 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Reward-SQL: Execution-Free Reinforcement Learning for Text-to-SQL via Graph Matching and Stepwise Reward
May 18, 2025Reinforcement learning (RL) has been widely adopted to enhance the performance of large language models (LLMs) on Text-to-SQL tasks. However, existing methods often rely on execution-based or LLM-based Bradley-Terry reward models. The former suffers from high execution latency caused by repeated database calls, whereas the latter imposes substantial GPU memory overhead, both of which significantly hinder the efficiency and scalability of RL pipelines. To this end, we propose a novel Text-to-SQL RL fine-tuning framework named Graph-Reward-SQL, which employs the GMNScore outcome reward model. We leverage SQL graph representations to provide accurate reward signals while significantly reducing inference time and GPU memory usage. Building on this foundation, we further introduce StepRTM, a stepwise reward model that provides intermediate supervision over Common Table Expression (CTE) subqueries. This encourages both functional correctness and structural clarity of SQL. Extensive comparative and ablation experiments on standard benchmarks, including Spider and BIRD, demonstrate that our method consistently outperforms existing reward models.
DSTC: Direct Preference Learning with Only Self-Generated Tests and Code to Improve Code LMs
Nov 20, 2024



Direct preference learning offers a promising and computation-efficient beyond supervised fine-tuning (SFT) for improving code generation in coding large language models (LMs). However, the scarcity of reliable preference data is a bottleneck for the performance of direct preference learning to improve the coding accuracy of code LMs. In this paper, we introduce \underline{\textbf{D}}irect Preference Learning with Only \underline{\textbf{S}}elf-Generated \underline{\textbf{T}}ests and \underline{\textbf{C}}ode (DSTC), a framework that leverages only self-generated code snippets and tests to construct reliable preference pairs such that direct preference learning can improve LM coding accuracy without external annotations. DSTC combines a minimax selection process and test-code concatenation to improve preference pair quality, reducing the influence of incorrect self-generated tests and enhancing model performance without the need for costly reward models. When applied with direct preference learning methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO), DSTC yields stable improvements in coding accuracy (pass@1 score) across diverse coding benchmarks, including HumanEval, MBPP, and BigCodeBench, demonstrating both its effectiveness and scalability for models of various sizes. This approach autonomously enhances code generation accuracy across LLMs of varying sizes, reducing reliance on expensive annotated coding datasets.
Reward-Augmented Data Enhances Direct Preference Alignment of LLMs
Oct 10, 2024



Preference alignment in Large Language Models (LLMs) has significantly improved their ability to adhere to human instructions and intentions. However, existing direct alignment algorithms primarily focus on relative preferences and often overlook the qualitative aspects of responses. Striving to maximize the implicit reward gap between the chosen and the slightly inferior rejected responses can cause overfitting and unnecessary unlearning of the high-quality rejected responses. The unawareness of the reward scores also drives the LLM to indiscriminately favor the low-quality chosen responses and fail to generalize to responses with the highest rewards, which are sparse in data. To overcome these shortcomings, our study introduces reward-conditioned LLM policies that discern and learn from the entire spectrum of response quality within the dataset, helping extrapolate to more optimal regions. We propose an effective yet simple data relabeling method that conditions the preference pairs on quality scores to construct a reward-augmented dataset. This dataset is easily integrated with existing direct alignment algorithms and is applicable to any preference dataset. The experimental results across instruction-following benchmarks including AlpacaEval, MT-Bench, and Arena-Hard-Auto demonstrate that our approach consistently boosts the performance of DPO by a considerable margin across diverse models. Additionally, our method improves the average accuracy on various academic benchmarks. When applying our method to on-policy data, the resulting DPO model achieves SOTA results on AlpacaEval. Through ablation studies, we demonstrate that our method not only maximizes the utility of preference data but also mitigates the issue of unlearning, demonstrating its broad effectiveness beyond mere dataset expansion. Our code is available at https://github.com/shenao-zhang/reward-augmented-preference.
Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer
May 26, 2024



Aligning generative models with human preference via RLHF typically suffers from overoptimization, where an imperfectly learned reward model can misguide the generative model to output undesired responses. We investigate this problem in a principled manner by identifying the source of the misalignment as a form of distributional shift and uncertainty in learning human preferences. To mitigate overoptimization, we first propose a theoretical algorithm that chooses the best policy for an adversarially chosen reward model; one that simultaneously minimizes the maximum likelihood estimation of the loss and a reward penalty term. Here, the reward penalty term is introduced to prevent the policy from choosing actions with spurious high proxy rewards, resulting in provable sample efficiency of the algorithm under a partial coverage style condition. Moving from theory to practice, the proposed algorithm further enjoys an equivalent but surprisingly easy-to-implement reformulation. Using the equivalence between reward models and the corresponding optimal policy, the algorithm features a simple objective that combines: (i) a preference optimization loss that directly aligns the policy with human preference, and (ii) a supervised learning loss that explicitly imitates the policy with a (suitable) baseline distribution. In the context of aligning large language models (LLM), this objective fuses the direct preference optimization (DPO) loss with the supervised fune-tuning (SFT) loss to help mitigate the overoptimization towards undesired responses, for which we name the algorithm Regularized Preference Optimization (RPO). Experiments of aligning LLMs demonstrate the improved performance of RPO compared with DPO baselines. Our work sheds light on the interplay between preference optimization and SFT in tuning LLMs with both theoretical guarantees and empirical evidence.
$\mathbf{}$-Puzzle: A Cost-Efficient Testbed for Benchmarking Reinforcement Learning Algorithms in Generative Language Model
Mar 11, 2024



Recent advances in reinforcement learning (RL) algorithms aim to enhance the performance of language models at scale. Yet, there is a noticeable absence of a cost-effective and standardized testbed tailored to evaluating and comparing these algorithms. To bridge this gap, we present a generalized version of the 24-Puzzle: the $(N,K)$-Puzzle, which challenges language models to reach a target value $K$ with $N$ integers. We evaluate the effectiveness of established RL algorithms such as Proximal Policy Optimization (PPO), alongside novel approaches like Identity Policy Optimization (IPO) and Direct Policy Optimization (DPO).
How Can LLM Guide RL? A Value-Based Approach
Feb 25, 2024



Reinforcement learning (RL) has become the de facto standard practice for sequential decision-making problems by improving future acting policies with feedback. However, RL algorithms may require extensive trial-and-error interactions to collect useful feedback for improvement. On the other hand, recent developments in large language models (LLMs) have showcased impressive capabilities in language understanding and generation, yet they fall short in exploration and self-improvement capabilities for planning tasks, lacking the ability to autonomously refine their responses based on feedback. Therefore, in this paper, we study how the policy prior provided by the LLM can enhance the sample efficiency of RL algorithms. Specifically, we develop an algorithm named LINVIT that incorporates LLM guidance as a regularization factor in value-based RL, leading to significant reductions in the amount of data needed for learning, particularly when the difference between the ideal policy and the LLM-informed policy is small, which suggests that the initial policy is close to optimal, reducing the need for further exploration. Additionally, we present a practical algorithm SLINVIT that simplifies the construction of the value function and employs subgoals to reduce the search complexity. Our experiments across three interactive environments ALFWorld, InterCode, and BlocksWorld demonstrate that our method achieves state-of-the-art success rates and also surpasses previous RL and LLM approaches in terms of sample efficiency. Our code is available at https://github.com/agentification/Language-Integrated-VI.
Reason out Your Layout: Evoking the Layout Master from Large Language Models for Text-to-Image Synthesis
Nov 28, 2023



Recent advancements in text-to-image (T2I) generative models have shown remarkable capabilities in producing diverse and imaginative visuals based on text prompts. Despite the advancement, these diffusion models sometimes struggle to translate the semantic content from the text into images entirely. While conditioning on the layout has shown to be effective in improving the compositional ability of T2I diffusion models, they typically require manual layout input. In this work, we introduce a novel approach to improving T2I diffusion models using Large Language Models (LLMs) as layout generators. Our method leverages the Chain-of-Thought prompting of LLMs to interpret text and generate spatially reasonable object layouts. The generated layout is then used to enhance the generated images' composition and spatial accuracy. Moreover, we propose an efficient adapter based on a cross-attention mechanism, which explicitly integrates the layout information into the stable diffusion models. Our experiments demonstrate significant improvements in image quality and layout accuracy, showcasing the potential of LLMs in augmenting generative image models.
Let Models Speak Ciphers: Multiagent Debate through Embeddings
Oct 10, 2023



Discussion and debate among Large Language Models (LLMs) have gained considerable attention due to their potential to enhance the reasoning ability of LLMs. Although natural language is an obvious choice for communication due to LLM's language understanding capability, the token sampling step needed when generating natural language poses a potential risk of information loss, as it uses only one token to represent the model's belief across the entire vocabulary. In this paper, we introduce a communication regime named CIPHER (Communicative Inter-Model Protocol Through Embedding Representation) to address this issue. Specifically, we remove the token sampling step from LLMs and let them communicate their beliefs across the vocabulary through the expectation of the raw transformer output embeddings. Remarkably, by deviating from natural language, CIPHER offers an advantage of encoding a broader spectrum of information without any modification to the model weights. While the state-of-the-art LLM debate methods using natural language outperforms traditional inference by a margin of 1.5-8%, our experiment results show that CIPHER debate further extends this lead by 1-3.5% across five reasoning tasks and multiple open-source LLMs of varying sizes. This showcases the superiority and robustness of embeddings as an alternative "language" for communication among LLMs.
Detecting Nonlinear Causality in Multivariate Time Series with Sparse Additive Models
Apr 26, 2018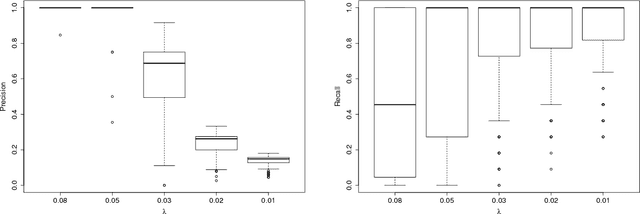
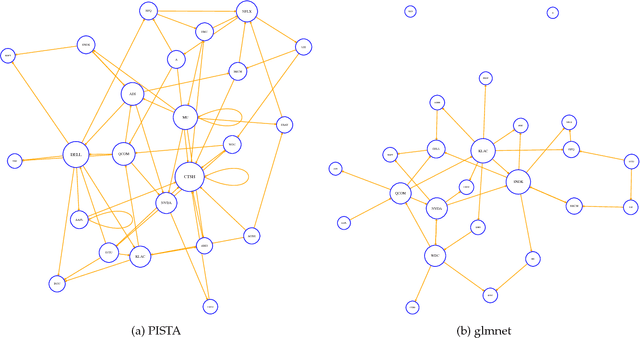
We propose a nonparametric method for detecting nonlinear causal relationship within a set of multidimensional discrete time series, by using sparse additive models (SpAMs). We show that, when the input to the SpAM is a $\beta$-mixing time series, the model can be fitted by first approximating each unknown function with a linear combination of a set of B-spline bases, and then solving a group-lasso-type optimization problem with nonconvex regularization. Theoretically, we characterize the oracle statistical properties of the proposed sparse estimator in function estimation and model selection. Numerically, we propose an efficient pathwise iterative shrinkage thresholding algorithm (PISTA), which tames the nonconvexity and guarantees linear convergence towards the desired sparse estimator with high probability.
Nonparametric Hawkes Processes: Online Estimation and Generalization Bounds
Jan 25, 2018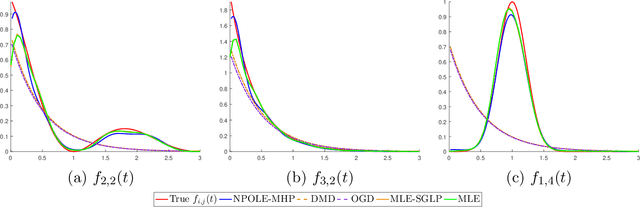
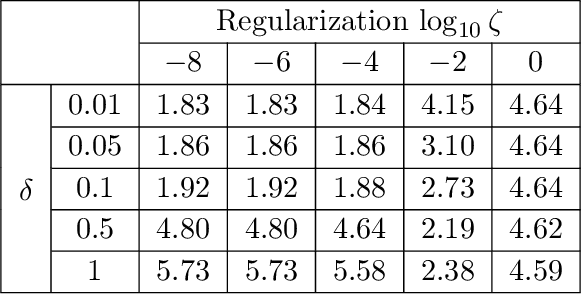
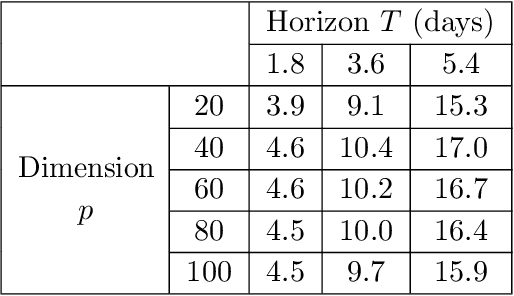
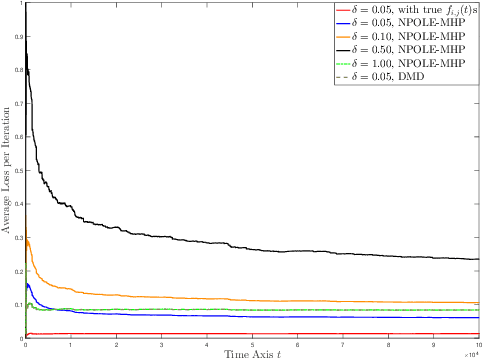
In this paper, we design a nonparametric online algorithm for estimating the triggering functions of multivariate Hawkes processes. Unlike parametric estimation, where evolutionary dynamics can be exploited for fast computation of the gradient, and unlike typical function learning, where representer theorem is readily applicable upon proper regularization of the objective function, nonparametric estimation faces the challenges of (i) inefficient evaluation of the gradient, (ii) lack of representer theorem, and (iii) computationally expensive projection necessary to guarantee positivity of the triggering functions. In this paper, we offer solutions to the above challenges, and design an online estimation algorithm named NPOLE-MHP that outputs estimations with a $\mathcal{O}(1/T)$ regret, and a $\mathcal{O}(1/T)$ stability. Furthermore, we design an algorithm, NPOLE-MMHP, for estimation of multivariate marked Hawkes processes. We test the performance of NPOLE-MHP on various synthetic and real datasets, and demonstrate, under different evaluation metrics, that NPOLE-MHP performs as good as the optimal maximum likelihood estimation (MLE), while having a run time as little as parametric online algorithms.