 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Attacker Needed: Unintentional Cross-User Contamination in Shared-State LLM Agents
Apr 01, 2026LLM-based agents increasingly operate across repeated sessions, maintaining task states to ensure continuity. In many deployments, a single agent serves multiple users within a team or organization, reusing a shared knowledge layer across user identities. This shared persistence expands the failure surface: information that is locally valid for one user can silently degrade another user's outcome when the agent reapplies it without regard for scope. We refer to this failure mode as unintentional cross-user contamination (UCC). Unlike adversarial memory poisoning, UCC requires no attacker; it arises from benign interactions whose scope-bound artifacts persist and are later misapplied. We formalize UCC through a controlled evaluation protocol, introduce a taxonomy of three contamination types, and evaluate the problem in two shared-state mechanisms. Under raw shared state, benign interactions alone produce contamination rates of 57--71%. A write-time sanitization is effective when shared state is conversational, but leaves substantial residual risk when shared state includes executable artifacts, with contamination often manifesting as silent wrong answers. These results indicate that shared-state agents need artifact-level defenses beyond text-level sanitization to prevent silent cross-user failures.
FairZK: A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 19, 2025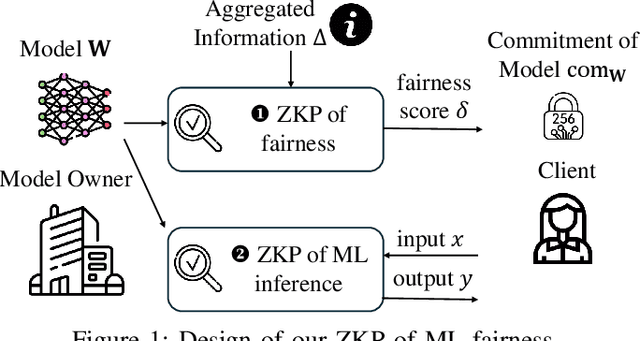

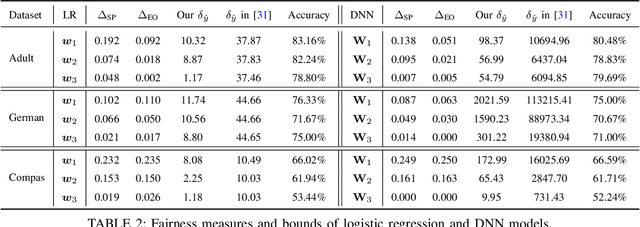
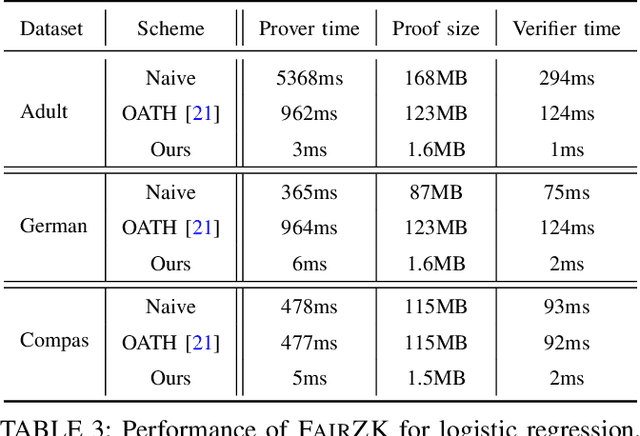
With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.
A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 12, 2025With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.
A Practical Memory Injection Attack against LLM Agents
Mar 05, 2025



Agents based on large language models (LLMs) have demonstrated strong capabilities in a wide range of complex, real-world applications. However, LLM agents with a compromised memory bank may easily produce harmful outputs when the past records retrieved for demonstration are malicious. In this paper, we propose a novel Memory INJection Attack, MINJA, that enables the injection of malicious records into the memory bank by only interacting with the agent via queries and output observations. These malicious records are designed to elicit a sequence of malicious reasoning steps leading to undesirable agent actions when executing the victim user's query. Specifically, we introduce a sequence of bridging steps to link the victim query to the malicious reasoning steps. During the injection of the malicious record, we propose an indication prompt to guide the agent to autonomously generate our designed bridging steps. We also propose a progressive shortening strategy that gradually removes the indication prompt, such that the malicious record will be easily retrieved when processing the victim query comes after. Our extensive experiments across diverse agents demonstrate the effectiveness of MINJA in compromising agent memory. With minimal requirements for execution, MINJA enables any user to influence agent memory, highlighting practical risks of LLM agents.