 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Long-term Value Prediction Framework In Video Ranking
Feb 19, 2026Accurately modeling long-term value (LTV) at the ranking stage of short-video recommendation remains challenging. While delayed feedback and extended engagement have been explored, fine-grained attribution and robust position normalization at billion-scale are still underdeveloped. We propose a practical ranking-stage LTV framework addressing three challenges: position bias, attribution ambiguity, and temporal limitations. (1) Position bias: We introduce a Position-aware Debias Quantile (PDQ) module that normalizes engagement via quantile-based distributions, enabling position-robust LTV estimation without architectural changes. (2) Attribution ambiguity: We propose a multi-dimensional attribution module that learns continuous attribution strengths across contextual, behavioral, and content signals, replacing static rules to capture nuanced inter-video influence. A customized hybrid loss with explicit noise filtering improves causal clarity. (3) Temporal limitations: We present a cross-temporal author modeling module that builds censoring-aware, day-level LTV targets to capture creator-driven re-engagement over longer horizons; the design is extensible to other dimensions (e.g., topics, styles). Offline studies and online A/B tests show significant improvements in LTV metrics and stable trade-offs with short-term objectives. Implemented as task augmentation within an existing ranking model, the framework supports efficient training and serving, and has been deployed at billion-scale in Taobao's production system, delivering sustained engagement gains while remaining compatible with industrial constraints.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022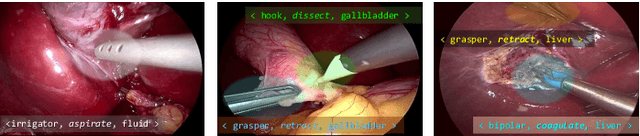

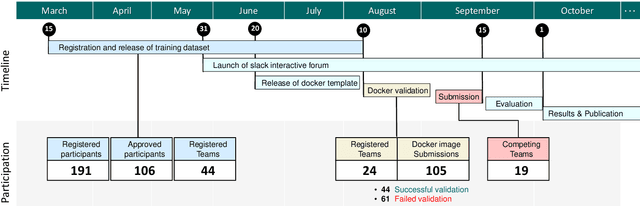
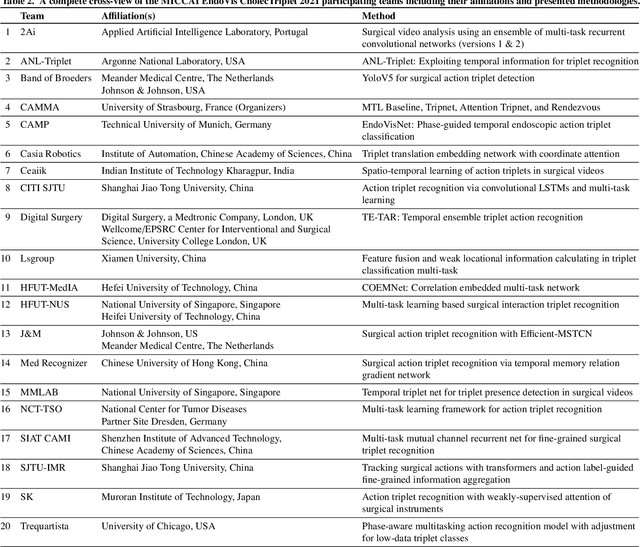
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
LT4REC:A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System
Aug 22, 2020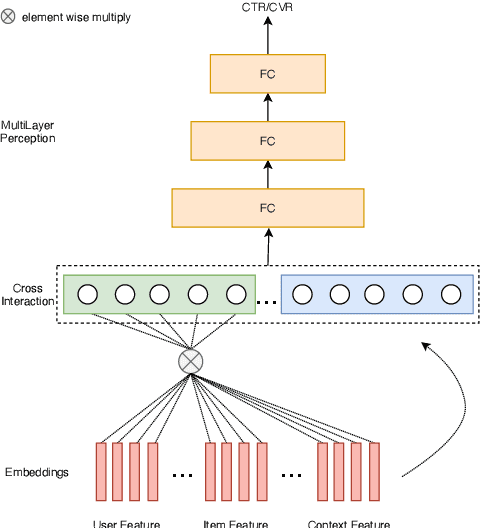

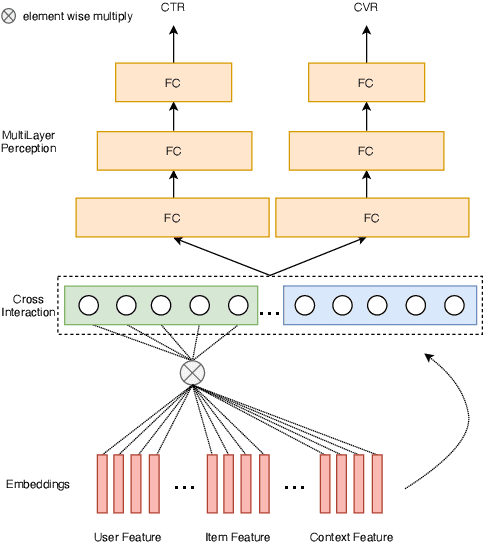
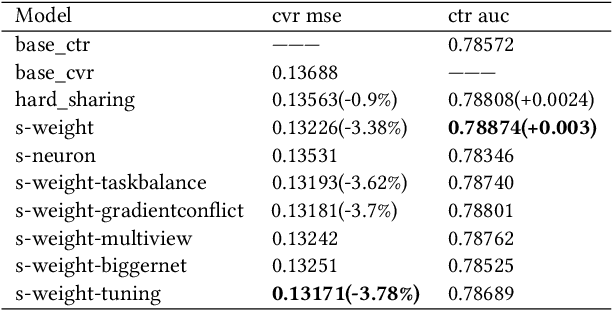
Click-through rate prediction (CTR) and post-click conversion rate prediction (CVR) play key roles across all industrial ranking systems, such as recommendation systems, online advertising, and search engines. Different from the extensive research on CTR, there is much less research on CVR estimation, whose main challenge is extreme data sparsity with one or two orders of magnitude reduction in the number of samples than CTR. People try to solve this problem with the paradigm of multi-task learning with the sufficient samples of CTR, but the typical hard sharing method can't effectively solve this problem, because it is difficult to analyze which parts of network components can be shared and which parts are in conflict, i.e., there is a large inaccuracy with artificially designed neurons sharing. In this paper, we model CVR in a brand-new method by adopting the lottery-ticket-hypothesis-based sparse sharing multi-task learning, which can automatically and flexibly learn which neuron weights to be shared without artificial experience. Experiments on the dataset gathered from traffic logs of Tencent video's recommendation system demonstrate that sparse sharing in the CVR model significantly outperforms competitive methods. Due to the nature of weight sparsity in sparse sharing, it can also significantly reduce computational complexity and memory usage which are very important in the industrial recommendation system.