 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study and Theoretical Explanation on Task-Level Model-Merging Collapse
Mar 10, 2026Model merging unifies independently fine-tuned LLMs from the same base, enabling reuse and integration of parallel development efforts without retraining. However, in practice we observe that merging does not always succeed: certain combinations of task-specialist models suffer from catastrophic performance degradation after merging. We refer to this failure mode as merging collapse. Intuitively, collapse arises when the learned representations or parameter adjustments for different tasks are fundamentally incompatible, so that merging forces destructive interference rather than synergy. In this paper, we identify and characterize the phenomenon of task-level merging collapse, where certain task combinations consistently trigger huge performance degradation across all merging methods. Through extensive experiments and statistical analysis, we demonstrate that representational incompatibility between tasks is strongly correlated with merging collapse, while parameter-space conflict metrics show minimal correlation, challenging conventional wisdom in model merging literature. We provide a theoretical explanation on this phenomenon through rate-distortion theory with a dimension-dependent bound, establishing fundamental limits on task mergeability regardless of methodology.
SWE-Spot: Building Small Repo-Experts with Repository-Centric Learning
Jan 29, 2026The deployment of coding agents in privacy-sensitive and resource-constrained environments drives the demand for capable open-weight Small Language Models (SLMs). However, they suffer from a fundamental capability gap: unlike frontier large models, they lack the inference-time strong generalization to work with complicated, unfamiliar codebases. We identify that the prevailing Task-Centric Learning (TCL) paradigm, which scales exposure across disparate repositories, fails to address this limitation. In response, we propose Repository-Centric Learning (RCL), a paradigm shift that prioritizes vertical repository depth over horizontal task breadth, suggesting SLMs must internalize the "physics" of a target software environment through parametric knowledge acquisition, rather than attempting to recover it via costly inference-time search. Following this new paradigm, we design a four-unit Repository-Centric Experience, transforming static codebases into interactive learning signals, to train SWE-Spot-4B, a family of highly compact models built as repo-specialized experts that breaks established scaling trends, outperforming open-weight models up to larger (e.g., CWM by Meta, Qwen3-Coder-30B) and surpassing/matching efficiency-focused commercial models (e.g., GPT-4.1-mini, GPT-5-nano) across multiple SWE tasks. Further analysis reveals that RCL yields higher training sample efficiency and lower inference costs, emphasizing that for building efficient intelligence, repository mastery is a distinct and necessary dimension that complements general coding capability.
AppForge: From Assistant to Independent Developer - Are GPTs Ready for Software Development?
Oct 09, 2025



Large language models (LLMs) have demonstrated remarkable capability in function-level code generation tasks. Unlike isolated functions, real-world applications demand reasoning over the entire software system: developers must orchestrate how different components interact, maintain consistency across states over time, and ensure the application behaves correctly within the lifecycle and framework constraints. Yet, no existing benchmark adequately evaluates whether LLMs can bridge this gap and construct entire software systems from scratch. To address this gap, we propose APPFORGE, a benchmark consisting of 101 software development problems drawn from real-world Android apps. Given a natural language specification detailing the app functionality, a language model is tasked with implementing the functionality into an Android app from scratch. Developing an Android app from scratch requires understanding and coordinating app states, lifecycle management, and asynchronous operations, calling for LLMs to generate context-aware, robust, and maintainable code. To construct APPFORGE, we design a multi-agent system to automatically summarize the main functionalities from app documents and navigate the app to synthesize test cases validating the functional correctness of app implementation. Following rigorous manual verification by Android development experts, APPFORGE incorporates the test cases within an automated evaluation framework that enables reproducible assessment without human intervention, making it easily adoptable for future research. Our evaluation on 12 flagship LLMs show that all evaluated models achieve low effectiveness, with the best-performing model (GPT-5) developing only 18.8% functionally correct applications, highlighting fundamental limitations in current models' ability to handle complex, multi-component software engineering challenges.
Efficiency Robustness of Dynamic Deep Learning Systems
Jun 12, 2025Deep Learning Systems (DLSs) are increasingly deployed in real-time applications, including those in resourceconstrained environments such as mobile and IoT devices. To address efficiency challenges, Dynamic Deep Learning Systems (DDLSs) adapt inference computation based on input complexity, reducing overhead. While this dynamic behavior improves efficiency, such behavior introduces new attack surfaces. In particular, efficiency adversarial attacks exploit these dynamic mechanisms to degrade system performance. This paper systematically explores efficiency robustness of DDLSs, presenting the first comprehensive taxonomy of efficiency attacks. We categorize these attacks based on three dynamic behaviors: (i) attacks on dynamic computations per inference, (ii) attacks on dynamic inference iterations, and (iii) attacks on dynamic output production for downstream tasks. Through an in-depth evaluation, we analyze adversarial strategies that target DDLSs efficiency and identify key challenges in securing these systems. In addition, we investigate existing defense mechanisms, demonstrating their limitations against increasingly popular efficiency attacks and the necessity for novel mitigation strategies to secure future adaptive DDLSs.
Impact Analysis of Inference Time Attack of Perception Sensors on Autonomous Vehicles
May 05, 2025As a safety-critical cyber-physical system, cybersecurity and related safety issues for Autonomous Vehicles (AVs) have been important research topics for a while. Among all the modules on AVs, perception is one of the most accessible attack surfaces, as drivers and AVs have no control over the outside environment. Most current work targeting perception security for AVs focuses on perception correctness. In this work, we propose an impact analysis based on inference time attacks for autonomous vehicles. We demonstrate in a simulation system that such inference time attacks can also threaten the safety of both the ego vehicle and other traffic participants.
Dynamic Benchmarking of Reasoning Capabilities in Code Large Language Models Under Data Contamination
Mar 06, 2025
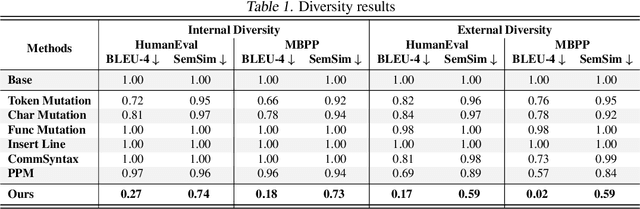
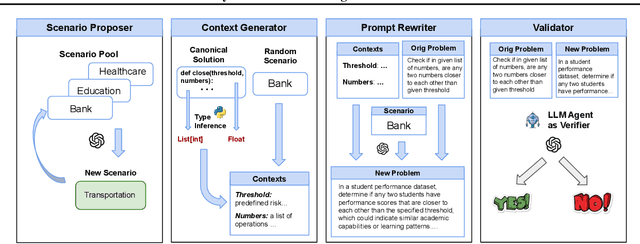
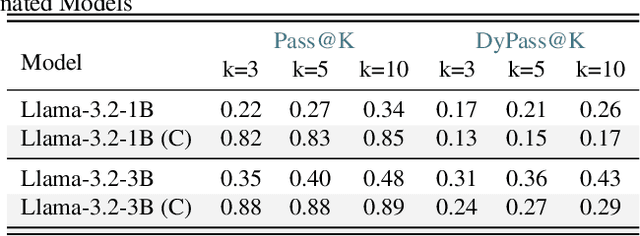
The rapid evolution of code largelanguage models underscores the need for effective and transparent benchmarking of their reasoning capabilities. However, the current benchmarking approach heavily depends on publicly available, human-created datasets. The widespread use of these fixed benchmark datasets makes the benchmarking process to be static and thus particularly susceptible to data contamination, an unavoidable consequence of the extensive data collection processes used to train Code LLMs. Existing approaches that address data contamination often suffer from human effort limitations and imbalanced problem complexity. To tackle these challenges, we propose \tool, a novel benchmarking suite for evaluating Code LLMs under potential data contamination. Given a seed programming problem, \tool employs multiple agents to extract and modify the context without altering the core logic, generating semantically equivalent variations. We introduce a dynamic data generation methods and conduct empirical studies on two seed datasets across 21 Code LLMs. Results show that \tool effectively benchmarks reasoning capabilities under contamination risks while generating diverse problem sets to ensure consistent and reliable evaluations.
Recent Advances in Large Langauge Model Benchmarks against Data Contamination: From Static to Dynamic Evaluation
Feb 23, 2025Data contamination has received increasing attention in the era of large language models (LLMs) due to their reliance on vast Internet-derived training corpora. To mitigate the risk of potential data contamination, LLM benchmarking has undergone a transformation from static to dynamic benchmarking. In this work, we conduct an in-depth analysis of existing static to dynamic benchmarking methods aimed at reducing data contamination risks. We first examine methods that enhance static benchmarks and identify their inherent limitations. We then highlight a critical gap-the lack of standardized criteria for evaluating dynamic benchmarks. Based on this observation, we propose a series of optimal design principles for dynamic benchmarking and analyze the limitations of existing dynamic benchmarks. This survey provides a concise yet comprehensive overview of recent advancements in data contamination research, offering valuable insights and a clear guide for future research efforts. We maintain a GitHub repository to continuously collect both static and dynamic benchmarking methods for LLMs. The repository can be found at this link.
Efficient Detection Framework Adaptation for Edge Computing: A Plug-and-play Neural Network Toolbox Enabling Edge Deployment
Dec 24, 2024Edge computing has emerged as a key paradigm for deploying deep learning-based object detection in time-sensitive scenarios. However, existing edge detection methods face challenges: 1) difficulty balancing detection precision with lightweight models, 2) limited adaptability of generalized deployment designs, and 3) insufficient real-world validation. To address these issues, we propose the Edge Detection Toolbox (ED-TOOLBOX), which utilizes generalizable plug-and-play components to adapt object detection models for edge environments. Specifically, we introduce a lightweight Reparameterized Dynamic Convolutional Network (Rep-DConvNet) featuring weighted multi-shape convolutional branches to enhance detection performance. Additionally, we design a Sparse Cross-Attention (SC-A) network with a localized-mapping-assisted self-attention mechanism, enabling a well-crafted joint module for adaptive feature transfer. For real-world applications, we incorporate an Efficient Head into the YOLO framework to accelerate edge model optimization. To demonstrate practical impact, we identify a gap in helmet detection -- overlooking band fastening, a critical safety factor -- and create the Helmet Band Detection Dataset (HBDD). Using ED-TOOLBOX-optimized models, we address this real-world task. Extensive experiments validate the effectiveness of ED-TOOLBOX, with edge detection models outperforming six state-of-the-art methods in visual surveillance simulations, achieving real-time and accurate performance. These results highlight ED-TOOLBOX as a superior solution for edge object detection.
FedDTPT: Federated Discrete and Transferable Prompt Tuning for Black-Box Large Language Models
Nov 01, 2024In recent years, large language models (LLMs) have significantly advanced the field of natural language processing (NLP). By fine-tuning LLMs with data from specific scenarios, these foundation models can better adapt to various downstream tasks. However, the fine-tuning process poses privacy leakage risks, particularly in centralized data processing scenarios. To address user privacy concerns, federated learning (FL) has been introduced to mitigate the risks associated with centralized data collection from multiple sources. Nevertheless, the privacy of LLMs themselves is equally critical, as potential malicious attacks challenge their security, an issue that has received limited attention in current research. Consequently, establishing a trusted multi-party model fine-tuning environment is essential. Additionally, the local deployment of large LLMs incurs significant storage costs and high computational demands. To address these challenges, we propose for the first time a federated discrete and transferable prompt tuning, namely FedDTPT, for black-box large language models. In the client optimization phase, we adopt a token-level discrete prompt optimization method that leverages a feedback loop based on prediction accuracy to drive gradient-free prompt optimization through the MLM API. For server optimization, we employ an attention mechanism based on semantic similarity to filter all local prompt tokens, along with an embedding distance elbow detection and DBSCAN clustering strategy to enhance the filtering process. Experimental results demonstrate that, compared to state-of-the-art methods, our approach achieves higher accuracy, reduced communication overhead, and robustness to non-iid data in a black-box setting. Moreover, the optimized prompts are transferable.
Task-Oriented Real-time Visual Inference for IoVT Systems: A Co-design Framework of Neural Networks and Edge Deployment
Oct 29, 2024As the volume of image data grows, data-oriented cloud computing in Internet of Video Things (IoVT) systems encounters latency issues. Task-oriented edge computing addresses this by shifting data analysis to the edge. However, limited computational power of edge devices poses challenges for executing visual tasks. Existing methods struggle to balance high model performance with low resource consumption; lightweight neural networks often underperform, while device-specific models designed by Neural Architecture Search (NAS) fail to adapt to heterogeneous devices. For these issues, we propose a novel co-design framework to optimize neural network architecture and deployment strategies during inference for high-throughput. Specifically, it implements a dynamic model structure based on re-parameterization, coupled with a Roofline-based model partitioning strategy to enhance the computational performance of edge devices. We also employ a multi-objective co-optimization approach to balance throughput and accuracy. Additionally, we derive mathematical consistency and convergence of partitioned models. Experimental results demonstrate significant improvements in throughput (12.05\% on MNIST, 18.83\% on ImageNet) and superior classification accuracy compared to baseline algorithms. Our method consistently achieves stable performance across different devices, underscoring its adaptability. Simulated experiments further confirm its efficacy in high-accuracy, real-time detection for small objects in IoVT systems.