is Your Fairness? Evaluating and Sustaining Fairness under Unseen Distribution Shifts
Jul 04, 2022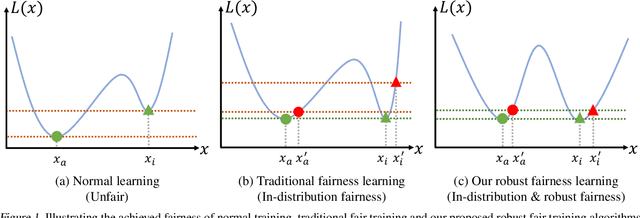
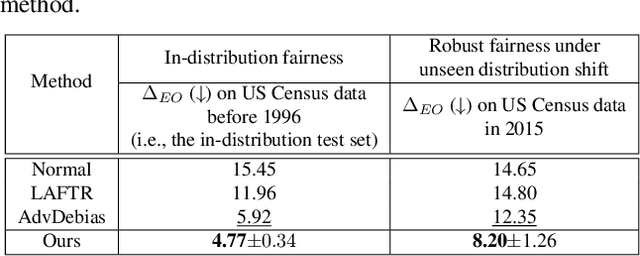
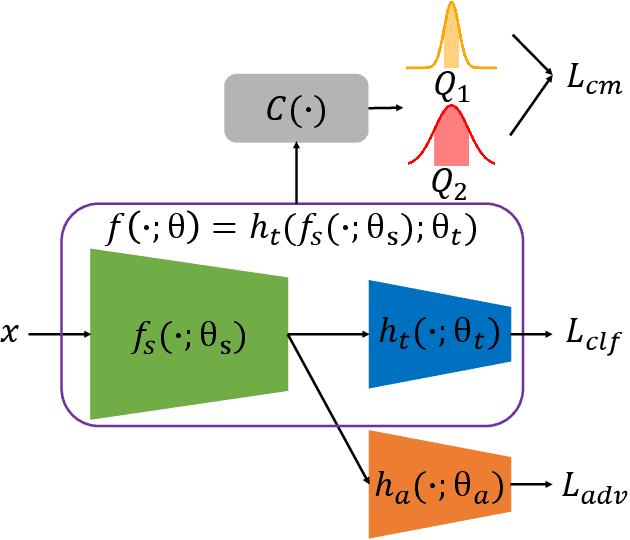
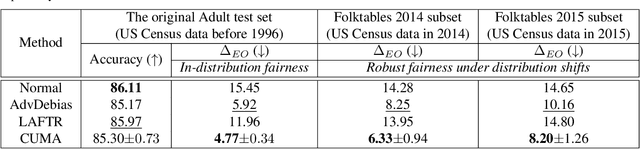
Increasing concerns have been raised on deep learning fairness in recent years. Existing fairness-aware machine learning methods mainly focus on the fairness of in-distribution data. However, in real-world applications, it is common to have distribution shift between the training and test data. In this paper, we first show that the fairness achieved by existing methods can be easily broken by slight distribution shifts. To solve this problem, we propose a novel fairness learning method termed CUrvature MAtching (CUMA), which can achieve robust fairness generalizable to unseen domains with unknown distributional shifts. Specifically, CUMA enforces the model to have similar generalization ability on the majority and minority groups, by matching the loss curvature distributions of the two groups. We evaluate our method on three popular fairness datasets. Compared with existing methods, CUMA achieves superior fairness under unseen distribution shifts, without sacrificing either the overall accuracy or the in-distribution fairness.
Aug-NeRF: Training Stronger Neural Radiance Fields with Triple-Level Physically-Grounded Augmentations
Jul 04, 2022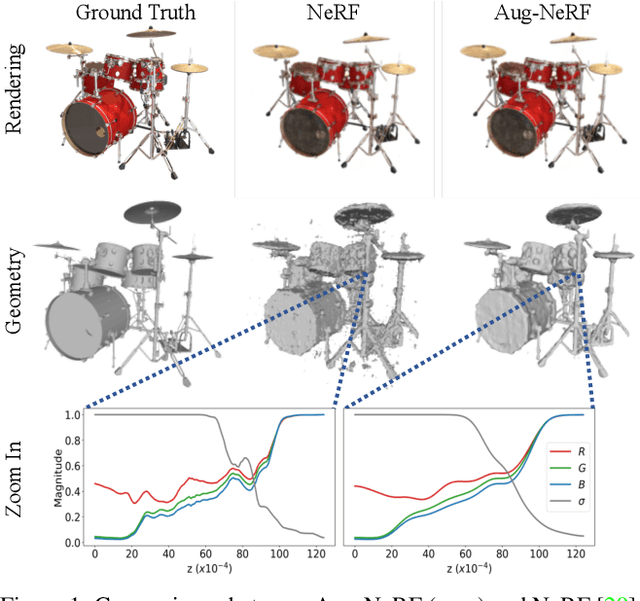
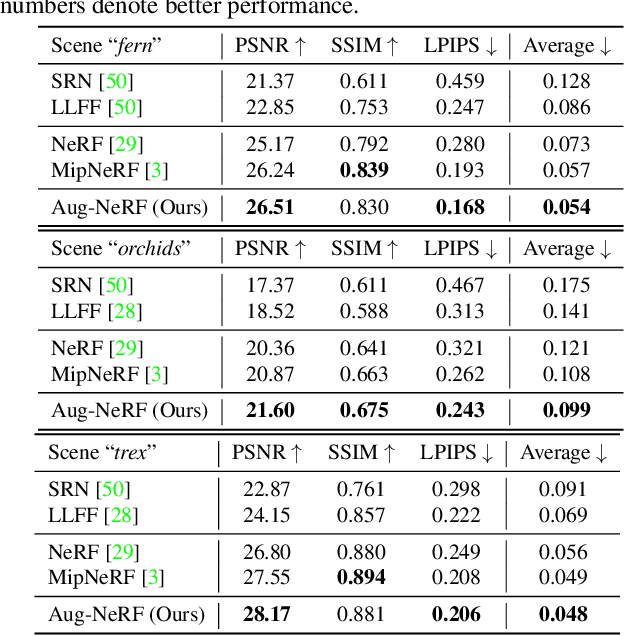
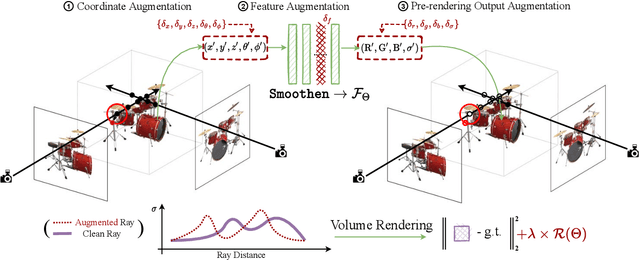
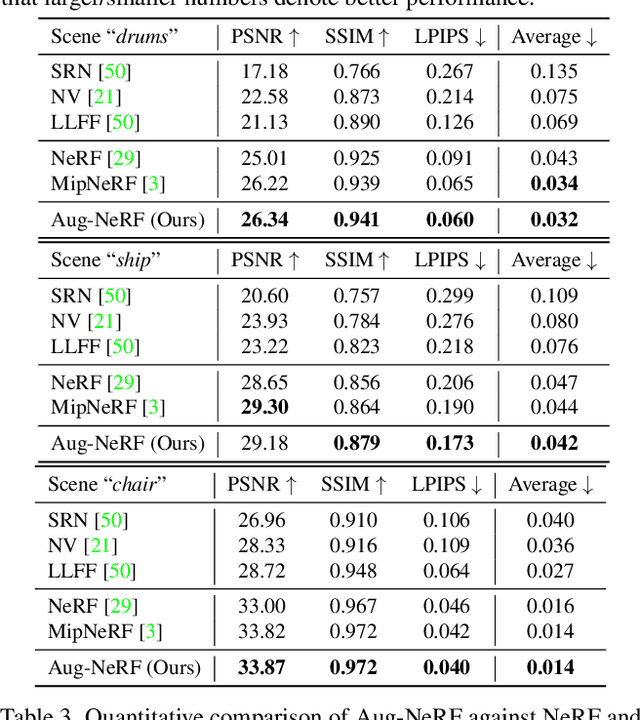
Neural Radiance Field (NeRF) regresses a neural parameterized scene by differentially rendering multi-view images with ground-truth supervision. However, when interpolating novel views, NeRF often yields inconsistent and visually non-smooth geometric results, which we consider as a generalization gap between seen and unseen views. Recent advances in convolutional neural networks have demonstrated the promise of advanced robust data augmentations, either random or learned, in enhancing both in-distribution and out-of-distribution generalization. Inspired by that, we propose Augmented NeRF (Aug-NeRF), which for the first time brings the power of robust data augmentations into regularizing the NeRF training. Particularly, our proposal learns to seamlessly blend worst-case perturbations into three distinct levels of the NeRF pipeline with physical grounds, including (1) the input coordinates, to simulate imprecise camera parameters at image capture; (2) intermediate features, to smoothen the intrinsic feature manifold; and (3) pre-rendering output, to account for the potential degradation factors in the multi-view image supervision. Extensive results demonstrate that Aug-NeRF effectively boosts NeRF performance in both novel view synthesis (up to 1.5dB PSNR gain) and underlying geometry reconstruction. Furthermore, thanks to the implicit smooth prior injected by the triple-level augmentations, Aug-NeRF can even recover scenes from heavily corrupted images, a highly challenging setting untackled before. Our codes are available in https://github.com/VITA-Group/Aug-NeRF.
Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-Tailed Recognition
Jul 04, 2022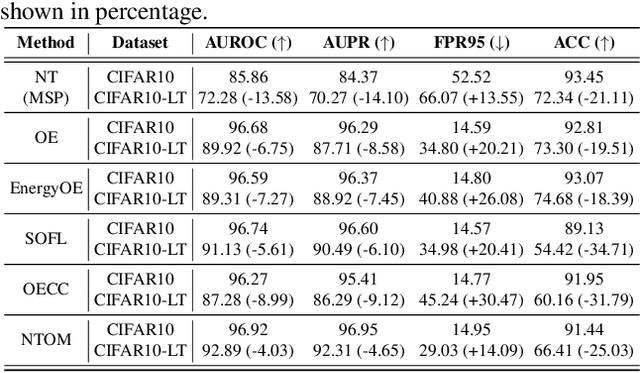
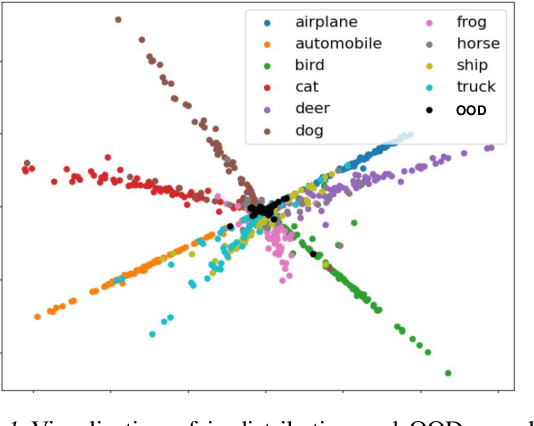
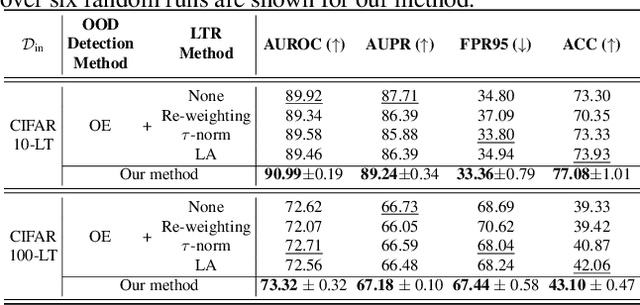
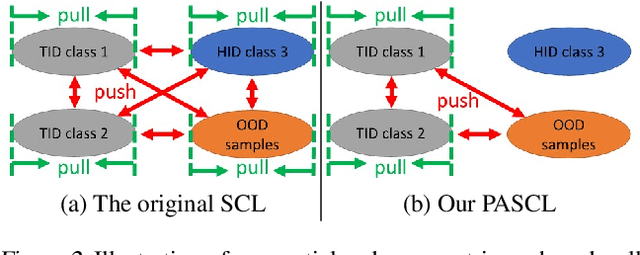
Existing out-of-distribution (OOD) detection methods are typically benchmarked on training sets with balanced class distributions. However, in real-world applications, it is common for the training sets to have long-tailed distributions. In this work, we first demonstrate that existing OOD detection methods commonly suffer from significant performance degradation when the training set is long-tail distributed. Through analysis, we posit that this is because the models struggle to distinguish the minority tail-class in-distribution samples, from the true OOD samples, making the tail classes more prone to be falsely detected as OOD. To solve this problem, we propose Partial and Asymmetric Supervised Contrastive Learning (PASCL), which explicitly encourages the model to distinguish between tail-class in-distribution samples and OOD samples. To further boost in-distribution classification accuracy, we propose Auxiliary Branch Finetuning, which uses two separate branches of BN and classification layers for anomaly detection and in-distribution classification, respectively. The intuition is that in-distribution and OOD anomaly data have different underlying distributions. Our method outperforms previous state-of-the-art method by $1.29\%$, $1.45\%$, $0.69\%$ anomaly detection false positive rate (FPR) and $3.24\%$, $4.06\%$, $7.89\%$ in-distribution classification accuracy on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, respectively. Code and pre-trained models are available at https://github.com/amazon-research/long-tailed-ood-detection.
Removing Batch Normalization Boosts Adversarial Training
Jul 04, 2022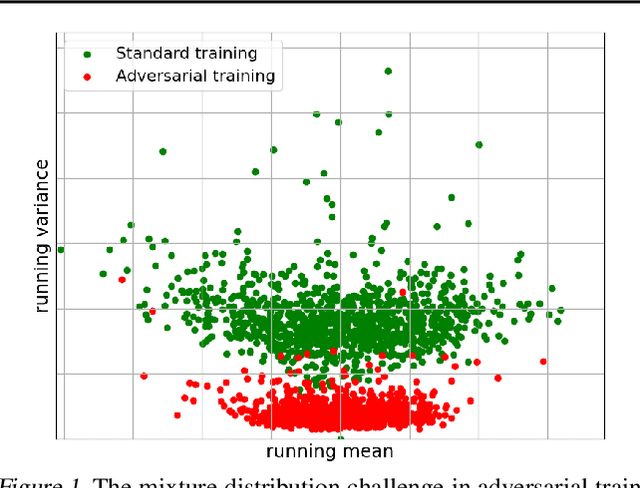
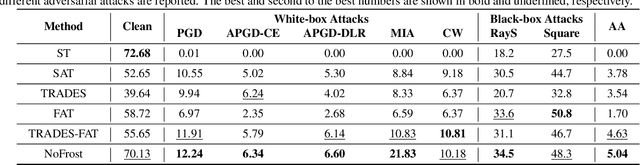
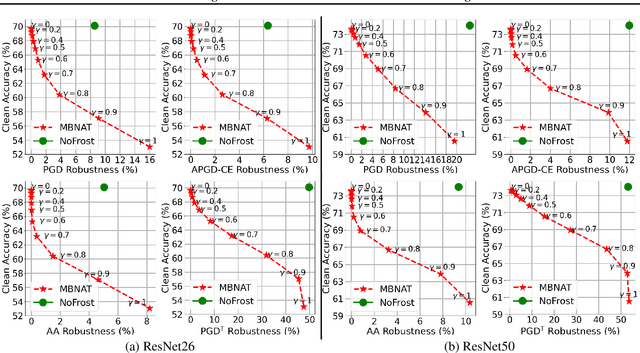
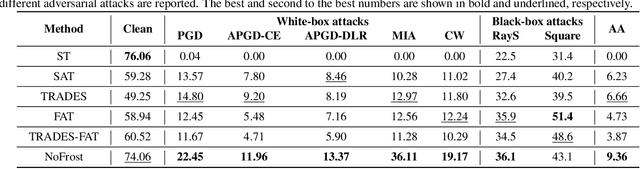
Adversarial training (AT) defends deep neural networks against adversarial attacks. One challenge that limits its practical application is the performance degradation on clean samples. A major bottleneck identified by previous works is the widely used batch normalization (BN), which struggles to model the different statistics of clean and adversarial training samples in AT. Although the dominant approach is to extend BN to capture this mixture of distribution, we propose to completely eliminate this bottleneck by removing all BN layers in AT. Our normalizer-free robust training (NoFrost) method extends recent advances in normalizer-free networks to AT for its unexplored advantage on handling the mixture distribution challenge. We show that NoFrost achieves adversarial robustness with only a minor sacrifice on clean sample accuracy. On ImageNet with ResNet50, NoFrost achieves $74.06\%$ clean accuracy, which drops merely $2.00\%$ from standard training. In contrast, BN-based AT obtains $59.28\%$ clean accuracy, suffering a significant $16.78\%$ drop from standard training. In addition, NoFrost achieves a $23.56\%$ adversarial robustness against PGD attack, which improves the $13.57\%$ robustness in BN-based AT. We observe better model smoothness and larger decision margins from NoFrost, which make the models less sensitive to input perturbations and thus more robust. Moreover, when incorporating more data augmentations into NoFrost, it achieves comprehensive robustness against multiple distribution shifts. Code and pre-trained models are public at https://github.com/amazon-research/normalizer-free-robust-training.
Training Your Sparse Neural Network Better with Any Mask
Jun 28, 2022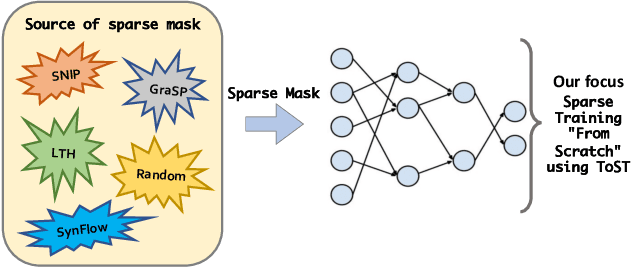
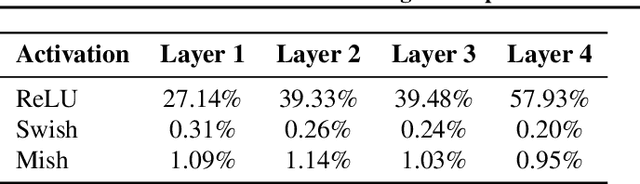
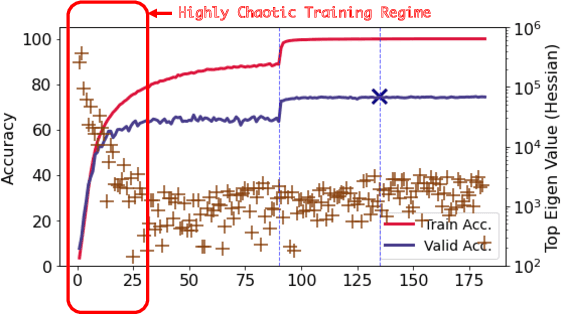
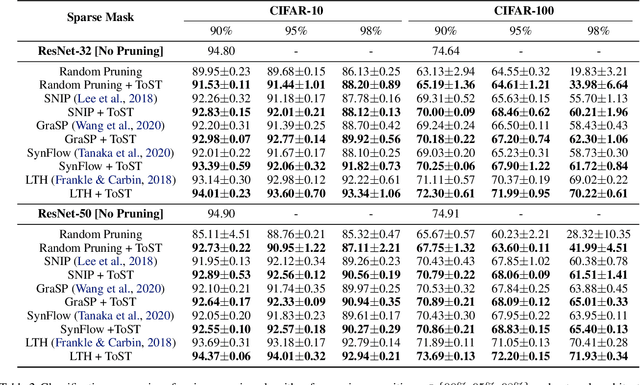
Pruning large neural networks to create high-quality, independently trainable sparse masks, which can maintain similar performance to their dense counterparts, is very desirable due to the reduced space and time complexity. As research effort is focused on increasingly sophisticated pruning methods that leads to sparse subnetworks trainable from the scratch, we argue for an orthogonal, under-explored theme: improving training techniques for pruned sub-networks, i.e. sparse training. Apart from the popular belief that only the quality of sparse masks matters for sparse training, in this paper we demonstrate an alternative opportunity: one can carefully customize the sparse training techniques to deviate from the default dense network training protocols, consisting of introducing ``ghost" neurons and skip connections at the early stage of training, and strategically modifying the initialization as well as labels. Our new sparse training recipe is generally applicable to improving training from scratch with various sparse masks. By adopting our newly curated techniques, we demonstrate significant performance gains across various popular datasets (CIFAR-10, CIFAR-100, TinyImageNet), architectures (ResNet-18/32/104, Vgg16, MobileNet), and sparse mask options (lottery ticket, SNIP/GRASP, SynFlow, or even randomly pruning), compared to the default training protocols, especially at high sparsity levels. Code is at https://github.com/VITA-Group/ToST
Queried Unlabeled Data Improves and Robustifies Class-Incremental Learning
Jun 17, 2022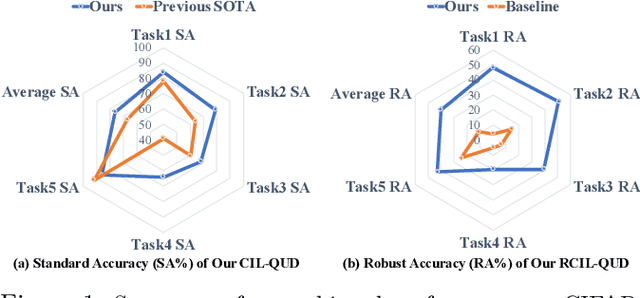
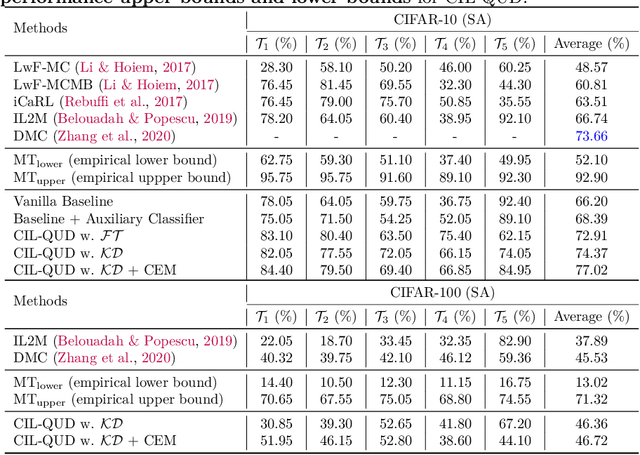
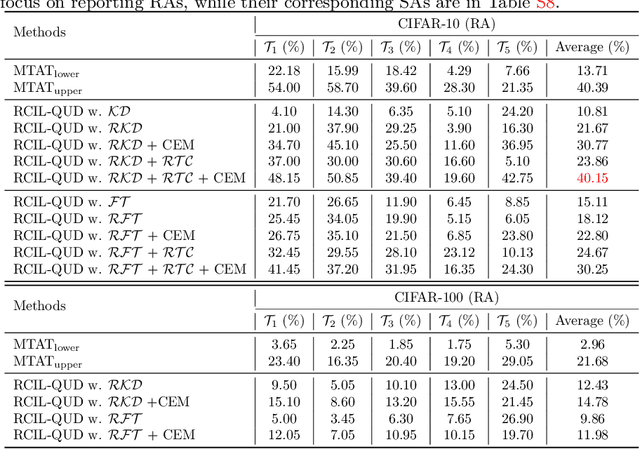
Class-incremental learning (CIL) suffers from the notorious dilemma between learning newly added classes and preserving previously learned class knowledge. That catastrophic forgetting issue could be mitigated by storing historical data for replay, which yet would cause memory overheads as well as imbalanced prediction updates. To address this dilemma, we propose to leverage "free" external unlabeled data querying in continual learning. We first present a CIL with Queried Unlabeled Data (CIL-QUD) scheme, where we only store a handful of past training samples as anchors and use them to query relevant unlabeled examples each time. Along with new and past stored data, the queried unlabeled are effectively utilized, through learning-without-forgetting (LwF) regularizers and class-balance training. Besides preserving model generalization over past and current tasks, we next study the problem of adversarial robustness for CIL-QUD. Inspired by the recent success of learning robust models with unlabeled data, we explore a new robustness-aware CIL setting, where the learned adversarial robustness has to resist forgetting and be transferred as new tasks come in continually. While existing options easily fail, we show queried unlabeled data can continue to benefit, and seamlessly extend CIL-QUD into its robustified versions, RCIL-QUD. Extensive experiments demonstrate that CIL-QUD achieves substantial accuracy gains on CIFAR-10 and CIFAR-100, compared to previous state-of-the-art CIL approaches. Moreover, RCIL-QUD establishes the first strong milestone for robustness-aware CIL. Codes are available in https://github.com/VITA-Group/CIL-QUD.
Can pruning improve certified robustness of neural networks?
Jun 17, 2022
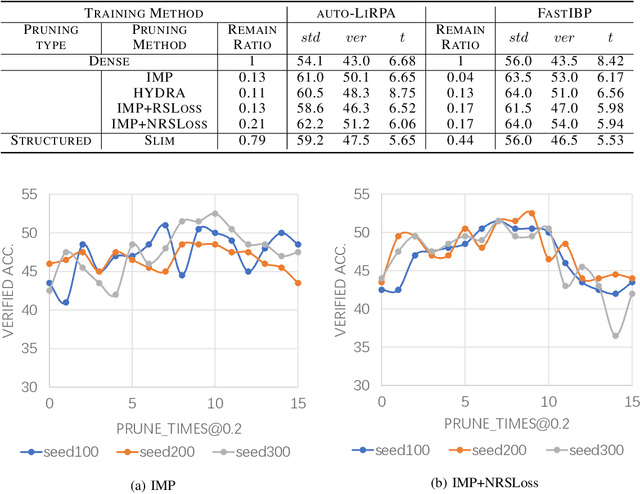
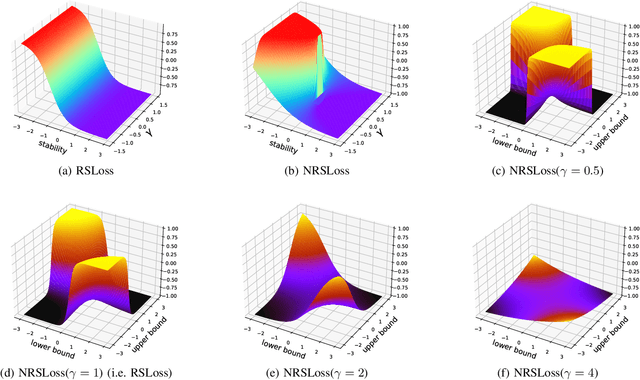
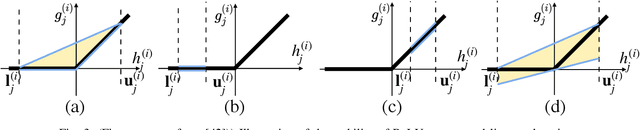
With the rapid development of deep learning, the sizes of neural networks become larger and larger so that the training and inference often overwhelm the hardware resources. Given the fact that neural networks are often over-parameterized, one effective way to reduce such computational overhead is neural network pruning, by removing redundant parameters from trained neural networks. It has been recently observed that pruning can not only reduce computational overhead but also can improve empirical robustness of deep neural networks (NNs), potentially owing to removing spurious correlations while preserving the predictive accuracies. This paper for the first time demonstrates that pruning can generally improve certified robustness for ReLU-based NNs under the complete verification setting. Using the popular Branch-and-Bound (BaB) framework, we find that pruning can enhance the estimated bound tightness of certified robustness verification, by alleviating linear relaxation and sub-domain split problems. We empirically verify our findings with off-the-shelf pruning methods and further present a new stability-based pruning method tailored for reducing neuron instability, that outperforms existing pruning methods in enhancing certified robustness. Our experiments show that by appropriately pruning an NN, its certified accuracy can be boosted up to 8.2% under standard training, and up to 24.5% under adversarial training on the CIFAR10 dataset. We additionally observe the existence of certified lottery tickets that can match both standard and certified robust accuracies of the original dense models across different datasets. Our findings offer a new angle to study the intriguing interaction between sparsity and robustness, i.e. interpreting the interaction of sparsity and certified robustness via neuron stability. Codes are available at: https://github.com/VITA-Group/CertifiedPruning.
Linearity Grafting: Relaxed Neuron Pruning Helps Certifiable Robustness
Jun 15, 2022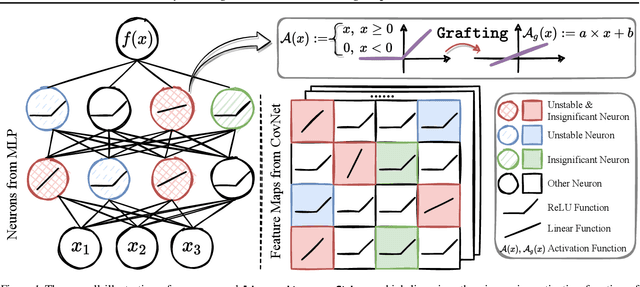
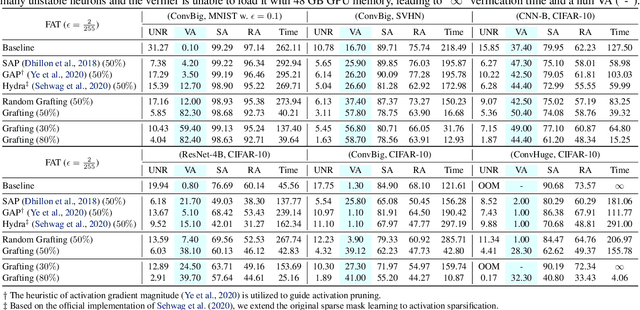
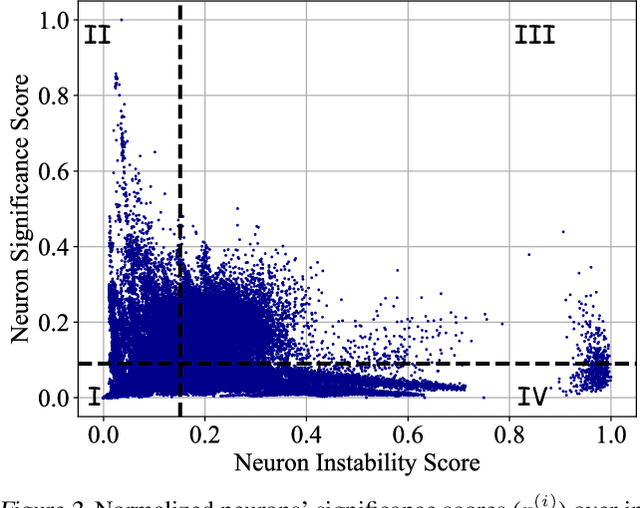
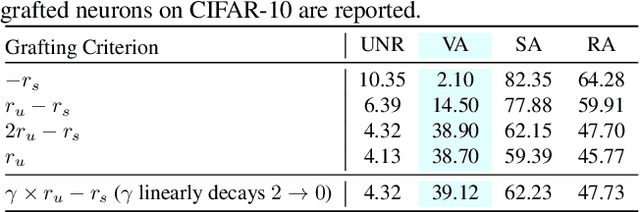
Certifiable robustness is a highly desirable property for adopting deep neural networks (DNNs) in safety-critical scenarios, but often demands tedious computations to establish. The main hurdle lies in the massive amount of non-linearity in large DNNs. To trade off the DNN expressiveness (which calls for more non-linearity) and robustness certification scalability (which prefers more linearity), we propose a novel solution to strategically manipulate neurons, by "grafting" appropriate levels of linearity. The core of our proposal is to first linearize insignificant ReLU neurons, to eliminate the non-linear components that are both redundant for DNN performance and harmful to its certification. We then optimize the associated slopes and intercepts of the replaced linear activations for restoring model performance while maintaining certifiability. Hence, typical neuron pruning could be viewed as a special case of grafting a linear function of the fixed zero slopes and intercept, that might overly restrict the network flexibility and sacrifice its performance. Extensive experiments on multiple datasets and network backbones show that our linearity grafting can (1) effectively tighten certified bounds; (2) achieve competitive certifiable robustness without certified robust training (i.e., over 30% improvements on CIFAR-10 models); and (3) scale up complete verification to large adversarially trained models with 17M parameters. Codes are available at https://github.com/VITA-Group/Linearity-Grafting.
A Multi-purpose Real Haze Benchmark with Quantifiable Haze Levels and Ground Truth
Jun 13, 2022


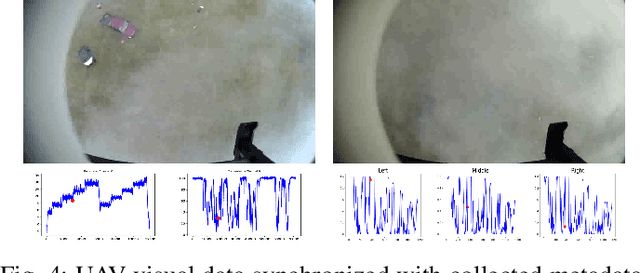
Imagery collected from outdoor visual environments is often degraded due to the presence of dense smoke or haze. A key challenge for research in scene understanding in these degraded visual environments (DVE) is the lack of representative benchmark datasets. These datasets are required to evaluate state-of-the-art object recognition and other computer vision algorithms in degraded settings. In this paper, we address some of these limitations by introducing the first paired real image benchmark dataset with hazy and haze-free images, and in-situ haze density measurements. This dataset was produced in a controlled environment with professional smoke generating machines that covered the entire scene, and consists of images captured from the perspective of both an unmanned aerial vehicle (UAV) and an unmanned ground vehicle (UGV). We also evaluate a set of representative state-of-the-art dehazing approaches as well as object detectors on the dataset. The full dataset presented in this paper, including the ground truth object classification bounding boxes and haze density measurements, is provided for the community to evaluate their algorithms at: https://a2i2-archangel.vision. A subset of this dataset has been used for the Object Detection in Haze Track of CVPR UG2 2022 challenge.
Data-Efficient Double-Win Lottery Tickets from Robust Pre-training
Jun 09, 2022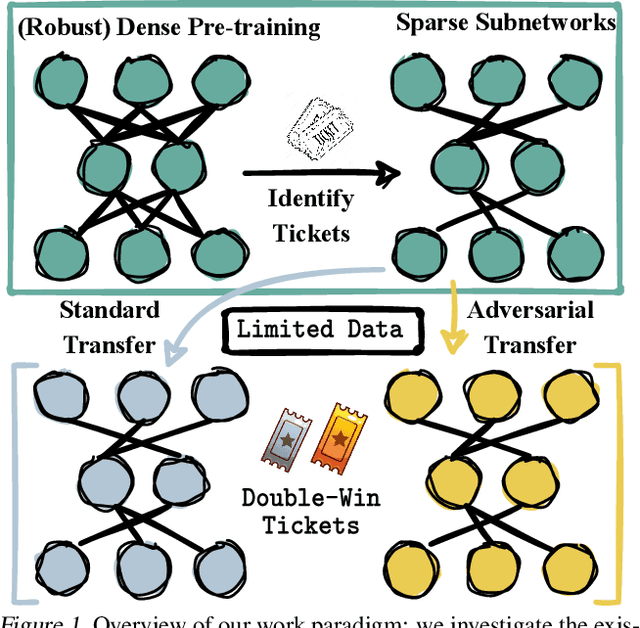
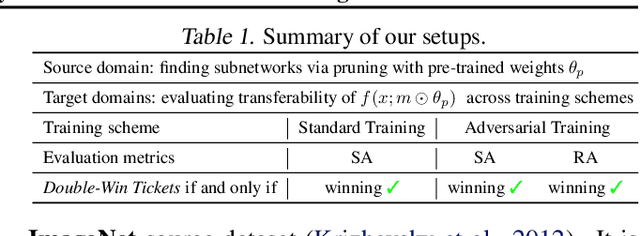

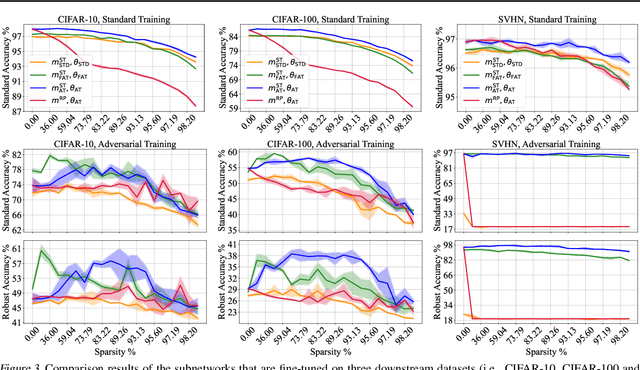
Pre-training serves as a broadly adopted starting point for transfer learning on various downstream tasks. Recent investigations of lottery tickets hypothesis (LTH) demonstrate such enormous pre-trained models can be replaced by extremely sparse subnetworks (a.k.a. matching subnetworks) without sacrificing transferability. However, practical security-crucial applications usually pose more challenging requirements beyond standard transfer, which also demand these subnetworks to overcome adversarial vulnerability. In this paper, we formulate a more rigorous concept, Double-Win Lottery Tickets, in which a located subnetwork from a pre-trained model can be independently transferred on diverse downstream tasks, to reach BOTH the same standard and robust generalization, under BOTH standard and adversarial training regimes, as the full pre-trained model can do. We comprehensively examine various pre-training mechanisms and find that robust pre-training tends to craft sparser double-win lottery tickets with superior performance over the standard counterparts. For example, on downstream CIFAR-10/100 datasets, we identify double-win matching subnetworks with the standard, fast adversarial, and adversarial pre-training from ImageNet, at 89.26%/73.79%, 89.26%/79.03%, and 91.41%/83.22% sparsity, respectively. Furthermore, we observe the obtained double-win lottery tickets can be more data-efficient to transfer, under practical data-limited (e.g., 1% and 10%) downstream schemes. Our results show that the benefits from robust pre-training are amplified by the lottery ticket scheme, as well as the data-limited transfer setting. Codes are available at https://github.com/VITA-Group/Double-Win-LTH.