 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Unfolding: Efficient Unfolding Reconstruction for Video Snapshot Compressive Imaging
Jun 23, 2026While Deep Unfolding Networks (DUNs) dominate video Snapshot Compressive Imaging (SCI), they remain constrained by a uniform design philosophy. Existing methods repeatedly stack high-complexity priors with identical structures, ignoring the fact that optimization trajectories converge toward static states. This results in representation stagnation, where high-cost computations are wasted on minimal feature updates. To address this inefficiency, we present Differential Unfolding (DU), a heterogeneous framework that replaces uniform repetition with dynamic evolution. Central to DU is the Differential Evolutionary Framework (DEF), which partitions the unfolding process into two complementary roles: structural anchoring and differential evolution. In this scheme, high-parameter general stages are sparsely deployed to generate high-fidelity feature foundations. Complementing these, lightweight differential stages employ a Differential Representation Prior (DRP) to propagate and refine these foundational features through a differential mechanism. By integrating Differential Representation Attention (DRA) for evolving attention maps and a Differential Modulated FFN (DM-FFN) for feature rectification, DRP effectively models cross-stage variations with minimal overhead. By focusing computational resources on dynamic evolution rather than static redundancy, DU achieves a superior trade-off between accuracy and efficiency. Extensive experiments verify that our method establishes new state-of-the-art results while significantly slashing computational overhead. https://github.com/Muyuan-Zhang/DU
Active Testing of Large Language Models via Approximate Neyman Allocation
May 11, 2026Large language models (LLMs) require reliable evaluation from pre-training to test-time scaling, making evaluation a recurring rather than one-off cost. As model scales grow and target tasks increasingly demand expert annotators, both the compute and labeling costs needed for each evaluation rise rapidly. Active testing aims to alleviate this bottleneck by approximating the evaluation result from a small but informative subset of the evaluation pool. However, existing approaches primarily target classification and break down on generative tasks. We introduce a novel active testing algorithm tailored to generative tasks. Our method leverages semantic entropy from surrogate models to stratify the evaluation pool and then conducts approximate Neyman allocation based on signals extracted from these surrogates. Across multiple language and multimodal benchmarks and a range of surrogate-target model pairs, our method significantly improves on baselines and closely tracks Oracle-Neyman, delivering up to 28\% MSE reduction over Uniform Sampling and an average of 22.9\% budget savings.
Hackers or Hallucinators? A Comprehensive Analysis of LLM-Based Automated Penetration Testing
Apr 07, 2026The rapid advancement of Large Language Models (LLMs) has created new opportunities for Automated Penetration Testing (AutoPT), spawning numerous frameworks aimed at achieving end-to-end autonomous attacks. However, despite the proliferation of related studies, existing research generally lacks systematic architectural analysis and large-scale empirical comparisons under a unified benchmark. Therefore, this paper presents the first Systematization of Knowledge (SoK) focusing on the architectural design and comprehensive empirical evaluation of current LLM-based AutoPT frameworks. At systematization level, we comprehensively review existing framework designs across six dimensions: agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks. At empirical level, we conduct large-scale experiments on 13 representative open-source AutoPT frameworks and 2 baseline frameworks utilizing a unified benchmark. The experiments consumed over 10 billion tokens in total and generated more than 1,500 execution logs, which were manually reviewed and analyzed over four months by a panel of more than 15 researchers with expertise in cybersecurity. By investigating the latest progress in this rapidly developing field, we provide researchers with a structured taxonomy to understand existing LLM-based AutoPT frameworks and a large-scale empirical benchmark, along with promising directions for future research.
Mixtraining: A Better Trade-Off Between Compute and Performance
Feb 26, 2025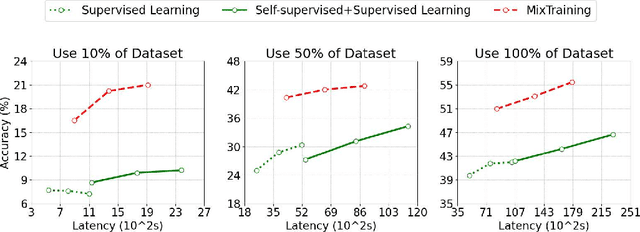
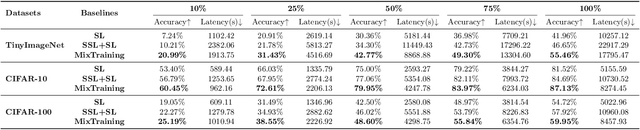


Incorporating self-supervised learning (SSL) before standard supervised learning (SL) has become a widely used strategy to enhance model performance, particularly in data-limited scenarios. However, this approach introduces a trade-off between computation and performance: while SSL helps with representation learning, it requires a separate, often time-consuming training phase, increasing computational overhead and limiting efficiency in resource-constrained settings. To address these challenges, we propose MixTraining, a novel framework that interleaves several SSL and SL epochs within a unified mixtraining training phase, featuring a smooth transition between two learning objectives. MixTraining enhances synergy between SSL and SL for improved accuracy and consolidates shared computation steps to reduce computation overhead. MixTraining is versatile and applicable to both single-task and multi-task learning scenarios. Extensive experiments demonstrate that MixTraining offers a superior compute-performance trade-off compared to conventional pipelines, achieving an 8.81% absolute accuracy gain (18.89% relative accuracy gain) on the TinyImageNet dataset while accelerating training by up to 1.29x with the ViT-Tiny model.
Random Sampling for Diffusion-based Adversarial Purification
Nov 28, 2024



Denoising Diffusion Probabilistic Models (DDPMs) have gained great attention in adversarial purification. Current diffusion-based works focus on designing effective condition-guided mechanisms while ignoring a fundamental problem, i.e., the original DDPM sampling is intended for stable generation, which may not be the optimal solution for adversarial purification. Inspired by the stability of the Denoising Diffusion Implicit Model (DDIM), we propose an opposite sampling scheme called random sampling. In brief, random sampling will sample from a random noisy space during each diffusion process, while DDPM and DDIM sampling will continuously sample from the adjacent or original noisy space. Thus, random sampling obtains more randomness and achieves stronger robustness against adversarial attacks. Correspondingly, we also introduce a novel mediator conditional guidance to guarantee the consistency of the prediction under the purified image and clean image input. To expand awareness of guided diffusion purification, we conduct a detailed evaluation with different sampling methods and our random sampling achieves an impressive improvement in multiple settings. Leveraging mediator-guided random sampling, we also establish a baseline method named DiffAP, which significantly outperforms state-of-the-art (SOTA) approaches in performance and defensive stability. Remarkably, under strong attack, our DiffAP even achieves a more than 20% robustness advantage with 10$\times$ sampling acceleration.