 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntersectional Fairness in Vision-Language Models for Medical Image Disease Classification
Dec 24, 2025Medical artificial intelligence (AI) systems, particularly multimodal vision-language models (VLM), often exhibit intersectional biases where models are systematically less confident in diagnosing marginalised patient subgroups. Such bias can lead to higher rates of inaccurate and missed diagnoses due to demographically skewed data and divergent distributions of diagnostic certainty. Current fairness interventions frequently fail to address these gaps or compromise overall diagnostic performance to achieve statistical parity among the subgroups. In this study, we developed Cross-Modal Alignment Consistency (CMAC-MMD), a training framework that standardises diagnostic certainty across intersectional patient subgroups. Unlike traditional debiasing methods, this approach equalises the model's decision confidence without requiring sensitive demographic data during clinical inference. We evaluated this approach using 10,015 skin lesion images (HAM10000) with external validation on 12,000 images (BCN20000), and 10,000 fundus images for glaucoma detection (Harvard-FairVLMed), stratifying performance by intersectional age, gender, and race attributes. In the dermatology cohort, the proposed method reduced the overall intersectional missed diagnosis gap (difference in True Positive Rate, $Δ$TPR) from 0.50 to 0.26 while improving the overall Area Under the Curve (AUC) from 0.94 to 0.97 compared to standard training. Similarly, for glaucoma screening, the method reduced $Δ$TPR from 0.41 to 0.31, achieving a better AUC of 0.72 (vs. 0.71 baseline). This establishes a scalable framework for developing high-stakes clinical decision support systems that are both accurate and can perform equitably across diverse patient subgroups, ensuring reliable performance without increasing privacy risks.
LabelGS: Label-Aware 3D Gaussian Splatting for 3D Scene Segmentation
Aug 27, 20253D Gaussian Splatting (3DGS) has emerged as a novel explicit representation for 3D scenes, offering both high-fidelity reconstruction and efficient rendering. However, 3DGS lacks 3D segmentation ability, which limits its applicability in tasks that require scene understanding. The identification and isolating of specific object components is crucial. To address this limitation, we propose Label-aware 3D Gaussian Splatting (LabelGS), a method that augments the Gaussian representation with object label.LabelGS introduces cross-view consistent semantic masks for 3D Gaussians and employs a novel Occlusion Analysis Model to avoid overfitting occlusion during optimization, Main Gaussian Labeling model to lift 2D semantic prior to 3D Gaussian and Gaussian Projection Filter to avoid Gaussian label conflict. Our approach achieves effective decoupling of Gaussian representations and refines the 3DGS optimization process through a random region sampling strategy, significantly improving efficiency. Extensive experiments demonstrate that LabelGS outperforms previous state-of-the-art methods, including Feature-3DGS, in the 3D scene segmentation task. Notably, LabelGS achieves a remarkable 22X speedup in training compared to Feature-3DGS, at a resolution of 1440X1080. Our code will be at https://github.com/garrisonz/LabelGS.
Emergent morphogenesis via planar fabrication enabled by a reduced model of composites
Aug 11, 2025The ability to engineer complex three-dimensional shapes from planar sheets with precise, programmable control underpins emerging technologies in soft robotics, reconfigurable devices, and functional materials. Here, we present a reduced-order numerical and experimental framework for a bilayer system consisting of a stimuli-responsive thermoplastic sheet (Shrinky Dink) bonded to a kirigami-patterned, inert plastic layer. Upon uniform heating, the active layer contracts while the patterned layer constrains in-plane stretch but allows out-of-plane bending, yielding programmable 3D morphologies from simple planar precursors. Our approach enables efficient computational design and scalable manufacturing of 3D forms with a single-layer reduced model that captures the coupled mechanics of stretching and bending. Unlike traditional bilayer modeling, our framework collapses the multilayer composite into a single layer of nodes and elements, reducing the degrees of freedom and enabling simulation on a 2D geometry. This is achieved by introducing a novel energy formulation that captures the coupling between in-plane stretch mismatch and out-of-plane bending - extending beyond simple isotropic linear elastic models. Experimentally, we establish a fully planar, repeatable fabrication protocol using a stimuli-responsive thermoplastic and a laser-cut inert plastic layer. The programmed strain mismatch drives an array of 3D morphologies, such as bowls, canoes, and flower petals, all verified by both simulation and physical prototypes.
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers
May 26, 2025Large Language Models have achieved remarkable success in natural language processing tasks, with Reinforcement Learning playing a key role in adapting them to specific applications. However, obtaining ground truth answers for training LLMs in mathematical problem-solving is often challenging, costly, and sometimes unfeasible. This research delves into the utilization of format and length as surrogate signals to train LLMs for mathematical problem-solving, bypassing the need for traditional ground truth answers.Our study shows that a reward function centered on format correctness alone can yield performance improvements comparable to the standard GRPO algorithm in early phases. Recognizing the limitations of format-only rewards in the later phases, we incorporate length-based rewards. The resulting GRPO approach, leveraging format-length surrogate signals, not only matches but surpasses the performance of the standard GRPO algorithm relying on ground truth answers in certain scenarios, achieving 40.0\% accuracy on AIME2024 with a 7B base model. Through systematic exploration and experimentation, this research not only offers a practical solution for training LLMs to solve mathematical problems and reducing the dependence on extensive ground truth data collection, but also reveals the essence of why our label-free approach succeeds: base model is like an excellent student who has already mastered mathematical and logical reasoning skills, but performs poorly on the test paper, it simply needs to develop good answering habits to achieve outstanding results in exams , in other words, to unlock the capabilities it already possesses.
FairZK: A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 19, 2025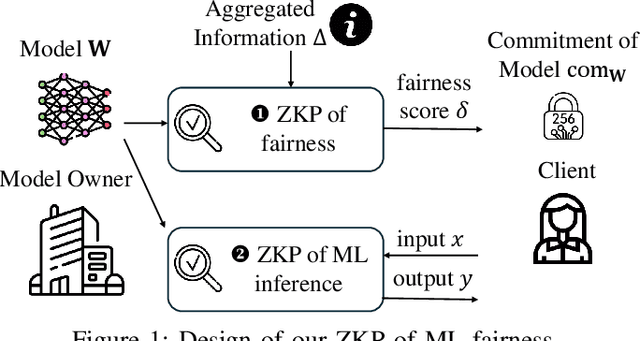

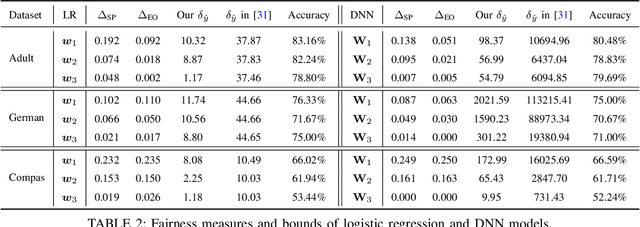
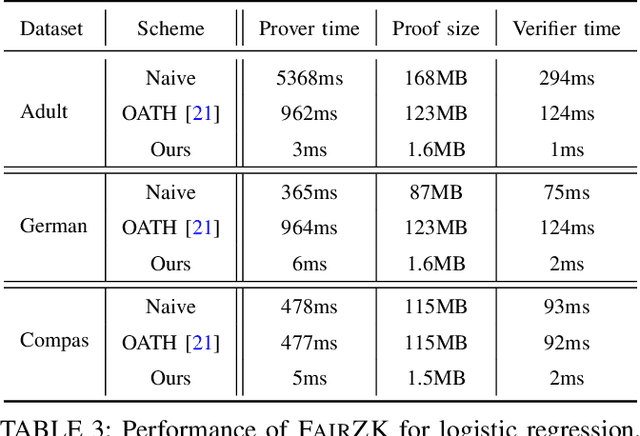
With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.
A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 12, 2025With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
SleepNetZero: Zero-Burden Zero-Shot Reliable Sleep Staging With Neural Networks Based on Ballistocardiograms
Oct 30, 2024Sleep monitoring plays a crucial role in maintaining good health, with sleep staging serving as an essential metric in the monitoring process. Traditional methods, utilizing medical sensors like EEG and ECG, can be effective but often present challenges such as unnatural user experience, complex deployment, and high costs. Ballistocardiography~(BCG), a type of piezoelectric sensor signal, offers a non-invasive, user-friendly, and easily deployable alternative for long-term home monitoring. However, reliable BCG-based sleep staging is challenging due to the limited sleep monitoring data available for BCG. A restricted training dataset prevents the model from generalization across populations. Additionally, transferring to BCG faces difficulty ensuring model robustness when migrating from other data sources. To address these issues, we introduce SleepNetZero, a zero-shot learning based approach for sleep staging. To tackle the generalization challenge, we propose a series of BCG feature extraction methods that align BCG components with corresponding respiratory, cardiac, and movement channels in PSG. This allows models to be trained on large-scale PSG datasets that are diverse in population. For the migration challenge, we employ data augmentation techniques, significantly enhancing generalizability. We conducted extensive training and testing on large datasets~(12393 records from 9637 different subjects), achieving an accuracy of 0.803 and a Cohen's Kappa of 0.718. ZeroSleepNet was also deployed in real prototype~(monitoring pads) and tested in actual hospital settings~(265 users), demonstrating an accuracy of 0.697 and a Cohen's Kappa of 0.589. To the best of our knowledge, this work represents the first known reliable BCG-based sleep staging effort and marks a significant step towards in-home health monitoring.
Domain-invariant Representation Learning via Segment Anything Model for Blood Cell Classification
Aug 14, 2024Accurate classification of blood cells is of vital significance in the diagnosis of hematological disorders. However, in real-world scenarios, domain shifts caused by the variability in laboratory procedures and settings, result in a rapid deterioration of the model's generalization performance. To address this issue, we propose a novel framework of domain-invariant representation learning (DoRL) via segment anything model (SAM) for blood cell classification. The DoRL comprises two main components: a LoRA-based SAM (LoRA-SAM) and a cross-domain autoencoder (CAE). The advantage of DoRL is that it can extract domain-invariant representations from various blood cell datasets in an unsupervised manner. Specifically, we first leverage the large-scale foundation model of SAM, fine-tuned with LoRA, to learn general image embeddings and segment blood cells. Additionally, we introduce CAE to learn domain-invariant representations across different-domain datasets while mitigating images' artifacts. To validate the effectiveness of domain-invariant representations, we employ five widely used machine learning classifiers to construct blood cell classification models. Experimental results on two public blood cell datasets and a private real dataset demonstrate that our proposed DoRL achieves a new state-of-the-art cross-domain performance, surpassing existing methods by a significant margin. The source code can be available at the URL (https://github.com/AnoK3111/DoRL).
Towards Cross-Domain Single Blood Cell Image Classification via Large-Scale LoRA-based Segment Anything Model
Aug 13, 2024



Accurate classification of blood cells plays a vital role in hematological analysis as it aids physicians in diagnosing various medical conditions. In this study, we present a novel approach for classifying blood cell images known as BC-SAM. BC-SAM leverages the large-scale foundation model of Segment Anything Model (SAM) and incorporates a fine-tuning technique using LoRA, allowing it to extract general image embeddings from blood cell images. To enhance the applicability of BC-SAM across different blood cell image datasets, we introduce an unsupervised cross-domain autoencoder that focuses on learning intrinsic features while suppressing artifacts in the images. To assess the performance of BC-SAM, we employ four widely used machine learning classifiers (Random Forest, Support Vector Machine, Artificial Neural Network, and XGBoost) to construct blood cell classification models and compare them against existing state-of-the-art methods. Experimental results conducted on two publicly available blood cell datasets (Matek-19 and Acevedo-20) demonstrate that our proposed BC-SAM achieves a new state-of-the-art result, surpassing the baseline methods with a significant improvement. The source code of this paper is available at https://github.com/AnoK3111/BC-SAM.