 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGarment: Garment Estimation, Generation and Editing via Large Language Models
Dec 23, 2024We introduce ChatGarment, a novel approach that leverages large vision-language models (VLMs) to automate the estimation, generation, and editing of 3D garments from images or text descriptions. Unlike previous methods that struggle in real-world scenarios or lack interactive editing capabilities, ChatGarment can estimate sewing patterns from in-the-wild images or sketches, generate them from text descriptions, and edit garments based on user instructions, all within an interactive dialogue. These sewing patterns can then be draped into 3D garments, which are easily animatable and simulatable. This is achieved by finetuning a VLM to directly generate a JSON file that includes both textual descriptions of garment types and styles, as well as continuous numerical attributes. This JSON file is then used to create sewing patterns through a programming parametric model. To support this, we refine the existing programming model, GarmentCode, by expanding its garment type coverage and simplifying its structure for efficient VLM fine-tuning. Additionally, we construct a large-scale dataset of image-to-sewing-pattern and text-to-sewing-pattern pairs through an automated data pipeline. Extensive evaluations demonstrate ChatGarment's ability to accurately reconstruct, generate, and edit garments from multimodal inputs, highlighting its potential to revolutionize workflows in fashion and gaming applications. Code and data will be available at https://chatgarment.github.io/.
Gaussian Garments: Reconstructing Simulation-Ready Clothing with Photorealistic Appearance from Multi-View Video
Sep 12, 2024We introduce Gaussian Garments, a novel approach for reconstructing realistic simulation-ready garment assets from multi-view videos. Our method represents garments with a combination of a 3D mesh and a Gaussian texture that encodes both the color and high-frequency surface details. This representation enables accurate registration of garment geometries to multi-view videos and helps disentangle albedo textures from lighting effects. Furthermore, we demonstrate how a pre-trained graph neural network (GNN) can be fine-tuned to replicate the real behavior of each garment. The reconstructed Gaussian Garments can be automatically combined into multi-garment outfits and animated with the fine-tuned GNN.
Predicting the duration of traffic incidents for Sydney greater metropolitan area using machine learning methods
Jun 27, 2024This research presents a comprehensive approach to predicting the duration of traffic incidents and classifying them as short-term or long-term across the Sydney Metropolitan Area. Leveraging a dataset that encompasses detailed records of traffic incidents, road network characteristics, and socio-economic indicators, we train and evaluate a variety of advanced machine learning models including Gradient Boosted Decision Trees (GBDT), Random Forest, LightGBM, and XGBoost. The models are assessed using Root Mean Square Error (RMSE) for regression tasks and F1 score for classification tasks. Our experimental results demonstrate that XGBoost and LightGBM outperform conventional models with XGBoost achieving the lowest RMSE of 33.7 for predicting incident duration and highest classification F1 score of 0.62 for a 30-minute duration threshold. For classification, the 30-minute threshold balances performance with 70.84\% short-term duration classification accuracy and 62.72\% long-term duration classification accuracy. Feature importance analysis, employing both tree split counts and SHAP values, identifies the number of affected lanes, traffic volume, and types of primary and secondary vehicles as the most influential features. The proposed methodology not only achieves high predictive accuracy but also provides stakeholders with vital insights into factors contributing to incident durations. These insights enable more informed decision-making for traffic management and response strategies. The code is available by the link: https://github.com/Future-Mobility-Lab/SydneyIncidents
ContourCraft: Learning to Resolve Intersections in Neural Multi-Garment Simulations
May 15, 2024Learning-based approaches to cloth simulation have started to show their potential in recent years. However, handling collisions and intersections in neural simulations remains a largely unsolved problem. In this work, we present \moniker{}, a learning-based solution for handling intersections in neural cloth simulations. Unlike conventional approaches that critically rely on intersection-free inputs, \moniker{} robustly recovers from intersections introduced through missed collisions, self-penetrating bodies, or errors in manually designed multi-layer outfits. The technical core of \moniker{} is a novel intersection contour loss that penalizes interpenetrations and encourages rapid resolution thereof. We integrate our intersection loss with a collision-avoiding repulsion objective into a neural cloth simulation method based on graph neural networks (GNNs). We demonstrate our method's ability across a challenging set of diverse multi-layer outfits under dynamic human motions. Our extensive analysis indicates that \moniker{} significantly improves collision handling for learned simulation and produces visually compelling results.
4D-DRESS: A 4D Dataset of Real-world Human Clothing with Semantic Annotations
Apr 29, 2024



The studies of human clothing for digital avatars have predominantly relied on synthetic datasets. While easy to collect, synthetic data often fall short in realism and fail to capture authentic clothing dynamics. Addressing this gap, we introduce 4D-DRESS, the first real-world 4D dataset advancing human clothing research with its high-quality 4D textured scans and garment meshes. 4D-DRESS captures 64 outfits in 520 human motion sequences, amounting to 78k textured scans. Creating a real-world clothing dataset is challenging, particularly in annotating and segmenting the extensive and complex 4D human scans. To address this, we develop a semi-automatic 4D human parsing pipeline. We efficiently combine a human-in-the-loop process with automation to accurately label 4D scans in diverse garments and body movements. Leveraging precise annotations and high-quality garment meshes, we establish several benchmarks for clothing simulation and reconstruction. 4D-DRESS offers realistic and challenging data that complements synthetic sources, paving the way for advancements in research of lifelike human clothing. Website: https://ait.ethz.ch/4d-dress.
IncidentResponseGPT: Generating Traffic Incident Response Plans with Generative Artificial Intelligence
Apr 29, 2024



Traffic congestion due to road incidents poses a significant challenge in urban environments, leading to increased pollution, economic losses, and traffic congestion. Efficiently managing these incidents is imperative for mitigating their adverse effects; however, the complexity of urban traffic systems and the variety of potential incidents represent a considerable obstacle. This paper introduces IncidentResponseGPT, an innovative solution designed to assist traffic management authorities by providing rapid, informed, and adaptable traffic incident response plans. By integrating a Generative AI platform with real-time traffic incident reports and operational guidelines, our system aims to streamline the decision-making process in responding to traffic incidents. The research addresses the critical challenges involved in deploying AI in traffic management, including overcoming the complexity of urban traffic networks, ensuring real-time decision-making capabilities, aligning with local laws and regulations, and securing public acceptance for AI-driven systems. Through a combination of text analysis of accident reports, validation of AI recommendations through traffic simulation, and implementation of transparent and validated AI systems, IncidentResponseGPT offers a promising approach to optimizing traffic flow and reducing congestion in the face of traffic incidents. The relevance of this work extends to traffic management authorities, emergency response teams, and municipal bodies, all integral stakeholders in urban traffic control and incident management. By proposing a novel solution to the identified challenges, this research aims to develop a framework that not only facilitates faster resolution of traffic incidents but also minimizes their overall impact on urban traffic systems.
Integrating Large Language Models for Severity Classification in Traffic Incident Management: A Machine Learning Approach
Mar 20, 2024This study evaluates the impact of large language models on enhancing machine learning processes for managing traffic incidents. It examines the extent to which features generated by modern language models improve or match the accuracy of predictions when classifying the severity of incidents using accident reports. Multiple comparisons performed between combinations of language models and machine learning algorithms, including Gradient Boosted Decision Trees, Random Forests, and Extreme Gradient Boosting. Our research uses both conventional and language model-derived features from texts and incident reports, and their combinations to perform severity classification. Incorporating features from language models with those directly obtained from incident reports has shown to improve, or at least match, the performance of machine learning techniques in assigning severity levels to incidents, particularly when employing Random Forests and Extreme Gradient Boosting methods. This comparison was quantified using the F1-score over uniformly sampled data sets to obtain balanced severity classes. The primary contribution of this research is in the demonstration of how Large Language Models can be integrated into machine learning workflows for incident management, thereby simplifying feature extraction from unstructured text and enhancing or matching the precision of severity predictions using conventional machine learning pipeline. The engineering application of this research is illustrated through the effective use of these language processing models to refine the modelling process for incident severity classification. This work provides significant insights into the application of language processing capabilities in combination with traditional data for improving machine learning pipelines in the context of classifying incident severity.
HOOD: Hierarchical Graphs for Generalized Modelling of Clothing Dynamics
Dec 14, 2022We propose a method that leverages graph neural networks, multi-level message passing, and unsupervised training to enable real-time prediction of realistic clothing dynamics. Whereas existing methods based on linear blend skinning must be trained for specific garments, our method is agnostic to body shape and applies to tight-fitting garments as well as loose, free-flowing clothing. Our method furthermore handles changes in topology (e.g., garments with buttons or zippers) and material properties at inference time. As one key contribution, we propose a hierarchical message-passing scheme that efficiently propagates stiff stretching modes while preserving local detail. We empirically show that our method outperforms strong baselines quantitatively and that its results are perceived as more realistic than state-of-the-art methods.
Traffic Accident Risk Forecasting using Contextual Vision Transformers
Sep 20, 2022
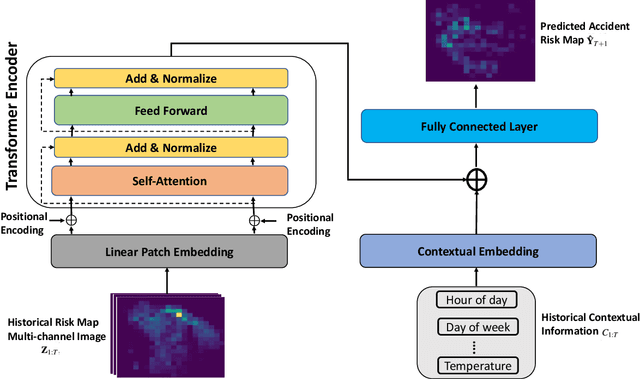
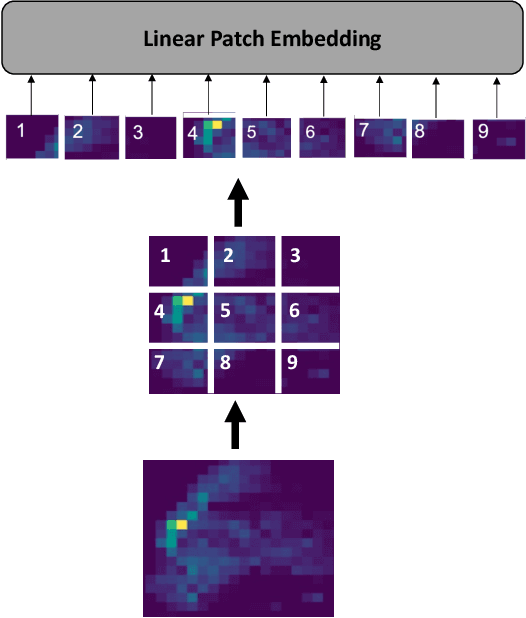
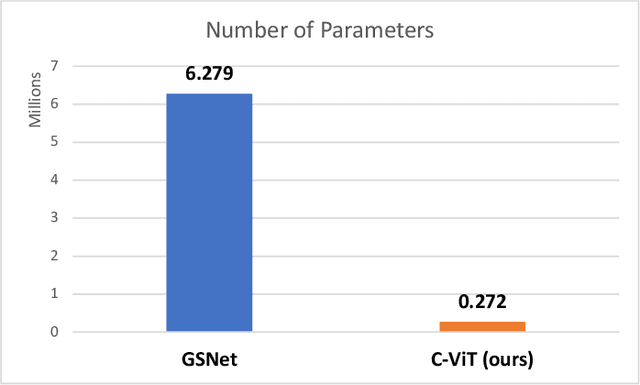
Recently, the problem of traffic accident risk forecasting has been getting the attention of the intelligent transportation systems community due to its significant impact on traffic clearance. This problem is commonly tackled in the literature by using data-driven approaches that model the spatial and temporal incident impact, since they were shown to be crucial for the traffic accident risk forecasting problem. To achieve this, most approaches build different architectures to capture the spatio-temporal correlations features, making them inefficient for large traffic accident datasets. Thus, in this work, we are proposing a novel unified framework, namely a contextual vision transformer, that can be trained in an end-to-end approach which can effectively reason about the spatial and temporal aspects of the problem while providing accurate traffic accident risk predictions. We evaluate and compare the performance of our proposed methodology against baseline approaches from the literature across two large-scale traffic accident datasets from two different geographical locations. The results have shown a significant improvement with roughly 2\% in RMSE score in comparison to previous state-of-art works (SoTA) in the literature. Moreover, our proposed approach has outperformed the SoTA technique over the two datasets while only requiring 23x fewer computational requirements.
Traffic incident duration prediction via a deep learning framework for text description encoding
Sep 19, 2022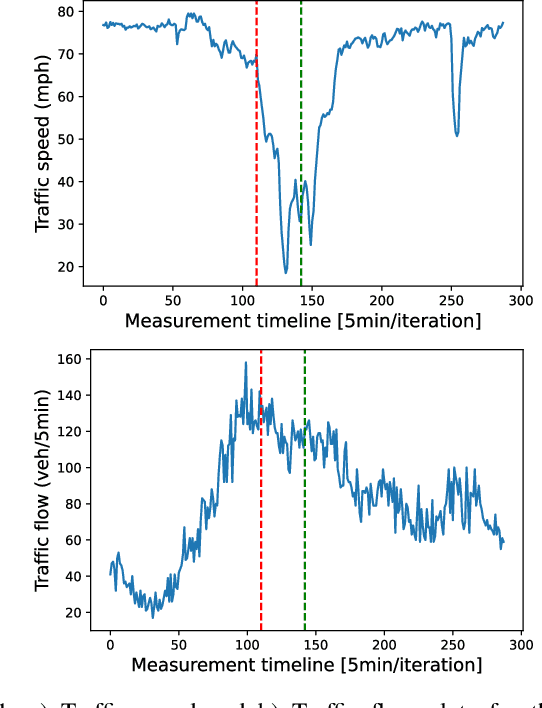
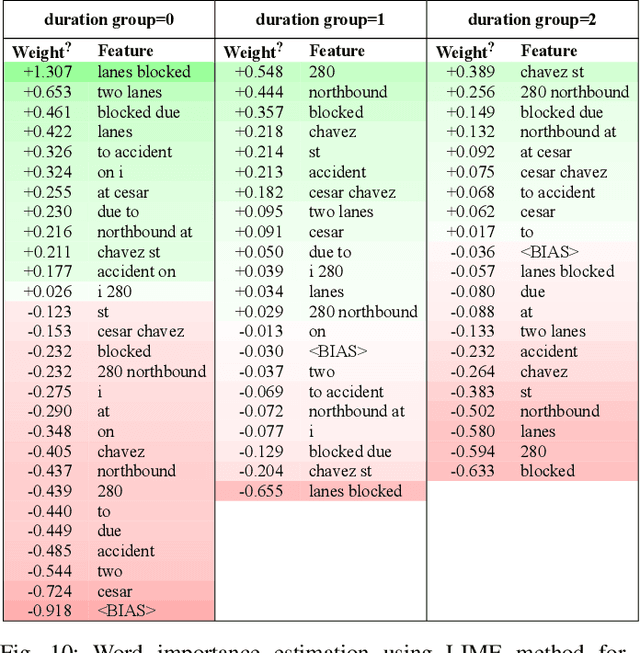
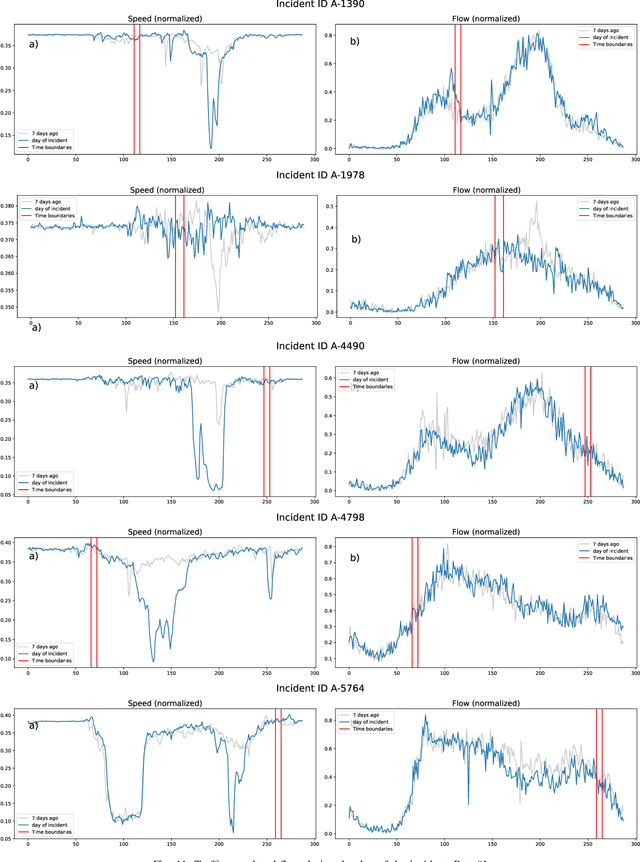
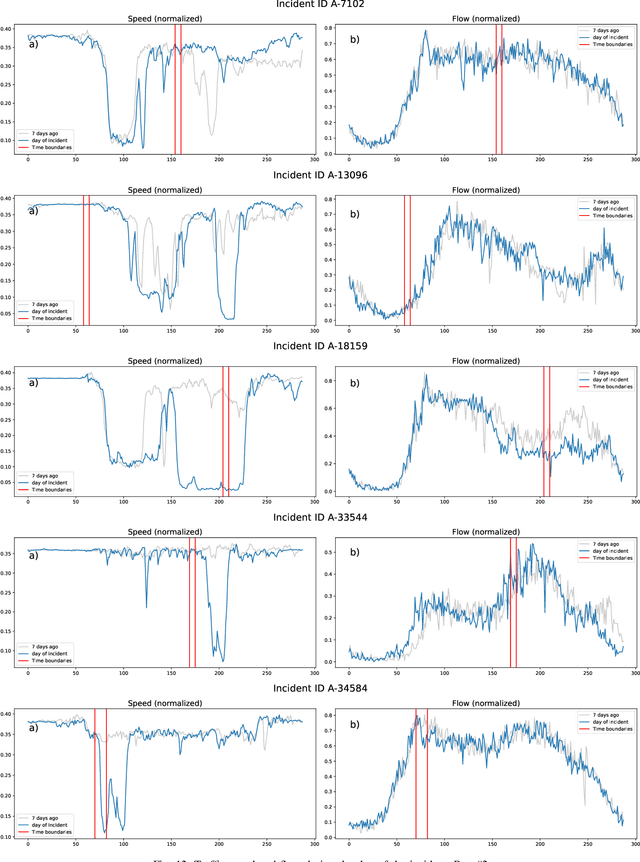
Predicting the traffic incident duration is a hard problem to solve due to the stochastic nature of incident occurrence in space and time, a lack of information at the beginning of a reported traffic disruption, and lack of advanced methods in transport engineering to derive insights from past accidents. This paper proposes a new fusion framework for predicting the incident duration from limited information by using an integration of machine learning with traffic flow/speed and incident description as features, encoded via several Deep Learning methods (ANN autoencoder and character-level LSTM-ANN sentiment classifier). The paper constructs a cross-disciplinary modelling approach in transport and data science. The approach improves the incident duration prediction accuracy over the top-performing ML models applied to baseline incident reports. Results show that our proposed method can improve the accuracy by $60\%$ when compared to standard linear or support vector regression models, and a further $7\%$ improvement with respect to the hybrid deep learning auto-encoded GBDT model which seems to outperform all other models. The application area is the city of San Francisco, rich in both traffic incident logs (Countrywide Traffic Accident Data set) and past historical traffic congestion information (5-minute precision measurements from Caltrans Performance Measurement System).