 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning Algorithmic Biases over Graphs
May 20, 2025



The growing enforcement of the right to be forgotten regulations has propelled recent advances in certified (graph) unlearning strategies to comply with data removal requests from deployed machine learning (ML) models. Motivated by the well-documented bias amplification predicament inherent to graph data, here we take a fresh look at graph unlearning and leverage it as a bias mitigation tool. Given a pre-trained graph ML model, we develop a training-free unlearning procedure that offers certifiable bias mitigation via a single-step Newton update on the model weights. This way, we contribute a computationally lightweight alternative to the prevalent training- and optimization-based fairness enhancement approaches, with quantifiable performance guarantees. We first develop a novel fairness-aware nodal feature unlearning strategy along with refined certified unlearning bounds for this setting, whose impact extends beyond the realm of graph unlearning. We then design structural unlearning methods endowed with principled selection mechanisms over nodes and edges informed by rigorous bias analyses. Unlearning these judiciously selected elements can mitigate algorithmic biases with minimal impact on downstream utility (e.g., node classification accuracy). Experimental results over real networks corroborate the bias mitigation efficacy of our unlearning strategies, and delineate markedly favorable utility-complexity trade-offs relative to retraining from scratch using augmented graph data obtained via removals.
FairZK: A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 19, 2025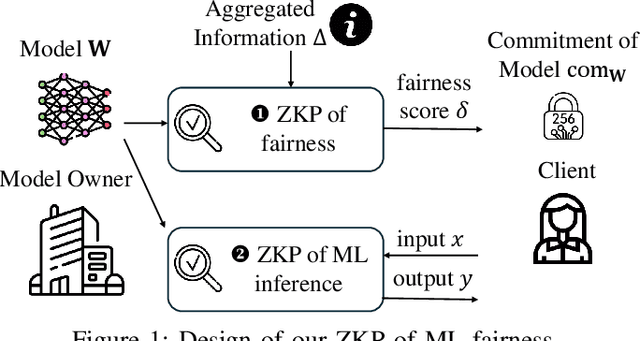

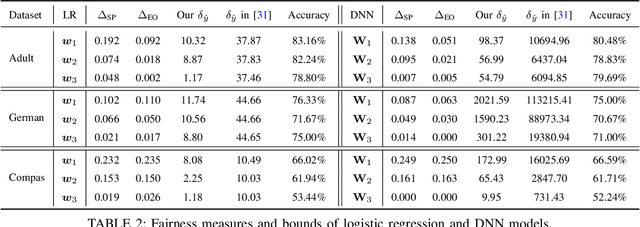
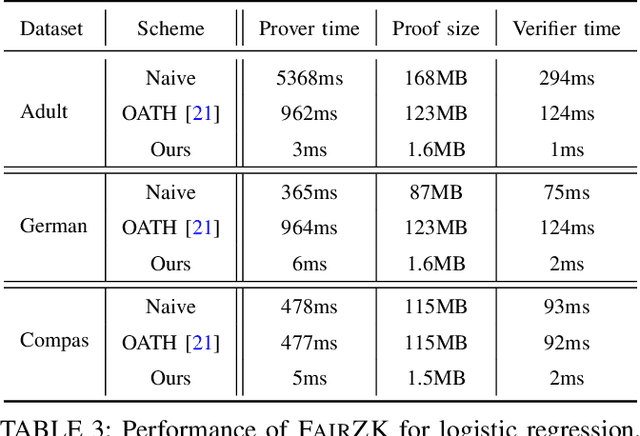
With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.
A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 12, 2025With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.
FairWire: Fair Graph Generation
Feb 06, 2024



Machine learning over graphs has recently attracted growing attention due to its ability to analyze and learn complex relations within critical interconnected systems. However, the disparate impact that is amplified by the use of biased graph structures in these algorithms has raised significant concerns for the deployment of them in real-world decision systems. In addition, while synthetic graph generation has become pivotal for privacy and scalability considerations, the impact of generative learning algorithms on the structural bias has not yet been investigated. Motivated by this, this work focuses on the analysis and mitigation of structural bias for both real and synthetic graphs. Specifically, we first theoretically analyze the sources of structural bias that result in disparity for the predictions of dyadic relations. To alleviate the identified bias factors, we design a novel fairness regularizer that offers a versatile use. Faced with the bias amplification in graph generation models that is brought to light in this work, we further propose a fair graph generation framework, FairWire, by leveraging our fair regularizer design in a generative model. Experimental results on real-world networks validate that the proposed tools herein deliver effective structural bias mitigation for both real and synthetic graphs.
Fairness-aware Optimal Graph Filter Design
Oct 22, 2023Graphs are mathematical tools that can be used to represent complex real-world interconnected systems, such as financial markets and social networks. Hence, machine learning (ML) over graphs has attracted significant attention recently. However, it has been demonstrated that ML over graphs amplifies the already existing bias towards certain under-represented groups in various decision-making problems due to the information aggregation over biased graph structures. Faced with this challenge, here we take a fresh look at the problem of bias mitigation in graph-based learning by borrowing insights from graph signal processing. Our idea is to introduce predesigned graph filters within an ML pipeline to reduce a novel unsupervised bias measure, namely the correlation between sensitive attributes and the underlying graph connectivity. We show that the optimal design of said filters can be cast as a convex problem in the graph spectral domain. We also formulate a linear programming (LP) problem informed by a theoretical bias analysis, which attains a closed-form solution and leads to a more efficient fairness-aware graph filter. Finally, for a design whose degrees of freedom are independent of the input graph size, we minimize the bias metric over the family of polynomial graph convolutional filters. Our optimal filter designs offer complementary strengths to explore favorable fairness-utility-complexity tradeoffs. For performance evaluation, we conduct extensive and reproducible node classification experiments over real-world networks. Our results show that the proposed framework leads to better fairness measures together with similar utility compared to state-of-the-art fairness-aware baselines.
FairGAT: Fairness-aware Graph Attention Networks
Mar 26, 2023Graphs can facilitate modeling various complex systems such as gene networks and power grids, as well as analyzing the underlying relations within them. Learning over graphs has recently attracted increasing attention, particularly graph neural network-based (GNN) solutions, among which graph attention networks (GATs) have become one of the most widely utilized neural network structures for graph-based tasks. Although it is shown that the use of graph structures in learning results in the amplification of algorithmic bias, the influence of the attention design in GATs on algorithmic bias has not been investigated. Motivated by this, the present study first carries out a theoretical analysis in order to demonstrate the sources of algorithmic bias in GAT-based learning for node classification. Then, a novel algorithm, FairGAT, that leverages a fairness-aware attention design is developed based on the theoretical findings. Experimental results on real-world networks demonstrate that FairGAT improves group fairness measures while also providing comparable utility to the fairness-aware baselines for node classification and link prediction.
Fairness-Aware Graph Filter Design
Mar 20, 2023


Graphs are mathematical tools that can be used to represent complex real-world systems, such as financial markets and social networks. Hence, machine learning (ML) over graphs has attracted significant attention recently. However, it has been demonstrated that ML over graphs amplifies the already existing bias towards certain under-represented groups in various decision-making problems due to the information aggregation over biased graph structures. Faced with this challenge, in this paper, we design a fair graph filter that can be employed in a versatile manner for graph-based learning tasks. The design of the proposed filter is based on a bias analysis and its optimality in mitigating bias compared to its fairness-agnostic counterpart is established. Experiments on real-world networks for node classification demonstrate the efficacy of the proposed filter design in mitigating bias, while attaining similar utility and better stability compared to baseline algorithms.
FairNorm: Fair and Fast Graph Neural Network Training
May 20, 2022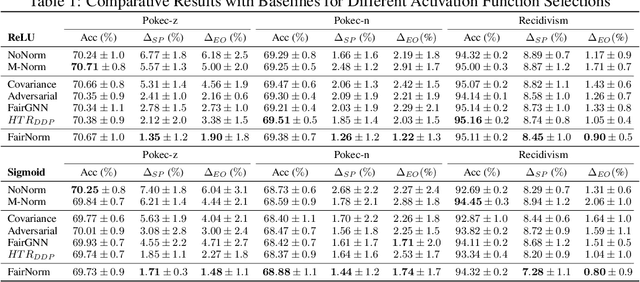
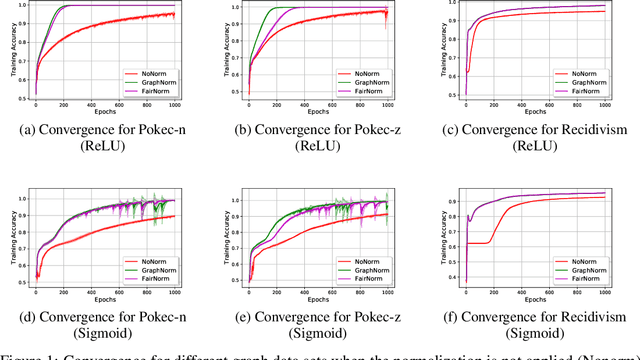
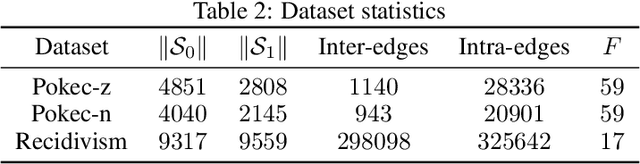
Graph neural networks (GNNs) have been demonstrated to achieve state-of-the-art for a number of graph-based learning tasks, which leads to a rise in their employment in various domains. However, it has been shown that GNNs may inherit and even amplify bias within training data, which leads to unfair results towards certain sensitive groups. Meanwhile, training of GNNs introduces additional challenges, such as slow convergence and possible instability. Faced with these limitations, this work proposes FairNorm, a unified normalization framework that reduces the bias in GNN-based learning while also providing provably faster convergence. Specifically, FairNorm employs fairness-aware normalization operators over different sensitive groups with learnable parameters to reduce the bias in GNNs. The design of FairNorm is built upon analyses that illuminate the sources of bias in graph-based learning. Experiments on node classification over real-world networks demonstrate the efficiency of the proposed scheme in improving fairness in terms of statistical parity and equal opportunity compared to fairness-aware baselines. In addition, it is empirically shown that the proposed framework leads to faster convergence compared to the naive baseline where no normalization is employed.
Fair Node Representation Learning via Adaptive Data Augmentation
Jan 21, 2022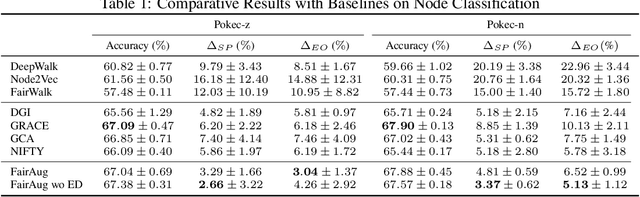
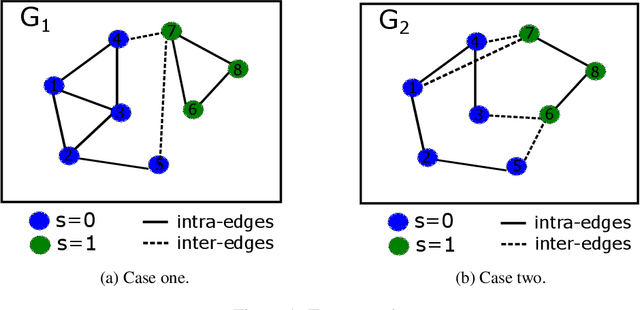
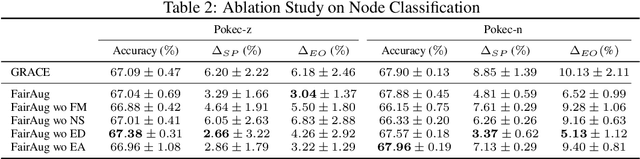
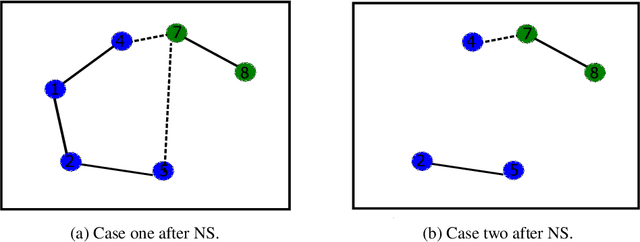
Node representation learning has demonstrated its efficacy for various applications on graphs, which leads to increasing attention towards the area. However, fairness is a largely under-explored territory within the field, which may lead to biased results towards underrepresented groups in ensuing tasks. To this end, this work theoretically explains the sources of bias in node representations obtained via Graph Neural Networks (GNNs). Our analysis reveals that both nodal features and graph structure lead to bias in the obtained representations. Building upon the analysis, fairness-aware data augmentation frameworks on nodal features and graph structure are developed to reduce the intrinsic bias. Our analysis and proposed schemes can be readily employed to enhance the fairness of various GNN-based learning mechanisms. Extensive experiments on node classification and link prediction are carried out over real networks in the context of graph contrastive learning. Comparison with multiple benchmarks demonstrates that the proposed augmentation strategies can improve fairness in terms of statistical parity and equal opportunity, while providing comparable utility to state-of-the-art contrastive methods.