 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Artificial Intelligence Research Assistant for Expert-Involved Learning
May 03, 2025Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have emerged as transformative tools in scientific research, yet their reliability and specific contributions to biomedical applications remain insufficiently characterized. In this study, we present \textbf{AR}tificial \textbf{I}ntelligence research assistant for \textbf{E}xpert-involved \textbf{L}earning (ARIEL), a multimodal dataset designed to benchmark and enhance two critical capabilities of LLMs and LMMs in biomedical research: summarizing extensive scientific texts and interpreting complex biomedical figures. To facilitate rigorous assessment, we create two open-source sets comprising biomedical articles and figures with designed questions. We systematically benchmark both open- and closed-source foundation models, incorporating expert-driven human evaluations conducted by doctoral-level experts. Furthermore, we improve model performance through targeted prompt engineering and fine-tuning strategies for summarizing research papers, and apply test-time computational scaling to enhance the reasoning capabilities of LMMs, achieving superior accuracy compared to human-expert corrections. We also explore the potential of using LMM Agents to generate scientific hypotheses from diverse multimodal inputs. Overall, our results delineate clear strengths and highlight significant limitations of current foundation models, providing actionable insights and guiding future advancements in deploying large-scale language and multi-modal models within biomedical research.
Estimates of daily ground-level NO2 concentrations in China based on big data and machine learning approaches
Nov 18, 2020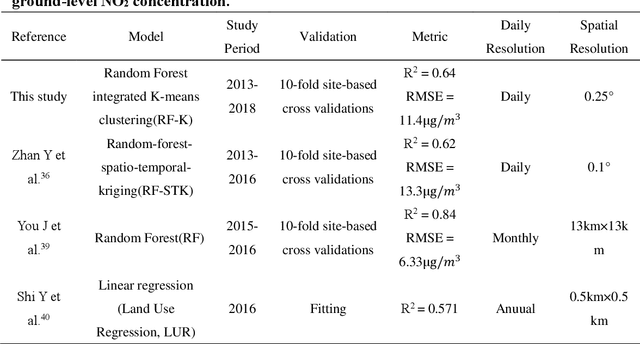
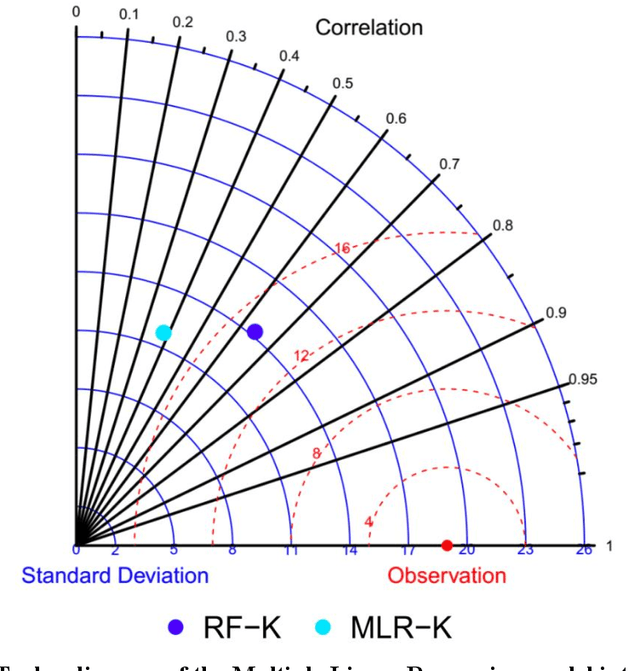
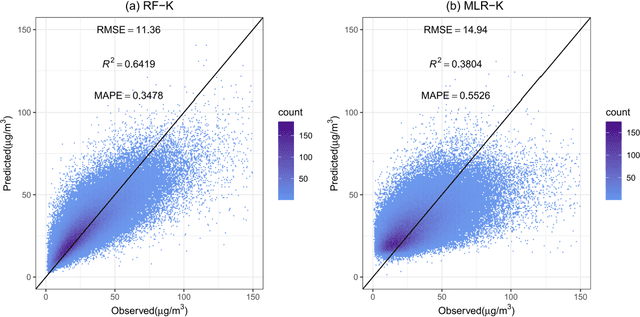
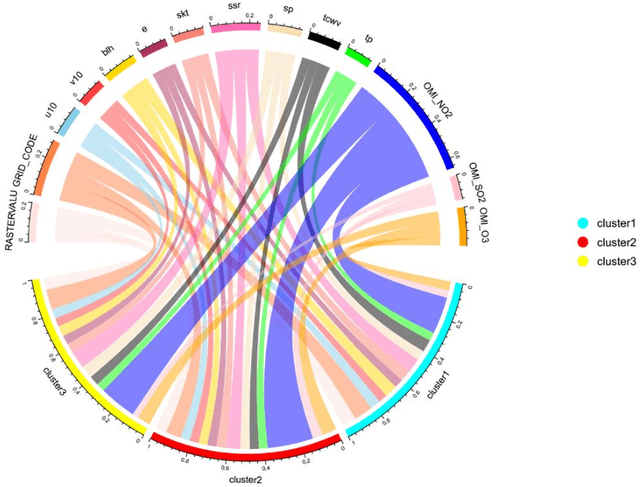
Nitrogen dioxide (NO2) is one of the most important atmospheric pollutants. However, current ground-level NO2 concentration data are lack of either high-resolution coverage or full coverage national wide, due to the poor quality of source data and the computing power of the models. To our knowledge, this study is the first to estimate the ground-level NO2 concentration in China with national coverage as well as relatively high spatiotemporal resolution (0.25 degree; daily intervals) over the newest past 6 years (2013-2018). We advanced a Random Forest model integrated K-means (RF-K) for the estimates with multi-source parameters. Besides meteorological parameters, satellite retrievals parameters, we also, for the first time, introduce socio-economic parameters to assess the impact by human activities. The results show that: (1) the RF-K model we developed shows better prediction performance than other models, with cross-validation R2 = 0.64 (MAPE = 34.78%). (2) The annual average concentration of NO2 in China showed a weak increasing trend . While in the economic zones such as Beijing-Tianjin-Hebei region, Yangtze River Delta, and Pearl River Delta, the NO2 concentration there even decreased or remained unchanged, especially in spring. Our dataset has verified that pollutant controlling targets have been achieved in these areas. With mapping daily nationwide ground-level NO2 concentrations, this study provides timely data with high quality for air quality management for China. We provide a universal model framework to quickly generate a timely national atmospheric pollutants concentration map with a high spatial-temporal resolution, based on improved machine learning methods.