 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRED: Adaptive Real-Time DAG Scheduling for Robotic Inference under Environmental Dynamics
May 21, 2026Robots deployed in dynamic environments must contend with environment-driven changes that reshape computation at runtime: new tasks may appear, precedence relations can shift, and overall workload structure evolves, all of which degrade performance, especially when multi-task inference is required under tight resource and real-time budgets. We present RED, a real-time scheduling framework for multi-task deep neural network workloads on resource-constrained robotic platforms that adapts to Robotic Environmental Dynamics (RED) while preserving end-to-end timing guarantees under modeling assumptions. The core of RED is a deadline-aware scheduler that assigns intermediate sub-deadlines, allowing it to accommodate evolving computation graphs and asynchronous inference induced by unpredictable conditions. The framework also supports flexible deployment of MIMONet (multi-input multi-output neural networks), commonly used in multi-tasking robots to alleviate memory pressure through weight sharing. RED explicitly leverages this shared-parameter property via a workload refinement and graph-reconstruction procedure that aligns MIMONet structure with schedulability requirements, improving compatibility and efficiency. We implement RED on NVIDIA Jetson family platforms and on an Apple M-series MacBook and evaluate it on navigation-oriented workloads representative of real robotic scenarios. Experiments show consistent gains over existing methods in throughput, deadline satisfaction, robustness to interference, adaptability, and runtime overhead.
PIMbot: A Self-Adaptive Attack Framework for Adversarial Manipulation of Multi-Robot Reinforcement Learning
May 21, 2026Recent research has demonstrated the potential of reinforcement learning in effective multi-robot collaboration, particularly in social dilemmas where robots face a trade-off between self-interest and collective benefits. However, environmental factors such as miscommunication and adversarial robots can impact cooperation, making it crucial to explore how multi-robot communication can be manipulated to achieve different outcomes. This paper presents PIMbot, a framework that manipulates outcomes via two complementary levers: (i) incentive manipulation of the reward channel and (ii) policy manipulation of an agent's own actions. An adaptive multi-objective controller balances these levers in an online manner. Our work introduces a novel approach to manipulation in recent multi-agent RL social dilemmas that utilize a unique reward function for incentivization. By utilizing our proposed PIMbot mechanisms, a robot is able to manipulate the social dilemma environment effectively. Comprehensive experimental results demonstrate the effectiveness of our proposed methods in the Gazebo-simulated multi-robot environment. Moreover, a real embedded device case study on NVIDIA Jetson Orin Nano quantifies system cost and validates PIMbot's effectiveness on realistic autonomous embedded systems scenarios beyond simulation. Together, these results position PIMbot as a rigorous stress-test tool exposing critical vulnerabilities in multi-robot cooperative tasks.
MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
Jan 18, 2026Deep Research Agents (DRAs) generate citation-rich reports via multi-step search and synthesis, yet existing benchmarks mainly target text-only settings or short-form multimodal QA, missing end-to-end multimodal evidence use. We introduce MMDeepResearch-Bench (MMDR-Bench), a benchmark of 140 expert-crafted tasks across 21 domains, where each task provides an image-text bundle to evaluate multimodal understanding and citation-grounded report generation. Compared to prior setups, MMDR-Bench emphasizes report-style synthesis with explicit evidence use, where models must connect visual artifacts to sourced claims and maintain consistency across narrative, citations, and visual references. We further propose a unified, interpretable evaluation pipeline: Formula-LLM Adaptive Evaluation (FLAE) for report quality, Trustworthy Retrieval-Aligned Citation Evaluation (TRACE) for citation-grounded evidence alignment, and Multimodal Support-Aligned Integrity Check (MOSAIC) for text-visual integrity, each producing fine-grained signals that support error diagnosis beyond a single overall score. Experiments across 25 state-of-the-art models reveal systematic trade-offs between generation quality, citation discipline, and multimodal grounding, highlighting that strong prose alone does not guarantee faithful evidence use and that multimodal integrity remains a key bottleneck for deep research agents.
MORE: Multi-Objective Adversarial Attacks on Speech Recognition
Jan 05, 2026The emergence of large-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-world applications. Ensuring robustness against even minor input perturbations is therefore critical for maintaining reliable performance in real-time environments. While prior work has mainly examined accuracy degradation under adversarial attacks, robustness with respect to efficiency remains largely unexplored. This narrow focus provides only a partial understanding of ASR model vulnerabilities. To address this gap, we conduct a comprehensive study of ASR robustness under multiple attack scenarios. We introduce MORE, a multi-objective repetitive doubling encouragement attack, which jointly degrades recognition accuracy and inference efficiency through a hierarchical staged repulsion-anchoring mechanism. Specifically, we reformulate multi-objective adversarial optimization into a hierarchical framework that sequentially achieves the dual objectives. To further amplify effectiveness, we propose a novel repetitive encouragement doubling objective (REDO) that induces duplicative text generation by maintaining accuracy degradation and periodically doubling the predicted sequence length. Overall, MORE compels ASR models to produce incorrect transcriptions at a substantially higher computational cost, triggered by a single adversarial input. Experiments show that MORE consistently yields significantly longer transcriptions while maintaining high word error rates compared to existing baselines, underscoring its effectiveness in multi-objective adversarial attack.
HyperEdit: Unlocking Instruction-based Text Editing in LLMs via Hypernetworks
Dec 14, 2025Instruction-based text editing is increasingly critical for real-world applications such as code editors (e.g., Cursor), but Large Language Models (LLMs) continue to struggle with this task. Unlike free-form generation, editing requires faithfully implementing user instructions while preserving unchanged content, as even minor unintended modifications can break functionality. Existing approaches treat editing as generic text generation, leading to two key failures: they struggle to faithfully align edits with diverse user intents, and they often over-edit unchanged regions. We propose HyperEdit to address both issues. First, we introduce hypernetwork-based dynamic adaptation that generates request-specific parameters, enabling the model to tailor its editing strategy to each instruction. Second, we develop difference-aware regularization that focuses supervision on modified spans, preventing over-editing while ensuring precise, minimal changes. HyperEdit achieves a 9%--30% relative improvement in BLEU on modified regions over state-of-the-art baselines, despite utilizing only 3B parameters.
Collaborative Learning in Agentic Systems: A Collective AI is Greater Than the Sum of Its Parts
Jun 05, 2025Agentic AI has gained significant interest as a research paradigm focused on autonomy, self-directed learning, and long-term reliability of decision making. Real-world agentic systems operate in decentralized settings on a large set of tasks or data distributions with constraints such as limited bandwidth, asynchronous execution, and the absence of a centralized model or even common objectives. We posit that exploiting previously learned skills, task similarities, and communication capabilities in a collective of agentic AI are challenging but essential elements to enabling scalability, open-endedness, and beneficial collaborative learning dynamics. In this paper, we introduce Modular Sharing and Composition in Collective Learning (MOSAIC), an agentic algorithm that allows multiple agents to independently solve different tasks while also identifying, sharing, and reusing useful machine-learned knowledge, without coordination, synchronization, or centralized control. MOSAIC combines three mechanisms: (1) modular policy composition via neural network masks, (2) cosine similarity estimation using Wasserstein embeddings for knowledge selection, and (3) asynchronous communication and policy integration. Results on a set of RL benchmarks show that MOSAIC has a greater sample efficiency than isolated learners, i.e., it learns significantly faster, and in some cases, finds solutions to tasks that cannot be solved by isolated learners. The collaborative learning and sharing dynamics are also observed to result in the emergence of ideal curricula of tasks, from easy to hard. These findings support the case for collaborative learning in agentic systems to achieve better and continuously evolving performance both at the individual and collective levels.
Mixtraining: A Better Trade-Off Between Compute and Performance
Feb 26, 2025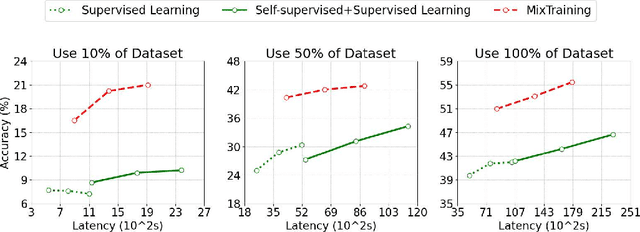
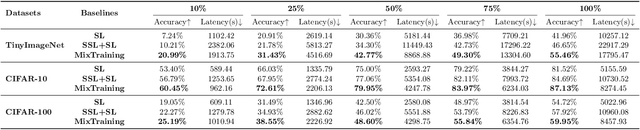


Incorporating self-supervised learning (SSL) before standard supervised learning (SL) has become a widely used strategy to enhance model performance, particularly in data-limited scenarios. However, this approach introduces a trade-off between computation and performance: while SSL helps with representation learning, it requires a separate, often time-consuming training phase, increasing computational overhead and limiting efficiency in resource-constrained settings. To address these challenges, we propose MixTraining, a novel framework that interleaves several SSL and SL epochs within a unified mixtraining training phase, featuring a smooth transition between two learning objectives. MixTraining enhances synergy between SSL and SL for improved accuracy and consolidates shared computation steps to reduce computation overhead. MixTraining is versatile and applicable to both single-task and multi-task learning scenarios. Extensive experiments demonstrate that MixTraining offers a superior compute-performance trade-off compared to conventional pipelines, achieving an 8.81% absolute accuracy gain (18.89% relative accuracy gain) on the TinyImageNet dataset while accelerating training by up to 1.29x with the ViT-Tiny model.
Recent Advances in Large Langauge Model Benchmarks against Data Contamination: From Static to Dynamic Evaluation
Feb 23, 2025Data contamination has received increasing attention in the era of large language models (LLMs) due to their reliance on vast Internet-derived training corpora. To mitigate the risk of potential data contamination, LLM benchmarking has undergone a transformation from static to dynamic benchmarking. In this work, we conduct an in-depth analysis of existing static to dynamic benchmarking methods aimed at reducing data contamination risks. We first examine methods that enhance static benchmarks and identify their inherent limitations. We then highlight a critical gap-the lack of standardized criteria for evaluating dynamic benchmarks. Based on this observation, we propose a series of optimal design principles for dynamic benchmarking and analyze the limitations of existing dynamic benchmarks. This survey provides a concise yet comprehensive overview of recent advancements in data contamination research, offering valuable insights and a clear guide for future research efforts. We maintain a GitHub repository to continuously collect both static and dynamic benchmarking methods for LLMs. The repository can be found at this link.
Bridging the Editing Gap in LLMs: FineEdit for Precise and Targeted Text Modifications
Feb 19, 2025Large Language Models (LLMs) have transformed natural language processing, yet they still struggle with direct text editing tasks that demand precise, context-aware modifications. While models like ChatGPT excel in text generation and analysis, their editing abilities often fall short, addressing only superficial issues rather than deeper structural or logical inconsistencies. In this work, we introduce a dual approach to enhance LLMs editing performance. First, we present InstrEditBench, a high-quality benchmark dataset comprising over 20,000 structured editing tasks spanning Wiki articles, LaTeX documents, code, and database Domain-specific Languages (DSL). InstrEditBench is generated using an innovative automated workflow that accurately identifies and evaluates targeted edits, ensuring that modifications adhere strictly to specified instructions without altering unrelated content. Second, we propose FineEdit, a specialized model trained on this curated benchmark. Experimental results demonstrate that FineEdit achieves significant improvements around {10\%} compared with Gemini on direct editing tasks, convincingly validating its effectiveness.
Transferable Adversarial Attacks against ASR
Nov 14, 2024


Given the extensive research and real-world applications of automatic speech recognition (ASR), ensuring the robustness of ASR models against minor input perturbations becomes a crucial consideration for maintaining their effectiveness in real-time scenarios. Previous explorations into ASR model robustness have predominantly revolved around evaluating accuracy on white-box settings with full access to ASR models. Nevertheless, full ASR model details are often not available in real-world applications. Therefore, evaluating the robustness of black-box ASR models is essential for a comprehensive understanding of ASR model resilience. In this regard, we thoroughly study the vulnerability of practical black-box attacks in cutting-edge ASR models and propose to employ two advanced time-domain-based transferable attacks alongside our differentiable feature extractor. We also propose a speech-aware gradient optimization approach (SAGO) for ASR, which forces mistranscription with minimal impact on human imperceptibility through voice activity detection rule and a speech-aware gradient-oriented optimizer. Our comprehensive experimental results reveal performance enhancements compared to baseline approaches across five models on two databases.