 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds on the Worst-Case Complexity of Efficient Global Optimization
Sep 20, 2022
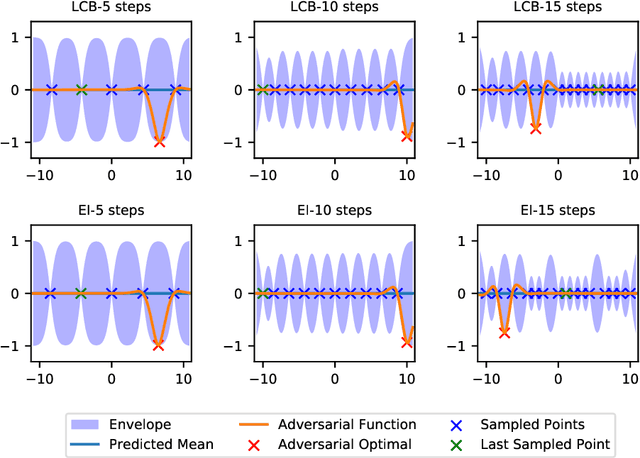
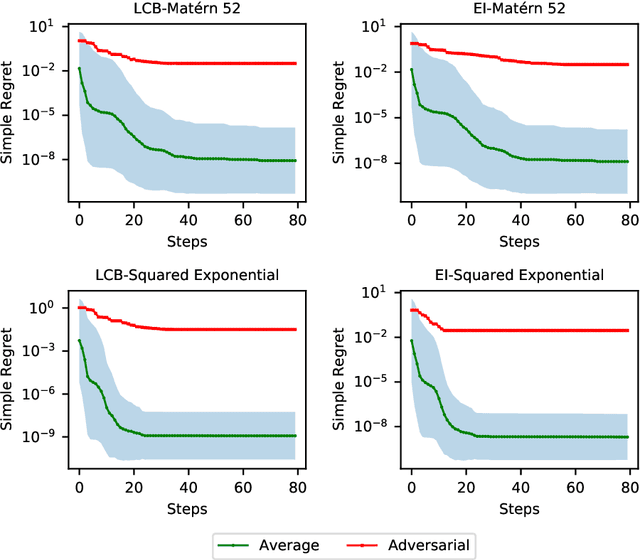
Efficient global optimization is a widely used method for optimizing expensive black-box functions such as tuning hyperparameter, and designing new material, etc. Despite its popularity, less attention has been paid to analyzing the inherent hardness of the problem although, given its extensive use, it is important to understand the fundamental limits of efficient global optimization algorithms. In this paper, we study the worst-case complexity of the efficient global optimization problem and, in contrast to existing kernel-specific results, we derive a unified lower bound for the complexity of efficient global optimization in terms of the metric entropy of a ball in its corresponding reproducing kernel Hilbert space~(RKHS). Specifically, we show that if there exists a deterministic algorithm that achieves suboptimality gap smaller than $\epsilon$ for any function $f\in S$ in $T$ function evaluations, it is necessary that $T$ is at least $\Omega\left(\frac{\log\mathcal{N}(S(\mathcal{X}), 4\epsilon,\|\cdot\|_\infty)}{\log(\frac{R}{\epsilon})}\right)$, where $\mathcal{N}(\cdot,\cdot,\cdot)$ is the covering number, $S$ is the ball centered at $0$ with radius $R$ in the RKHS and $S(\mathcal{X})$ is the restriction of $S$ over the feasible set $\mathcal{X}$. Moreover, we show that this lower bound nearly matches the upper bound attained by non-adaptive search algorithms for the commonly used squared exponential kernel and the Mat\'ern kernel with a large smoothness parameter $\nu$, up to a replacement of $d/2$ by $d$ and a logarithmic term $\log\frac{R}{\epsilon}$. That is to say, our lower bound is nearly optimal for these kernels.
Geometry Aligned Variational Transformer for Image-conditioned Layout Generation
Sep 02, 2022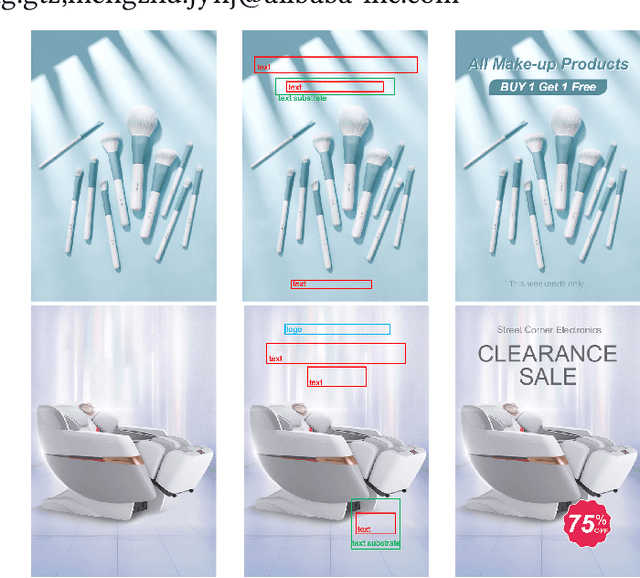
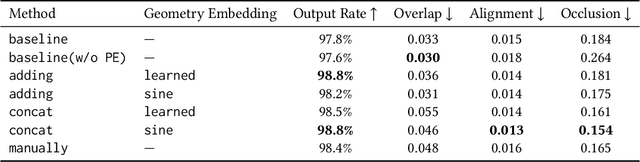
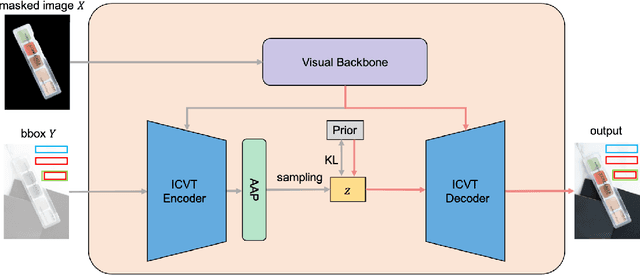

Layout generation is a novel task in computer vision, which combines the challenges in both object localization and aesthetic appraisal, widely used in advertisements, posters, and slides design. An accurate and pleasant layout should consider both the intra-domain relationship within layout elements and the inter-domain relationship between layout elements and the image. However, most previous methods simply focus on image-content-agnostic layout generation, without leveraging the complex visual information from the image. To this end, we explore a novel paradigm entitled image-conditioned layout generation, which aims to add text overlays to an image in a semantically coherent manner. Specifically, we propose an Image-Conditioned Variational Transformer (ICVT) that autoregressively generates various layouts in an image. First, self-attention mechanism is adopted to model the contextual relationship within layout elements, while cross-attention mechanism is used to fuse the visual information of conditional images. Subsequently, we take them as building blocks of conditional variational autoencoder (CVAE), which demonstrates appealing diversity. Second, in order to alleviate the gap between layout elements domain and visual domain, we design a Geometry Alignment module, in which the geometric information of the image is aligned with the layout representation. In addition, we construct a large-scale advertisement poster layout designing dataset with delicate layout and saliency map annotations. Experimental results show that our model can adaptively generate layouts in the non-intrusive area of the image, resulting in a harmonious layout design.
Joint Optimization of Ranking and Calibration with Contextualized Hybrid Model
Aug 12, 2022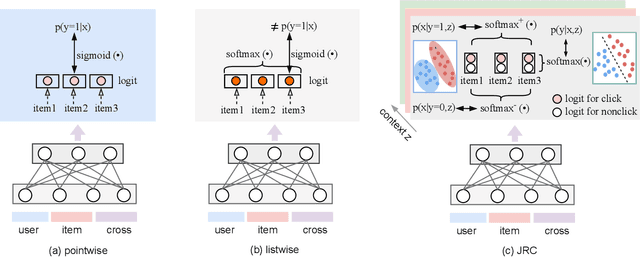
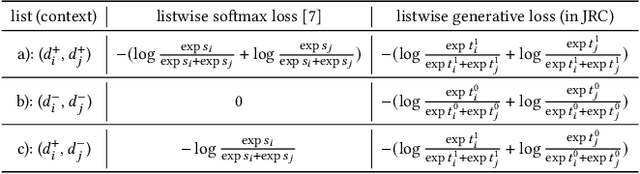

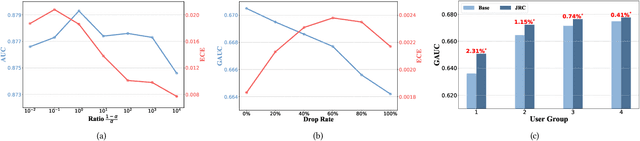
Despite the development of ranking optimization techniques, the pointwise model remains the dominating approach for click-through rate (CTR) prediction. It can be attributed to the calibration ability of the pointwise model since the prediction can be viewed as the click probability. In practice, a CTR prediction model is also commonly assessed with the ranking ability, for which prediction models based on ranking losses (e.g., pairwise or listwise loss) usually achieve better performances than the pointwise loss. Previous studies have experimented with a direct combination of the two losses to obtain the benefit from both losses and observed an improved performance. However, previous studies break the meaning of output logit as the click-through rate, which may lead to sub-optimal solutions. To address this issue, we propose an approach that can Jointly optimize the Ranking and Calibration abilities (JRC for short). JRC improves the ranking ability by contrasting the logit value for the sample with different labels and constrains the predicted probability to be a function of the logit subtraction. We further show that JRC consolidates the interpretation of logits, where the logits model the joint distribution. With such an interpretation, we prove that JRC approximately optimizes the contextualized hybrid discriminative-generative objective. Experiments on public and industrial datasets and online A/B testing show that our approach improves both ranking and calibration abilities. Since May 2022, JRC has been deployed on the display advertising platform of Alibaba and has obtained significant performance improvements.
Attract me to Buy: Advertisement Copywriting Generation with Multimodal Multi-structured Information
May 07, 2022

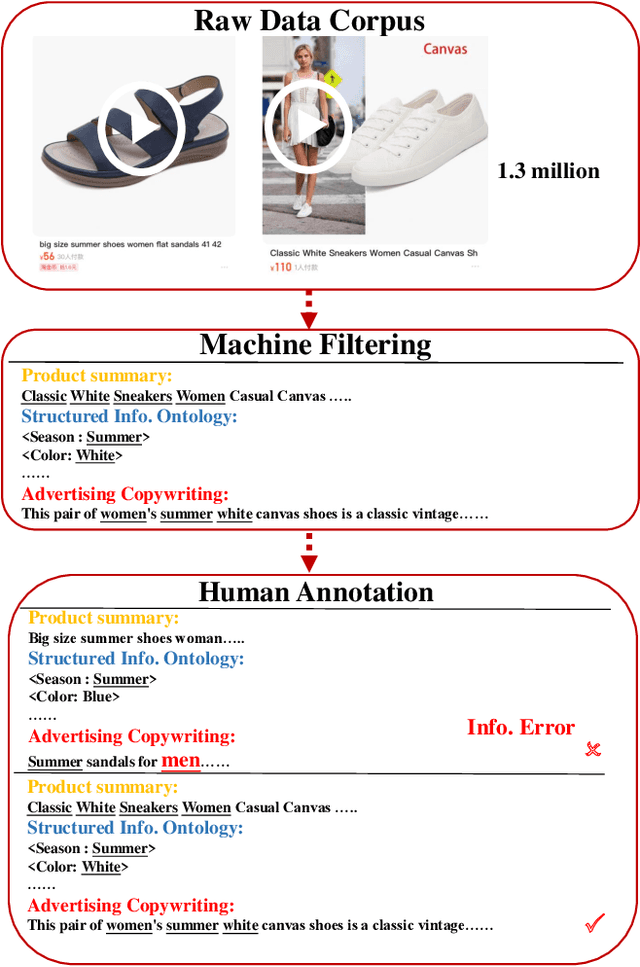
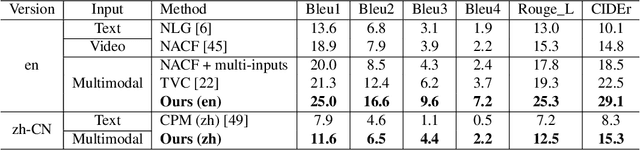
Recently, online shopping has gradually become a common way of shopping for people all over the world. Wonderful merchandise advertisements often attract more people to buy. These advertisements properly integrate multimodal multi-structured information of commodities, such as visual spatial information and fine-grained structure information. However, traditional multimodal text generation focuses on the conventional description of what existed and happened, which does not match the requirement of advertisement copywriting in the real world. Because advertisement copywriting has a vivid language style and higher requirements of faithfulness. Unfortunately, there is a lack of reusable evaluation frameworks and a scarcity of datasets. Therefore, we present a dataset, E-MMAD (e-commercial multimodal multi-structured advertisement copywriting), which requires, and supports much more detailed information in text generation. Noticeably, it is one of the largest video captioning datasets in this field. Accordingly, we propose a baseline method and faithfulness evaluation metric on the strength of structured information reasoning to solve the demand in reality on this dataset. It surpasses the previous methods by a large margin on all metrics. The dataset and method are coming soon on \url{https://e-mmad.github.io/e-mmad.net/index.html}.
Dual-Level Decoupled Transformer for Video Captioning
May 06, 2022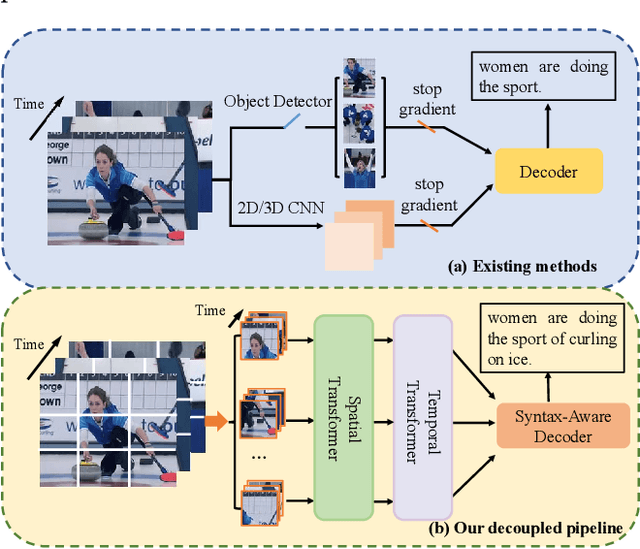
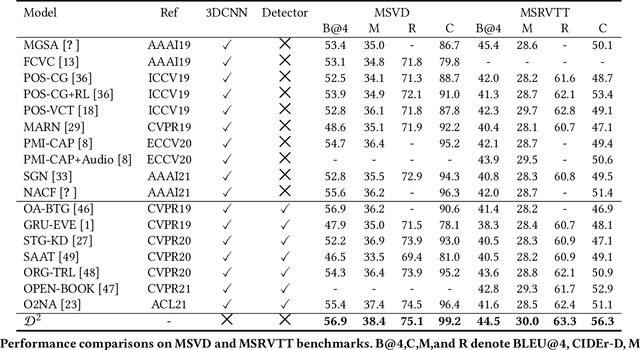
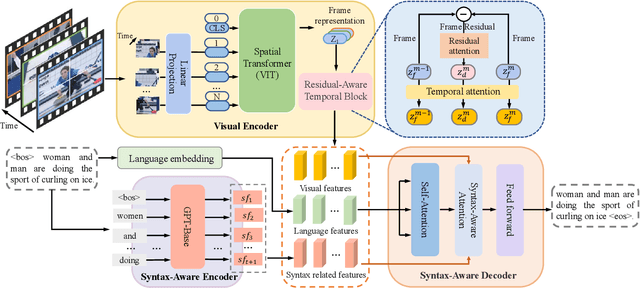
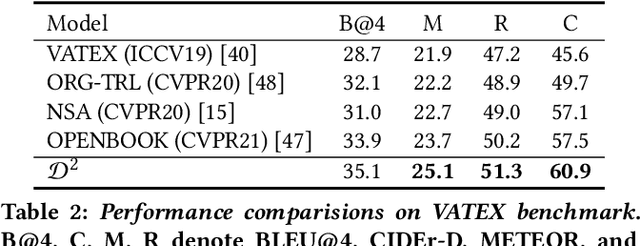
Video captioning aims to understand the spatio-temporal semantic concept of the video and generate descriptive sentences. The de-facto approach to this task dictates a text generator to learn from \textit{offline-extracted} motion or appearance features from \textit{pre-trained} vision models. However, these methods may suffer from the so-called \textbf{\textit{"couple"}} drawbacks on both \textit{video spatio-temporal representation} and \textit{sentence generation}. For the former, \textbf{\textit{"couple"}} means learning spatio-temporal representation in a single model(3DCNN), resulting the problems named \emph{disconnection in task/pre-train domain} and \emph{hard for end-to-end training}. As for the latter, \textbf{\textit{"couple"}} means treating the generation of visual semantic and syntax-related words equally. To this end, we present $\mathcal{D}^{2}$ - a dual-level decoupled transformer pipeline to solve the above drawbacks: \emph{(i)} for video spatio-temporal representation, we decouple the process of it into "first-spatial-then-temporal" paradigm, releasing the potential of using dedicated model(\textit{e.g.} image-text pre-training) to connect the pre-training and downstream tasks, and makes the entire model end-to-end trainable. \emph{(ii)} for sentence generation, we propose \emph{Syntax-Aware Decoder} to dynamically measure the contribution of visual semantic and syntax-related words. Extensive experiments on three widely-used benchmarks (MSVD, MSR-VTT and VATEX) have shown great potential of the proposed $\mathcal{D}^{2}$ and surpassed the previous methods by a large margin in the task of video captioning.
Composition-aware Graphic Layout GAN for Visual-textual Presentation Designs
Apr 30, 2022

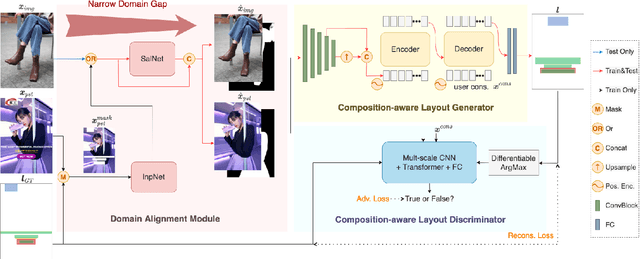

In this paper, we study the graphic layout generation problem of producing high-quality visual-textual presentation designs for given images. We note that image compositions, which contain not only global semantics but also spatial information, would largely affect layout results. Hence, we propose a deep generative model, dubbed as composition-aware graphic layout GAN (CGL-GAN), to synthesize layouts based on the global and spatial visual contents of input images. To obtain training images from images that already contain manually designed graphic layout data, previous work suggests masking design elements (e.g., texts and embellishments) as model inputs, which inevitably leaves hint of the ground truth. We study the misalignment between the training inputs (with hint masks) and test inputs (without masks), and design a novel domain alignment module (DAM) to narrow this gap. For training, we built a large-scale layout dataset which consists of 60,548 advertising posters with annotated layout information. To evaluate the generated layouts, we propose three novel metrics according to aesthetic intuitions. Through both quantitative and qualitative evaluations, we demonstrate that the proposed model can synthesize high-quality graphic layouts according to image compositions.
CapOnImage: Context-driven Dense-Captioning on Image
Apr 27, 2022
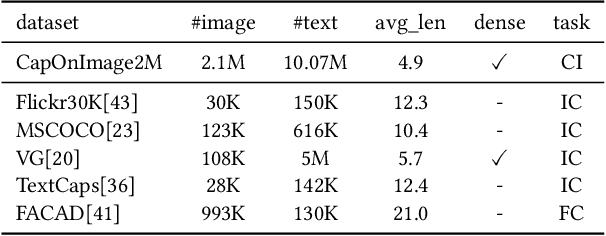
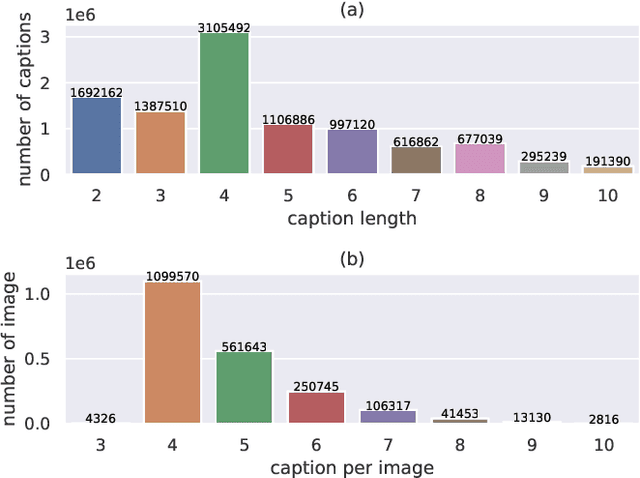
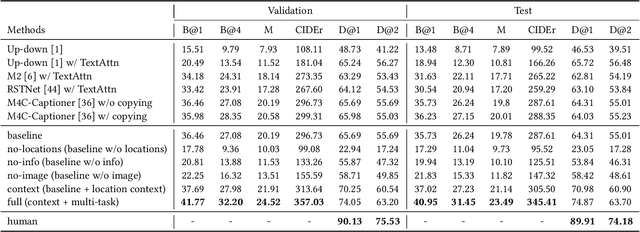
Existing image captioning systems are dedicated to generating narrative captions for images, which are spatially detached from the image in presentation. However, texts can also be used as decorations on the image to highlight the key points and increase the attractiveness of images. In this work, we introduce a new task called captioning on image (CapOnImage), which aims to generate dense captions at different locations of the image based on contextual information. To fully exploit the surrounding visual context to generate the most suitable caption for each location, we propose a multi-modal pre-training model with multi-level pre-training tasks that progressively learn the correspondence between texts and image locations from easy to difficult. Since the model may generate redundant captions for nearby locations, we further enhance the location embedding with neighbor locations as context. For this new task, we also introduce a large-scale benchmark called CapOnImage2M, which contains 2.1 million product images, each with an average of 4.8 spatially localized captions. Compared with other image captioning model variants, our model achieves the best results in both captioning accuracy and diversity aspects. We will make code and datasets public to facilitate future research.
Self-Supervised Text Erasing with Controllable Image Synthesis
Apr 27, 2022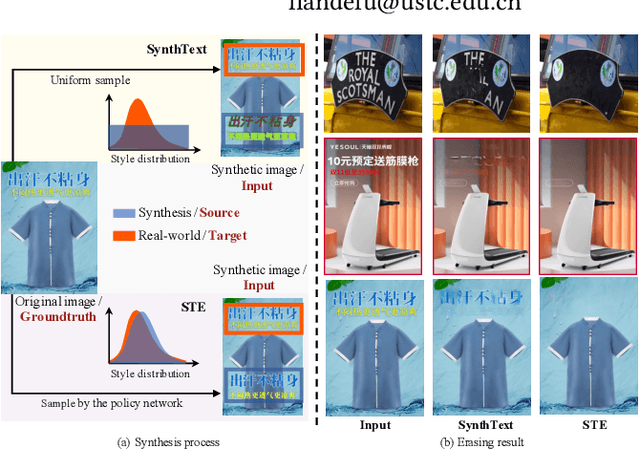
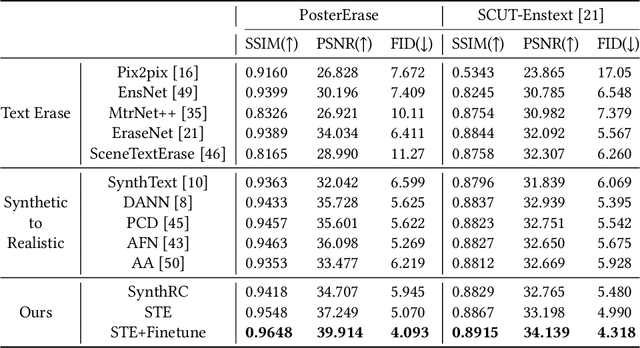
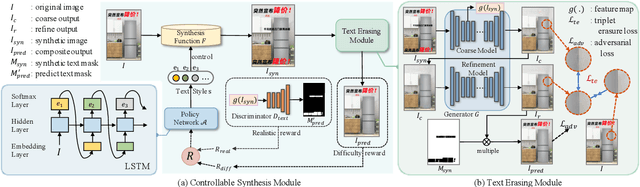
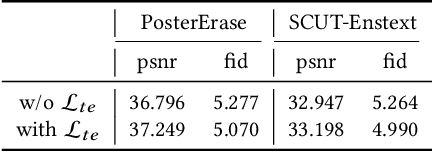
Recent efforts on scene text erasing have shown promising results. However, existing methods require rich yet costly label annotations to obtain robust models, which limits the use for practical applications. To this end, we study an unsupervised scenario by proposing a novel Self-supervised Text Erasing (STE) framework that jointly learns to synthesize training images with erasure ground-truth and accurately erase texts in the real world. We first design a style-aware image synthesis function to generate synthetic images with diverse styled texts based on two synthetic mechanisms. To bridge the text style gap between the synthetic and real-world data, a policy network is constructed to control the synthetic mechanisms by picking style parameters with the guidance of two specifically designed rewards. The synthetic training images with erasure ground-truth are then fed to train a coarse-to-fine erasing network. To produce better erasing outputs, a triplet erasure loss is designed to enforce the refinement stage to recover background textures. Moreover, we provide a new dataset (called PosterErase), which contains 60K high-resolution posters with texts and is more challenging for the text erasing task. The proposed method has been extensively evaluated with both PosterErase and the widely-used SCUT-Enstext dataset. Notably, on PosterErase, our unsupervised method achieves 5.07 in terms of FID, with a relative performance of 20.9% over existing supervised baselines.
Estimation of Reliable Proposal Quality for Temporal Action Detection
Apr 25, 2022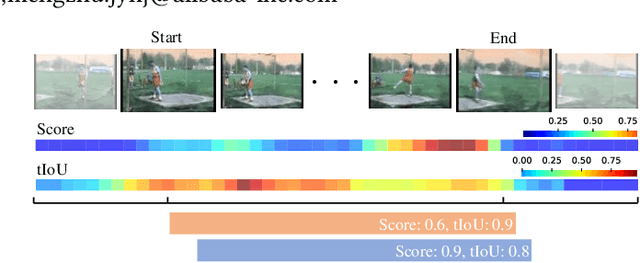
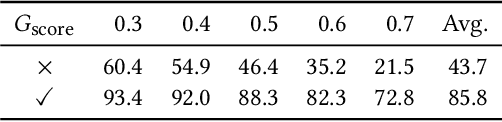
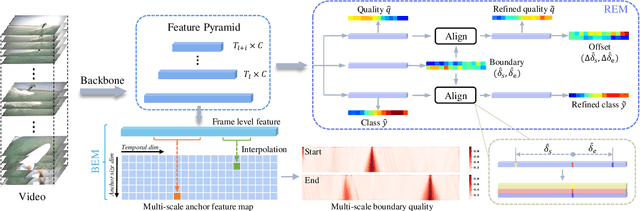
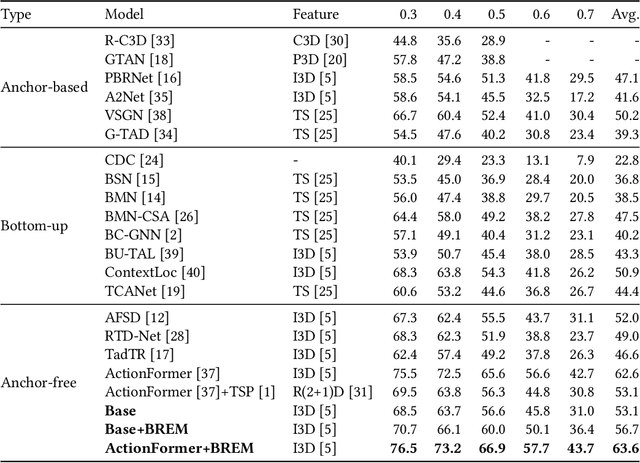
Temporal action detection (TAD) aims to locate and recognize the actions in an untrimmed video. Anchor-free methods have made remarkable progress which mainly formulate TAD into two tasks: classification and localization using two separate branches. This paper reveals the temporal misalignment between the two tasks hindering further progress. To address this, we propose a new method that gives insights into moment and region perspectives simultaneously to align the two tasks by acquiring reliable proposal quality. For the moment perspective, Boundary Evaluate Module (BEM) is designed which focuses on local appearance and motion evolvement to estimate boundary quality and adopts a multi-scale manner to deal with varied action durations. For the region perspective, we introduce Region Evaluate Module (REM) which uses a new and efficient sampling method for proposal feature representation containing more contextual information compared with point feature to refine category score and proposal boundary. The proposed Boundary Evaluate Module and Region Evaluate Module (BREM) are generic, and they can be easily integrated with other anchor-free TAD methods to achieve superior performance. In our experiments, BREM is combined with two different frameworks and improves the performance on THUMOS14 by 3.6$\%$ and 1.0$\%$ respectively, reaching a new state-of-the-art (63.6$\%$ average $m$AP). Meanwhile, a competitive result of 36.2\% average $m$AP is achieved on ActivityNet-1.3 with the consistent improvement of BREM.
Structure-Aware Motion Transfer with Deformable Anchor Model
Apr 11, 2022
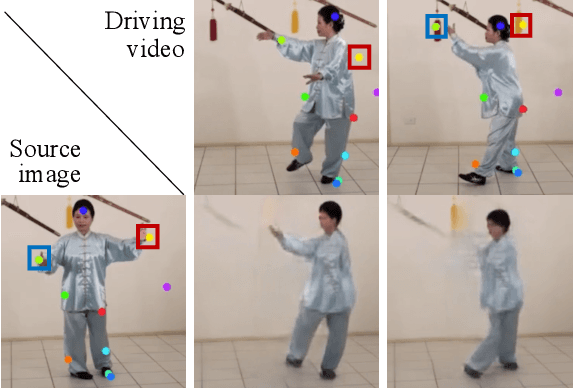

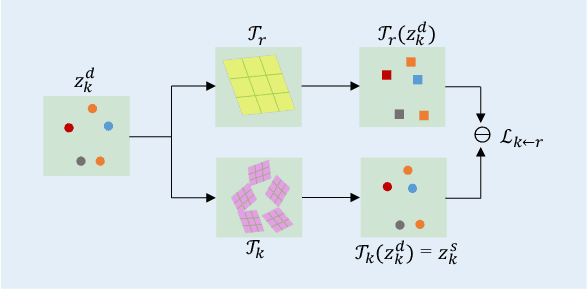
Given a source image and a driving video depicting the same object type, the motion transfer task aims to generate a video by learning the motion from the driving video while preserving the appearance from the source image. In this paper, we propose a novel structure-aware motion modeling approach, the deformable anchor model (DAM), which can automatically discover the motion structure of arbitrary objects without leveraging their prior structure information. Specifically, inspired by the known deformable part model (DPM), our DAM introduces two types of anchors or keypoints: i) a number of motion anchors that capture both appearance and motion information from the source image and driving video; ii) a latent root anchor, which is linked to the motion anchors to facilitate better learning of the representations of the object structure information. Moreover, DAM can be further extended to a hierarchical version through the introduction of additional latent anchors to model more complicated structures. By regularizing motion anchors with latent anchor(s), DAM enforces the correspondences between them to ensure the structural information is well captured and preserved. Moreover, DAM can be learned effectively in an unsupervised manner. We validate our proposed DAM for motion transfer on different benchmark datasets. Extensive experiments clearly demonstrate that DAM achieves superior performance relative to existing state-of-the-art methods.