 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint What You Mean: Visually Grounded Instruction Policy
Dec 22, 2025



Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.
Towards Artificial Intelligence Research Assistant for Expert-Involved Learning
May 03, 2025Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have emerged as transformative tools in scientific research, yet their reliability and specific contributions to biomedical applications remain insufficiently characterized. In this study, we present \textbf{AR}tificial \textbf{I}ntelligence research assistant for \textbf{E}xpert-involved \textbf{L}earning (ARIEL), a multimodal dataset designed to benchmark and enhance two critical capabilities of LLMs and LMMs in biomedical research: summarizing extensive scientific texts and interpreting complex biomedical figures. To facilitate rigorous assessment, we create two open-source sets comprising biomedical articles and figures with designed questions. We systematically benchmark both open- and closed-source foundation models, incorporating expert-driven human evaluations conducted by doctoral-level experts. Furthermore, we improve model performance through targeted prompt engineering and fine-tuning strategies for summarizing research papers, and apply test-time computational scaling to enhance the reasoning capabilities of LMMs, achieving superior accuracy compared to human-expert corrections. We also explore the potential of using LMM Agents to generate scientific hypotheses from diverse multimodal inputs. Overall, our results delineate clear strengths and highlight significant limitations of current foundation models, providing actionable insights and guiding future advancements in deploying large-scale language and multi-modal models within biomedical research.
Low-Rank Contextual Reinforcement Learning from Heterogeneous Human Feedback
Dec 27, 2024Reinforcement learning from human feedback (RLHF) has become a cornerstone for aligning large language models with human preferences. However, the heterogeneity of human feedback, driven by diverse individual contexts and preferences, poses significant challenges for reward learning. To address this, we propose a Low-rank Contextual RLHF (LoCo-RLHF) framework that integrates contextual information to better model heterogeneous feedback while maintaining computational efficiency. Our approach builds on a contextual preference model, leveraging the intrinsic low-rank structure of the interaction between user contexts and query-answer pairs to mitigate the high dimensionality of feature representations. Furthermore, we address the challenge of distributional shifts in feedback through our Pessimism in Reduced Subspace (PRS) policy, inspired by pessimistic offline reinforcement learning techniques. We theoretically demonstrate that our policy achieves a tighter sub-optimality gap compared to existing methods. Extensive experiments validate the effectiveness of LoCo-RLHF, showcasing its superior performance in personalized RLHF settings and its robustness to distribution shifts.
Minimax Regret Learning for Data with Heterogeneous Subgroups
May 02, 2024Modern complex datasets often consist of various sub-populations. To develop robust and generalizable methods in the presence of sub-population heterogeneity, it is important to guarantee a uniform learning performance instead of an average one. In many applications, prior information is often available on which sub-population or group the data points belong to. Given the observed groups of data, we develop a min-max-regret (MMR) learning framework for general supervised learning, which targets to minimize the worst-group regret. Motivated from the regret-based decision theoretic framework, the proposed MMR is distinguished from the value-based or risk-based robust learning methods in the existing literature. The regret criterion features several robustness and invariance properties simultaneously. In terms of generalizability, we develop the theoretical guarantee for the worst-case regret over a super-population of the meta data, which incorporates the observed sub-populations, their mixtures, as well as other unseen sub-populations that could be approximated by the observed ones. We demonstrate the effectiveness of our method through extensive simulation studies and an application to kidney transplantation data from hundreds of transplant centers.
Low-Rank Online Dynamic Assortment with Dual Contextual Information
Apr 19, 2024



As e-commerce expands, delivering real-time personalized recommendations from vast catalogs poses a critical challenge for retail platforms. Maximizing revenue requires careful consideration of both individual customer characteristics and available item features to optimize assortments over time. In this paper, we consider the dynamic assortment problem with dual contexts -- user and item features. In high-dimensional scenarios, the quadratic growth of dimensions complicates computation and estimation. To tackle this challenge, we introduce a new low-rank dynamic assortment model to transform this problem into a manageable scale. Then we propose an efficient algorithm that estimates the intrinsic subspaces and utilizes the upper confidence bound approach to address the exploration-exploitation trade-off in online decision making. Theoretically, we establish a regret bound of $\tilde{O}((d_1+d_2)r\sqrt{T})$, where $d_1, d_2$ represent the dimensions of the user and item features respectively, $r$ is the rank of the parameter matrix, and $T$ denotes the time horizon. This bound represents a substantial improvement over prior literature, made possible by leveraging the low-rank structure. Extensive simulations and an application to the Expedia hotel recommendation dataset further demonstrate the advantages of our proposed method.
Mutual-Learning Knowledge Distillation for Nighttime UAV Tracking
Dec 22, 2023



Nighttime unmanned aerial vehicle (UAV) tracking has been facilitated with indispensable plug-and-play low-light enhancers. However, the introduction of low-light enhancers increases the extra computational burden for the UAV, significantly hindering the development of real-time UAV applications. Meanwhile, these state-of-the-art (SOTA) enhancers lack tight coupling with the advanced daytime UAV tracking approach. To solve the above issues, this work proposes a novel mutual-learning knowledge distillation framework for nighttime UAV tracking, i.e., MLKD. This framework is constructed to learn a compact and fast nighttime tracker via knowledge transferring from the teacher and knowledge sharing among various students. Specifically, an advanced teacher based on a SOTA enhancer and a superior tracking backbone is adopted for guiding the student based only on the tight coupling-aware tracking backbone to directly extract nighttime object features. To address the biased learning of a single student, diverse lightweight students with different distillation methods are constructed to focus on various aspects of the teacher's knowledge. Moreover, an innovative mutual-learning room is designed to elect the superior student candidate to assist the remaining students frame-by-frame in the training phase. Furthermore, the final best student, i.e., MLKD-Track, is selected through the testing dataset. Extensive experiments demonstrate the effectiveness and superiority of MLKD and MLKD-Track. The practicality of the MLKD-Track is verified in real-world tests with different challenging situations. The code is available at https://github.com/lyfeng001/MLKD.
Consistency of Lloyd's Algorithm Under Perturbations
Sep 01, 2023
In the context of unsupervised learning, Lloyd's algorithm is one of the most widely used clustering algorithms. It has inspired a plethora of work investigating the correctness of the algorithm under various settings with ground truth clusters. In particular, in 2016, Lu and Zhou have shown that the mis-clustering rate of Lloyd's algorithm on $n$ independent samples from a sub-Gaussian mixture is exponentially bounded after $O(\log(n))$ iterations, assuming proper initialization of the algorithm. However, in many applications, the true samples are unobserved and need to be learned from the data via pre-processing pipelines such as spectral methods on appropriate data matrices. We show that the mis-clustering rate of Lloyd's algorithm on perturbed samples from a sub-Gaussian mixture is also exponentially bounded after $O(\log(n))$ iterations under the assumptions of proper initialization and that the perturbation is small relative to the sub-Gaussian noise. In canonical settings with ground truth clusters, we derive bounds for algorithms such as $k$-means$++$ to find good initializations and thus leading to the correctness of clustering via the main result. We show the implications of the results for pipelines measuring the statistical significance of derived clusters from data such as SigClust. We use these general results to derive implications in providing theoretical guarantees on the misclustering rate for Lloyd's algorithm in a host of applications, including high-dimensional time series, multi-dimensional scaling, and community detection for sparse networks via spectral clustering.
A Scalable Arrangement Method for Aperiodic Array Antennas to Reduce Peak Sidelobe Level
Jul 04, 2023Peak sidelobe level reduction (PSLR) is crucial in the application of large-scale array antenna, which directly determines the radiation performance of array antenna. We study the PSLR of subarray level aperiodic arrays and propose three array structures: dislocated subarrays with uniform elements (DSUE), uniform subarrays with random elements (USRE), dislocated subarrays with random elements (DSRE). To optimize the dislocation position of subarrays and random position of elements, the improved Bat algorithm (IBA) is applied. To draw the comparison of PSLR effect among these three array structures, we take three size of array antennas from small to large as examples to simulate and calculate the redundancy and peak sidelobe level (PSLL) of them. The results show that DSRE is the optimal array structure by analyzing the dislocation distance of subarray, scanning angle and applicable frequency. The proposed design method is a universal and scalable method, which is of great application value to the design of large-scale aperiodic array antenna.
Asymptotic Inference for Multi-Stage Stationary Treatment Policy with High Dimensional Features
Jan 29, 2023



Dynamic treatment rules or policies are a sequence of decision functions over multiple stages that are tailored to individual features. One important class of treatment policies for practice, namely multi-stage stationary treatment policies, prescribe treatment assignment probabilities using the same decision function over stages, where the decision is based on the same set of features consisting of both baseline variables (e.g., demographics) and time-evolving variables (e.g., routinely collected disease biomarkers). Although there has been extensive literature to construct valid inference for the value function associated with the dynamic treatment policies, little work has been done for the policies themselves, especially in the presence of high dimensional feature variables. We aim to fill in the gap in this work. Specifically, we first estimate the multistage stationary treatment policy based on an augmented inverse probability weighted estimator for the value function to increase the asymptotic efficiency, and further apply a penalty to select important feature variables. We then construct one-step improvement of the policy parameter estimators. Theoretically, we show that the improved estimators are asymptotically normal, even if nuisance parameters are estimated at a slow convergence rate and the dimension of the feature variables increases exponentially with the sample size. Our numerical studies demonstrate that the proposed method has satisfactory performance in small samples, and that the performance can be improved with a choice of the augmentation term that approximates the rewards or minimizes the variance of the value function.
Edge-based Monocular Thermal-Inertial Odometry in Visually Degraded Environments
Oct 18, 2022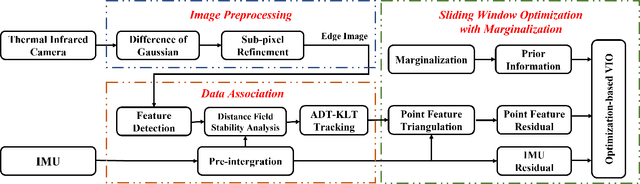
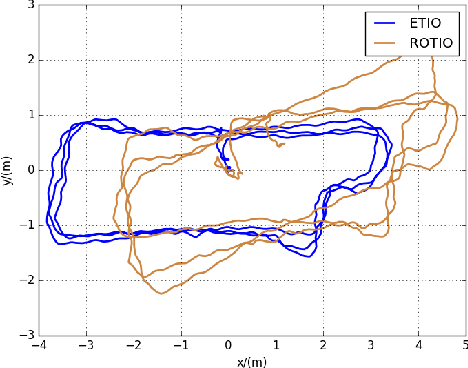
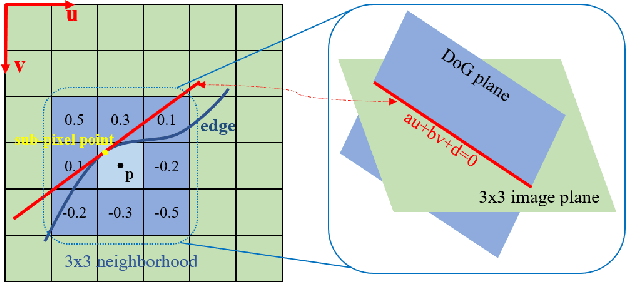
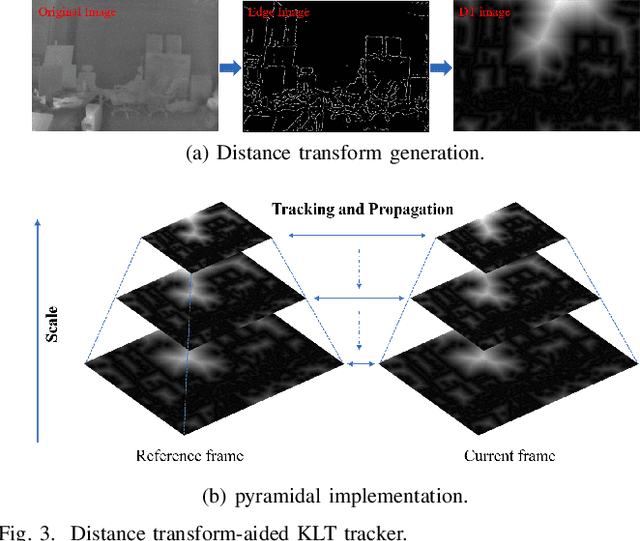
State estimation in complex illumination environments based on conventional visual-inertial odometry is a challenging task due to the severe visual degradation of the visual camera. The thermal infrared camera is capable of all-day time and is less affected by illumination variation. However, most existing visual data association algorithms are incompatible because the thermal infrared data contains large noise and low contrast. Motivated by the phenomenon that thermal radiation varies most significantly at the edges of objects, the study proposes an ETIO, which is the first edge-based monocular thermal-inertial odometry for robust localization in visually degraded environments. Instead of the raw image, we utilize the binarized image from edge extraction for pose estimation to overcome the poor thermal infrared image quality. Then, an adaptive feature tracking strategy ADT-KLT is developed for robust data association based on limited edge information and its distance distribution. Finally, a pose graph optimization performs real-time estimation over a sliding window of recent states by combining IMU pre-integration with reprojection error of all edge feature observations. We evaluated the performance of the proposed system on public datasets and real-world experiments and compared it against state-of-the-art methods. The proposed ETIO was verified with the ability to enable accurate and robust localization all-day time.