 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Imitation Learning for End-to-End Mobile Manipulation
Feb 15, 2022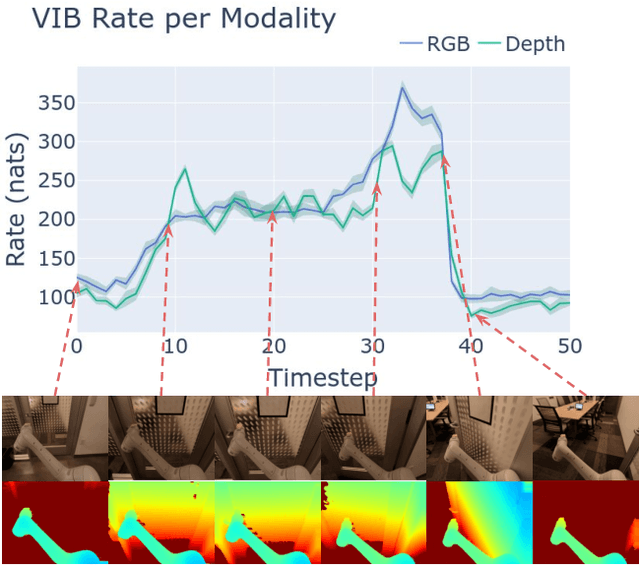
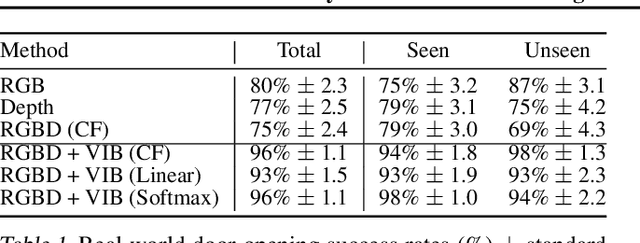
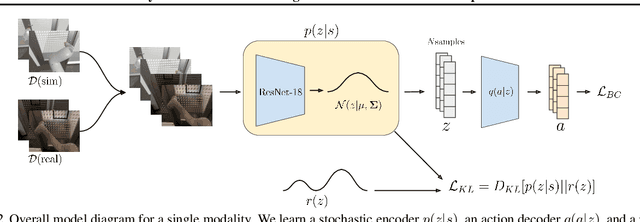
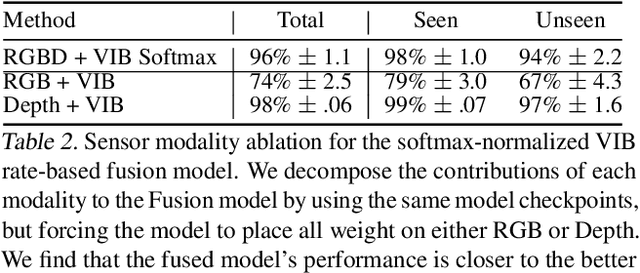
In this work we investigate and demonstrate benefits of a Bayesian approach to imitation learning from multiple sensor inputs, as applied to the task of opening office doors with a mobile manipulator. Augmenting policies with additional sensor inputs, such as RGB + depth cameras, is a straightforward approach to improving robot perception capabilities, especially for tasks that may favor different sensors in different situations. As we scale multi-sensor robotic learning to unstructured real-world settings (e.g. offices, homes) and more complex robot behaviors, we also increase reliance on simulators for cost, efficiency, and safety. Consequently, the sim-to-real gap across multiple sensor modalities also increases, making simulated validation more difficult. We show that using the Variational Information Bottleneck (Alemi et al., 2016) to regularize convolutional neural networks improves generalization to held-out domains and reduces the sim-to-real gap in a sensor-agnostic manner. As a side effect, the learned embeddings also provide useful estimates of model uncertainty for each sensor. We demonstrate that our method is able to help close the sim-to-real gap and successfully fuse RGB and depth modalities based on understanding of the situational uncertainty of each sensor. In a real-world office environment, we achieve 96% task success, improving upon the baseline by +16%.
Practical Imitation Learning in the Real World via Task Consistency Loss
Feb 03, 2022

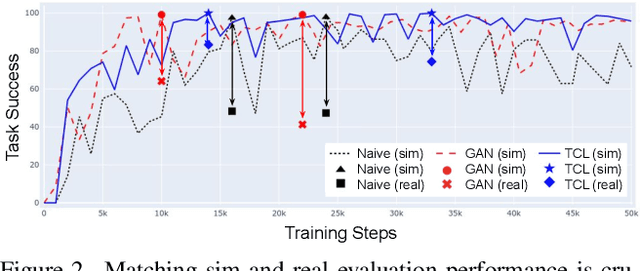
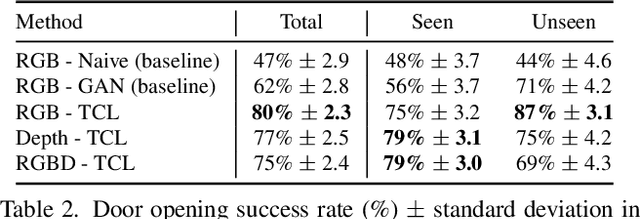
Recent work in visual end-to-end learning for robotics has shown the promise of imitation learning across a variety of tasks. Such approaches are expensive both because they require large amounts of real world training demonstrations and because identifying the best model to deploy in the real world requires time-consuming real-world evaluations. These challenges can be mitigated by simulation: by supplementing real world data with simulated demonstrations and using simulated evaluations to identify high performing policies. However, this introduces the well-known "reality gap" problem, where simulator inaccuracies decorrelate performance in simulation from that of reality. In this paper, we build on top of prior work in GAN-based domain adaptation and introduce the notion of a Task Consistency Loss (TCL), a self-supervised loss that encourages sim and real alignment both at the feature and action-prediction levels. We demonstrate the effectiveness of our approach by teaching a mobile manipulator to autonomously approach a door, turn the handle to open the door, and enter the room. The policy performs control from RGB and depth images and generalizes to doors not encountered in training data. We achieve 80% success across ten seen and unseen scenes using only ~16.2 hours of teleoperated demonstrations in sim and real. To the best of our knowledge, this is the first work to tackle latched door opening from a purely end-to-end learning approach, where the task of navigation and manipulation are jointly modeled by a single neural network.
Auto-Tuned Sim-to-Real Transfer
Apr 15, 2021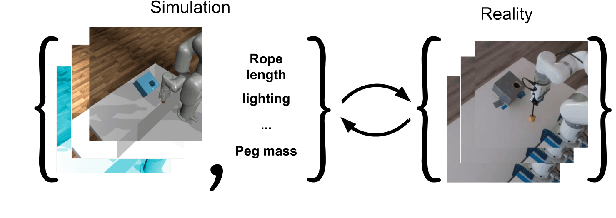
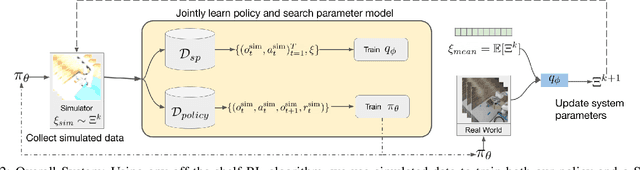
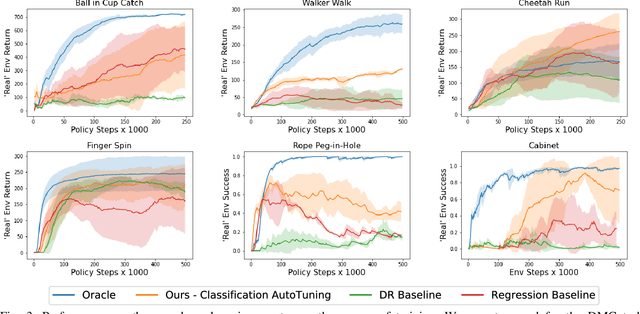
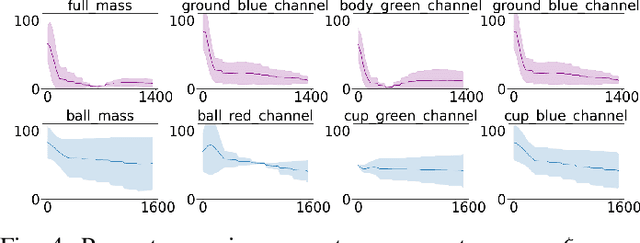
Policies trained in simulation often fail when transferred to the real world due to the `reality gap' where the simulator is unable to accurately capture the dynamics and visual properties of the real world. Current approaches to tackle this problem, such as domain randomization, require prior knowledge and engineering to determine how much to randomize system parameters in order to learn a policy that is robust to sim-to-real transfer while also not being too conservative. We propose a method for automatically tuning simulator system parameters to match the real world using only raw RGB images of the real world without the need to define rewards or estimate state. Our key insight is to reframe the auto-tuning of parameters as a search problem where we iteratively shift the simulation system parameters to approach the real-world system parameters. We propose a Search Param Model (SPM) that, given a sequence of observations and actions and a set of system parameters, predicts whether the given parameters are higher or lower than the true parameters used to generate the observations. We evaluate our method on multiple robotic control tasks in both sim-to-sim and sim-to-real transfer, demonstrating significant improvement over naive domain randomization. Project videos and code at https://yuqingd.github.io/autotuned-sim2real/
Group Surfing: A Pedestrian-Based Approach to Sidewalk Robot Navigation
Apr 13, 2021
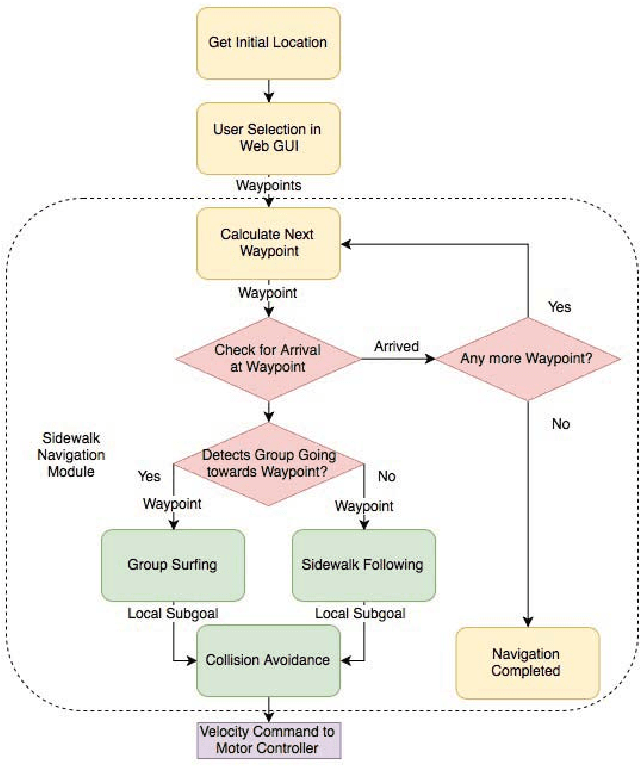
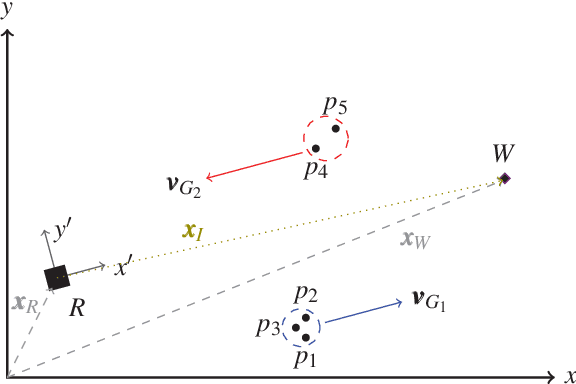
In this paper, we propose a novel navigation system for mobile robots in pedestrian-rich sidewalk environments. Sidewalks are unique in that the pedestrian-shared space has characteristics of both roads and indoor spaces. Like vehicles on roads, pedestrian movement often manifests as linear flows in opposing directions. On the other hand, pedestrians also form crowds and can exhibit much more random movements than vehicles. Classical algorithms are insufficient for safe navigation around pedestrians and remaining on the sidewalk space. Thus, our approach takes advantage of natural human motion to allow a robot to adapt to sidewalk navigation in a safe and socially-compliant manner. We developed a \textit{group surfing} method which aims to imitate the optimal pedestrian group for bringing the robot closer to its goal. For pedestrian-sparse environments, we propose a sidewalk edge detection and following method. Underlying these two navigation methods, the collision avoidance scheme is human-aware. The integrated navigation stack is evaluated and demonstrated in simulation. A hardware demonstration is also presented.
Wirelessly Powered Federated Edge Learning: Optimal Tradeoffs Between Convergence and Power Transfer
Feb 24, 2021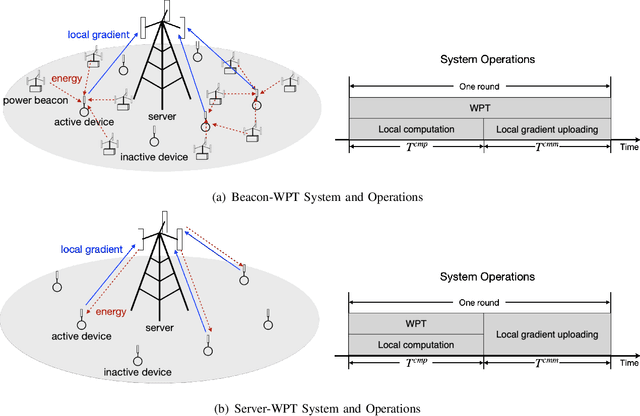
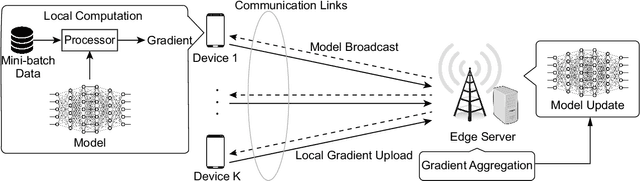
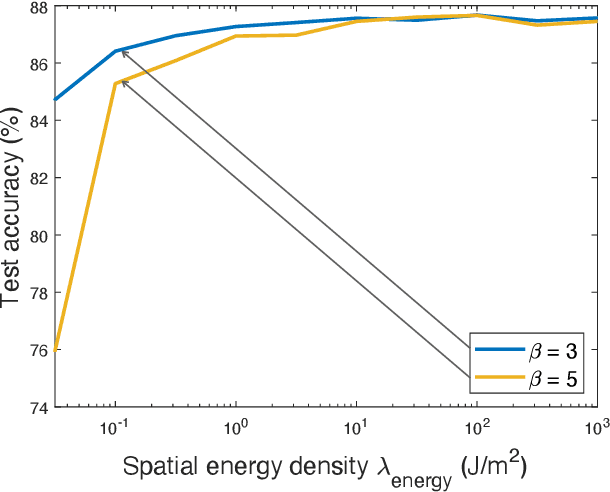
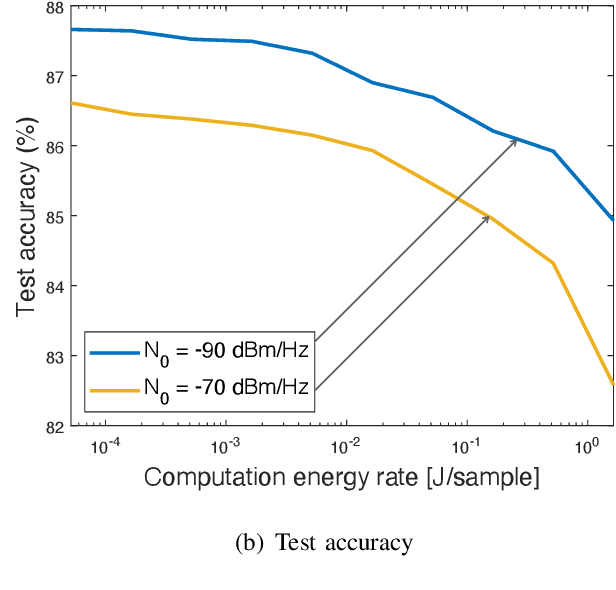
Federated edge learning (FEEL) is a widely adopted framework for training an artificial intelligence (AI) model distributively at edge devices to leverage their data while preserving their data privacy. The execution of a power-hungry learning task at energy-constrained devices is a key challenge confronting the implementation of FEEL. To tackle the challenge, we propose the solution of powering devices using wireless power transfer (WPT). To derive guidelines on deploying the resultant wirelessly powered FEEL (WP-FEEL) system, this work aims at the derivation of the tradeoff between the model convergence and the settings of power sources in two scenarios: 1) the transmission power and density of power-beacons (dedicated charging stations) if they are deployed, or otherwise 2) the transmission power of a server (access-point). The development of the proposed analytical framework relates the accuracy of distributed stochastic gradient estimation to the WPT settings, the randomness in both communication and WPT links, and devices' computation capacities. Furthermore, the local-computation at devices (i.e., mini-batch size and processor clock frequency) is optimized to efficiently use the harvested energy for gradient estimation. The resultant learning-WPT tradeoffs reveal the simple scaling laws of the model-convergence rate with respect to the transferred energy as well as the devices' computational energy efficiencies. The results provide useful guidelines on WPT provisioning to provide a guaranteer on learning performance. They are corroborated by experimental results using a real dataset.
Robust Reinforcement Learning using Adversarial Populations
Aug 04, 2020
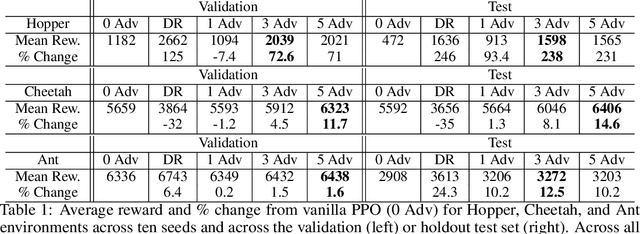
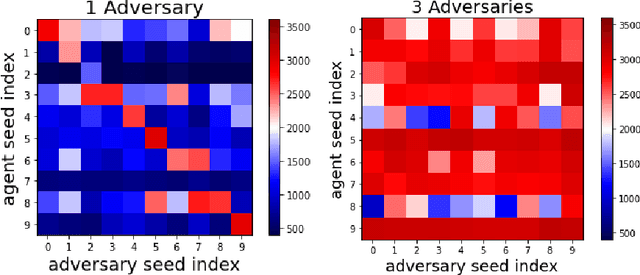
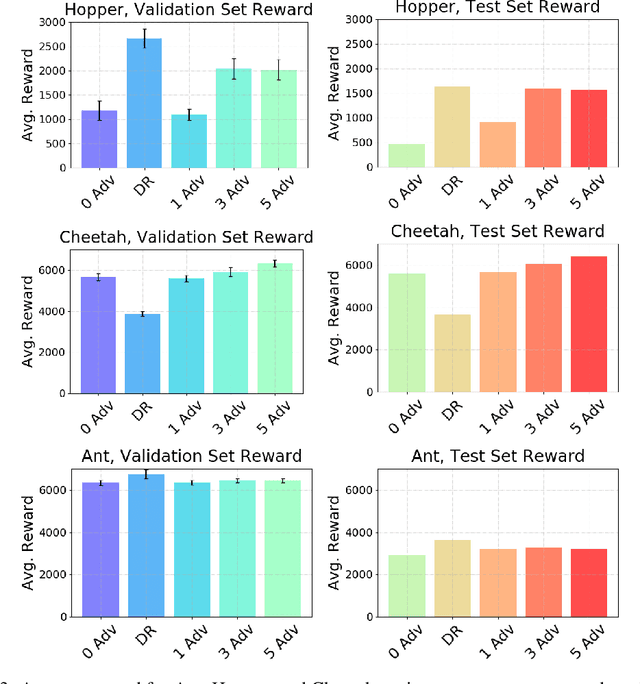
Reinforcement Learning (RL) is an effective tool for controller design but can struggle with issues of robustness, failing catastrophically when the underlying system dynamics are perturbed. The Robust RL formulation tackles this by adding worst-case adversarial noise to the dynamics and constructing the noise distribution as the solution to a zero-sum minimax game. However, existing work on learning solutions to the Robust RL formulation has primarily focused on training a single RL agent against a single adversary. In this work, we demonstrate that using a single adversary does not consistently yield robustness to dynamics variations under standard parametrizations of the adversary; the resulting policy is highly exploitable by new adversaries. We propose a population-based augmentation to the Robust RL formulation in which we randomly initialize a population of adversaries and sample from the population uniformly during training. We empirically validate across robotics benchmarks that the use of an adversarial population results in a more robust policy that also improves out-of-distribution generalization. Finally, we demonstrate that this approach provides comparable robustness and generalization as domain randomization on these benchmarks while avoiding a ubiquitous domain randomization failure mode.
AvE: Assistance via Empowerment
Jul 09, 2020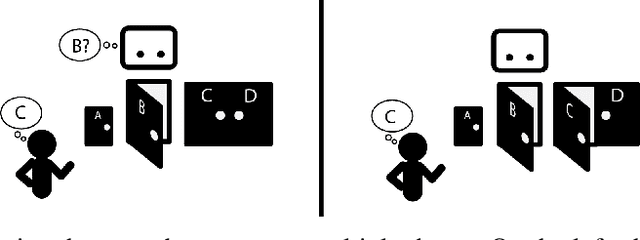

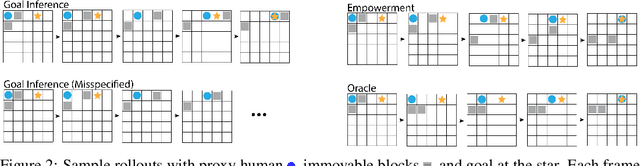

One difficulty in using artificial agents for human-assistive applications lies in the challenge of accurately assisting with a person's goal(s). Existing methods tend to rely on inferring the human's goal, which is challenging when there are many potential goals or when the set of candidate goals is difficult to identify. We propose a new paradigm for assistance by instead increasing the human's ability to control their environment, and formalize this approach by augmenting reinforcement learning with human empowerment. This task-agnostic objective preserves the person's autonomy and ability to achieve any eventual state. We test our approach against assistance based on goal inference, highlighting scenarios where our method overcomes failure modes stemming from goal ambiguity or misspecification. As existing methods for estimating empowerment in continuous domains are computationally hard, precluding its use in real time learned assistance, we also propose an efficient empowerment-inspired proxy metric. Using this, we are able to successfully demonstrate our method in a shared autonomy user study for a challenging simulated teleoperation task with human-in-the-loop training.
High-Dimensional Stochastic Gradient Quantization for Communication-Efficient Edge Learning
Oct 09, 2019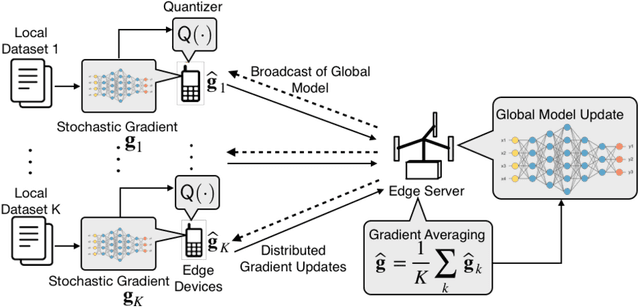
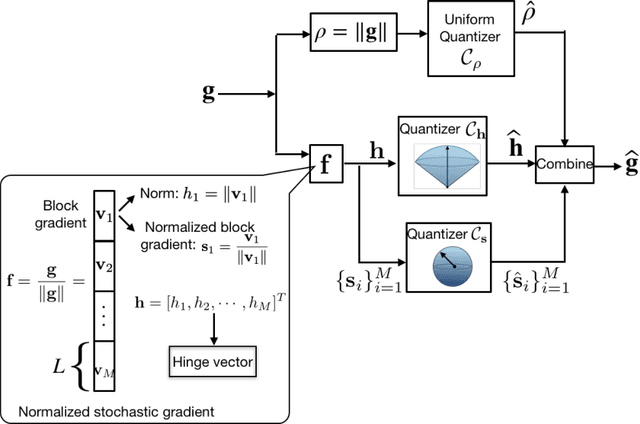
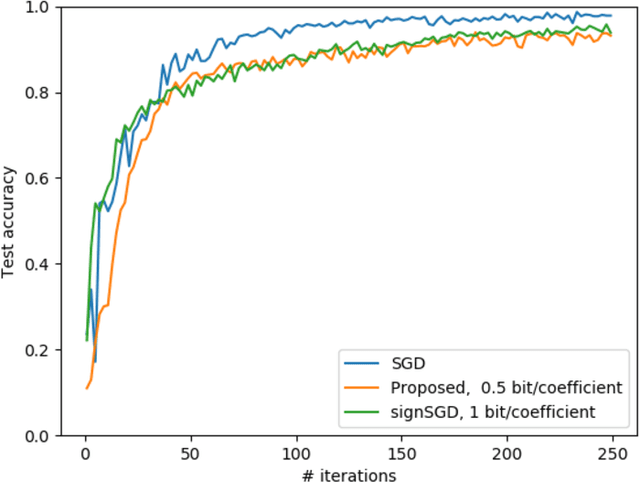
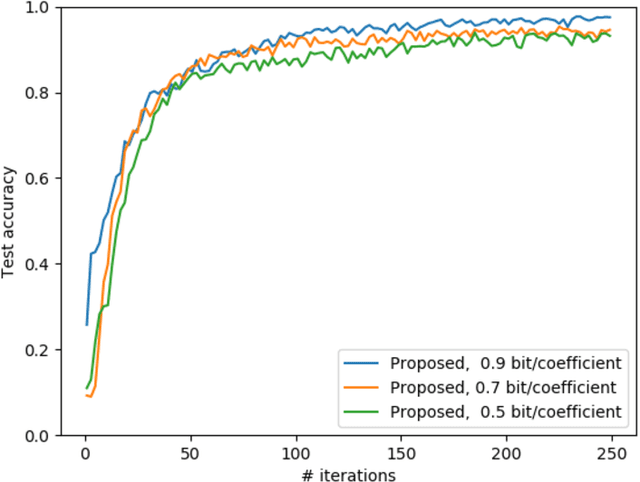
Edge machine learning involves the deployment of learning algorithms at the wireless network edge so as to leverage massive mobile data for enabling intelligent applications. The mainstream edge learning approach, federated learning, has been developed based on distributed gradient descent. Based on the approach, stochastic gradients are computed at edge devices and then transmitted to an edge server for updating a global AI model. Since each stochastic gradient is typically high-dimensional (with millions to billions of coefficients), communication overhead becomes a bottleneck for edge learning. To address this issue, we propose in this work a novel framework of hierarchical stochastic gradient quantization and study its effect on the learning performance. First, the framework features a practical hierarchical architecture for decomposing the stochastic gradient into its norm and normalized block gradients, and efficiently quantizes them using a uniform quantizer and a low-dimensional codebook on a Grassmann manifold, respectively. Subsequently, the quantized normalized block gradients are scaled and cascaded to yield the quantized normalized stochastic gradient using a so-called hinge vector designed under the criterion of minimum distortion. The hinge vector is also efficiently compressed using another low-dimensional Grassmannian quantizer. The other feature of the framework is a bit-allocation scheme for reducing the quantization error. The scheme determines the resolutions of the low-dimensional quantizers in the proposed framework. The framework is proved to guarantee model convergency by analyzing the convergence rate as a function of the quantization bits. Furthermore, by simulation, our design is shown to substantially reduce the communication overhead compared with the state-of-the-art signSGD scheme, while both achieve similar learning accuracies.
Energy-Efficient Radio Resource Allocation for Federated Edge Learning
Jul 13, 2019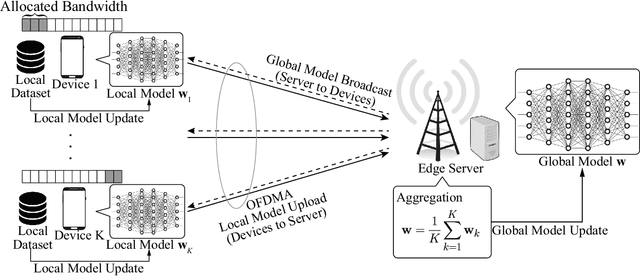
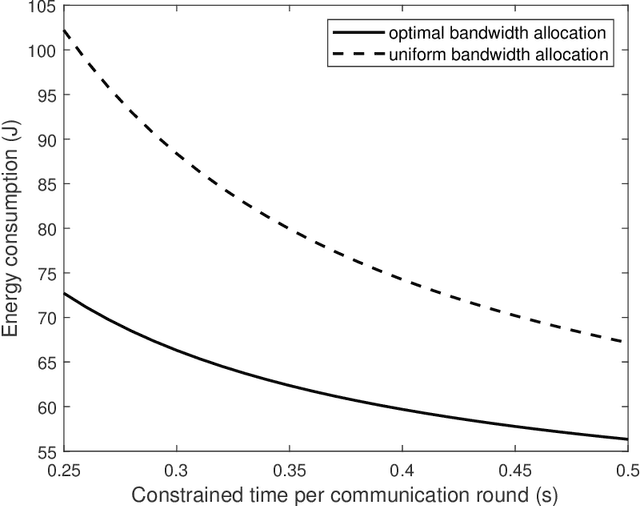
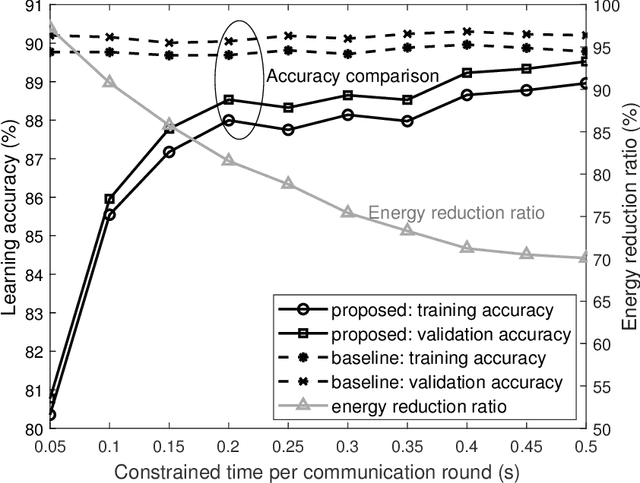
Edge machine learning involves the development of learning algorithms at the network edge to leverage massive distributed data and computation resources. Among others, the framework of federated edge learning (FEEL) is particularly promising for its data-privacy preservation. FEEL coordinates global model training at a server and local model training at edge devices over wireless links. In this work, we explore the new direction of energy-efficient radio resource management (RRM) for FEEL. To reduce devices' energy consumption, we propose energy-efficient strategies for bandwidth allocation and scheduling. They adapt to devices' channel states and computation capacities so as to reduce their sum energy consumption while warranting learning performance. In contrast with the traditional rate-maximization designs, the derived optimal policies allocate more bandwidth to those scheduled devices with weaker channels or poorer computation capacities, which are the bottlenecks of synchronized model updates in FEEL. On the other hand, the scheduling priority function derived in closed form gives preferences to devices with better channels and computation capacities. Substantial energy reduction contributed by the proposed strategies is demonstrated in learning experiments.
Towards an Intelligent Edge: Wireless Communication Meets Machine Learning
Sep 02, 2018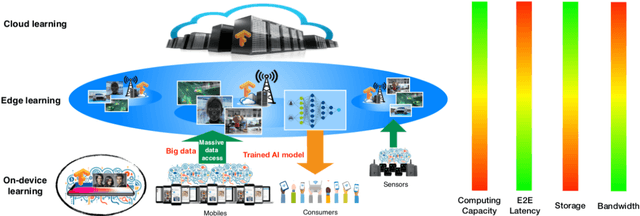
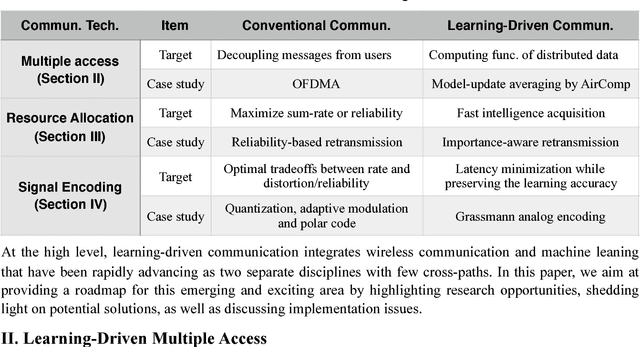
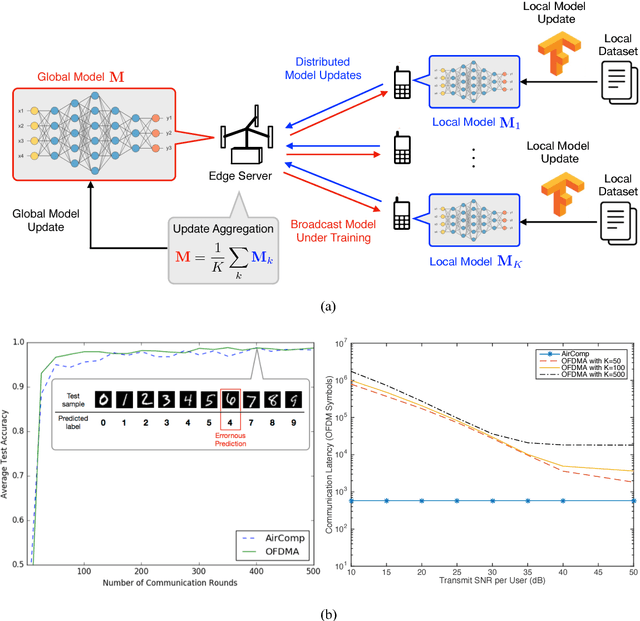
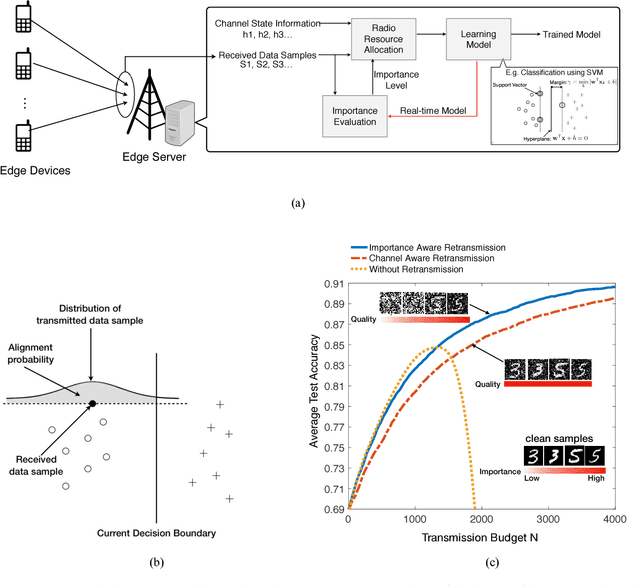
The recent revival of artificial intelligence (AI) is revolutionizing almost every branch of science and technology. Given the ubiquitous smart mobile gadgets and Internet of Things (IoT) devices, it is expected that a majority of intelligent applications will be deployed at the edge of wireless networks. This trend has generated strong interests in realizing an "intelligent edge" to support AI-enabled applications at various edge devices. Accordingly, a new research area, called edge learning, emerges, which crosses and revolutionizes two disciplines: wireless communication and machine learning. A major theme in edge learning is to overcome the limited computing power, as well as limited data, at each edge device. This is accomplished by leveraging the mobile edge computing (MEC) platform and exploiting the massive data distributed over a large number of edge devices. In such systems, learning from distributed data and communicating between the edge server and devices are two critical and coupled aspects, and their fusion poses many new research challenges. This article advocates a new set of design principles for wireless communication in edge learning, collectively called learning-driven communication. Illustrative examples are provided to demonstrate the effectiveness of these design principles, and unique research opportunities are identified.