 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Prompt Tuning in Vision-Language Model without Annotations
Mar 11, 2025



Prompt tuning of Vision-Language Models (VLMs) such as CLIP, has demonstrated the ability to rapidly adapt to various downstream tasks. However, recent studies indicate that tuned VLMs may suffer from the problem of spurious correlations, where the model relies on spurious features (e.g. background and gender) in the data. This may lead to the model having worse robustness in out-of-distribution data. Standard methods for eliminating spurious correlation typically require us to know the spurious attribute labels of each sample, which is hard in the real world. In this work, we explore improving the group robustness of prompt tuning in VLMs without relying on manual annotation of spurious features. We notice the zero - shot image recognition ability of VLMs and use this ability to identify spurious features, thus avoiding the cost of manual annotation. By leveraging pseudo-spurious attribute annotations, we further propose a method to automatically adjust the training weights of different groups. Extensive experiments show that our approach efficiently improves the worst-group accuracy on CelebA, Waterbirds, and MetaShift datasets, achieving the best robustness gap between the worst-group accuracy and the overall accuracy.
Debiasing Vison-Language Models with Text-Only Training
Oct 12, 2024



Pre-trained vision-language models (VLMs), such as CLIP, have exhibited remarkable performance across various downstream tasks by aligning text and images in a unified embedding space. However, due to the imbalanced distribution of pre-trained datasets, CLIP suffers from the bias problem in real-world applications. Existing debiasing methods struggle to obtain sufficient image samples for minority groups and incur high costs for group labeling. To address the limitations, we propose a Text-Only Debiasing framework called TOD, leveraging a text-as-image training paradigm to mitigate visual biases. Specifically, this approach repurposes the text encoder to function as an image encoder, thereby eliminating the need for image data. Simultaneously, it utilizes a large language model (LLM) to generate a balanced text dataset, which is then used for prompt tuning. However, we observed that the model overfits to the text modality because label names, serving as supervision signals, appear explicitly in the texts. To address this issue, we further introduce a Multi-Target Prediction (MTP) task that motivates the model to focus on complex contexts and distinguish between target and biased information. Extensive experiments on the Waterbirds and CelebA datasets show that our method significantly improves group robustness, achieving state-of-the-art results among image-free methods and even competitive performance compared to image-supervised methods. Furthermore, the proposed method can be adapted to challenging scenarios with multiple or unknown bias attributes, demonstrating its strong generalization and robustness.
Language-assisted Vision Model Debugger: A Sample-Free Approach to Finding Bugs
Dec 09, 2023Vision models with high overall accuracy often exhibit systematic errors in specific scenarios, posing potential serious safety concerns. Diagnosing bugs of vision models is gaining increased attention, however traditional diagnostic approaches require annotation efforts (\eg rich metadata accompanying each samples of CelebA). To address this issue,We propose a language-assisted diagnostic method that uses texts instead of images to diagnose bugs in vision models based on multi-modal models (\eg CLIP). Our approach connects the embedding space of CLIP with the buggy vision model to be diagnosed; meanwhile, utilizing a shared classifier and the cross-modal transferability of embedding space from CLIP, the text-branch of CLIP become a proxy model to find bugs in the buggy model. The proxy model can classify texts paired with images. During the diagnosis, a Large Language Model (LLM) is employed to obtain task-relevant corpora, and this corpora is used to extract keywords. Descriptions constructed with templates containing these keywords serve as input text to probe errors in the proxy model. Finally, we validate the ability to diagnose existing visual models using language on the Waterbirds and CelebA datasets, we can identify bugs comprehensible to human experts, uncovering not only known bugs but also previously unknown ones.
Understanding and Testing Generalization of Deep Networks on Out-of-Distribution Data
Nov 19, 2021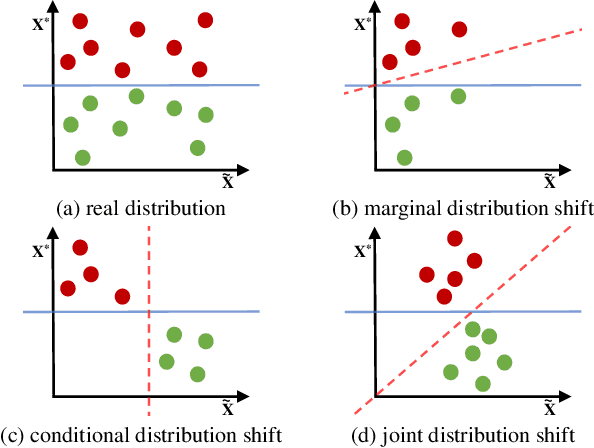
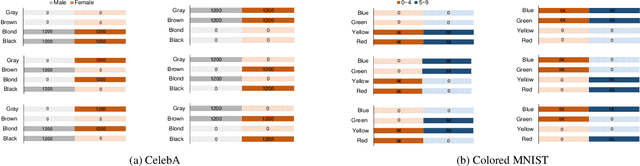
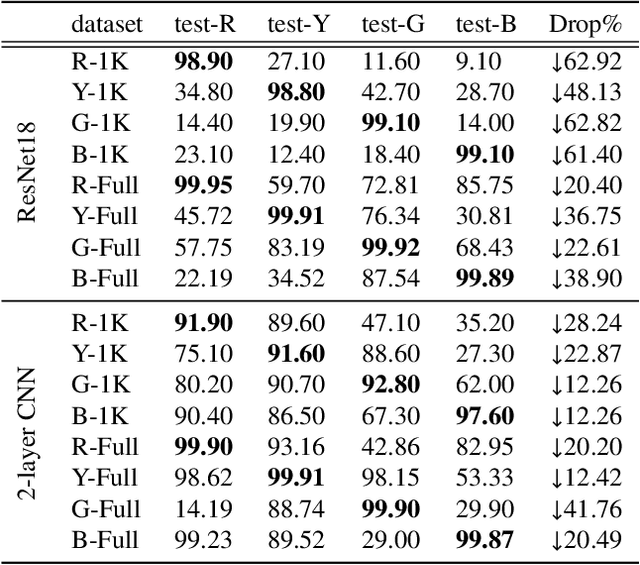
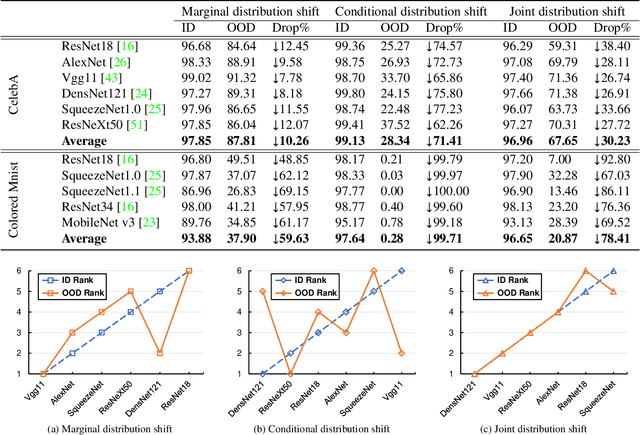
Deep network models perform excellently on In-Distribution (ID) data, but can significantly fail on Out-Of-Distribution (OOD) data. While developing methods focus on improving OOD generalization, few attention has been paid to evaluating the capability of models to handle OOD data. This study is devoted to analyzing the problem of experimental ID test and designing OOD test paradigm to accurately evaluate the practical performance. Our analysis is based on an introduced categorization of three types of distribution shifts to generate OOD data. Main observations include: (1) ID test fails in neither reflecting the actual performance of a single model nor comparing between different models under OOD data. (2) The ID test failure can be ascribed to the learned marginal and conditional spurious correlations resulted from the corresponding distribution shifts. Based on this, we propose novel OOD test paradigms to evaluate the generalization capacity of models to unseen data, and discuss how to use OOD test results to find bugs of models to guide model debugging.