 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Stochastic Optimization for Global Contrastive Learning: Small Batch Does Not Harm Performance
Feb 24, 2022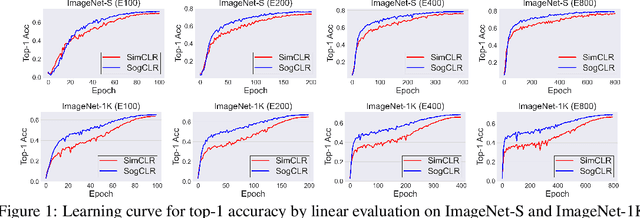
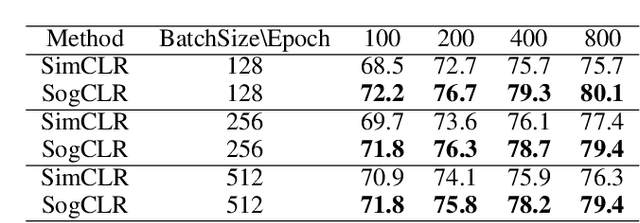
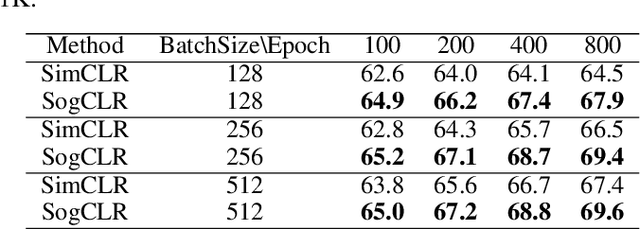
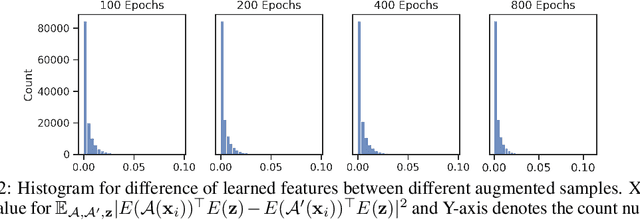
In this paper, we study contrastive learning from an optimization perspective, aiming to analyze and address a fundamental issue of existing contrastive learning methods that either rely on a large batch size or a large dictionary. We consider a global objective for contrastive learning, which contrasts each positive pair with all negative pairs for an anchor point. From the optimization perspective, we explain why existing methods such as SimCLR requires a large batch size in order to achieve a satisfactory result. In order to remove such requirement, we propose a memory-efficient Stochastic Optimization algorithm for solving the Global objective of Contrastive Learning of Representations, named SogCLR. We show that its optimization error is negligible under a reasonable condition after a sufficient number of iterations or is diminishing for a slightly different global contrastive objective. Empirically, we demonstrate that on ImageNet with a batch size 256, SogCLR achieves a performance of 69.4% for top-1 linear evaluation accuracy using ResNet-50, which is on par with SimCLR (69.3%) with a large batch size 8,192. We also attempt to show that the proposed optimization technique is generic and can be applied to solving other contrastive losses, e.g., two-way contrastive losses for bimodal contrastive learning.
Generalized Multi-Relational Graph Convolution Network
Jun 12, 2020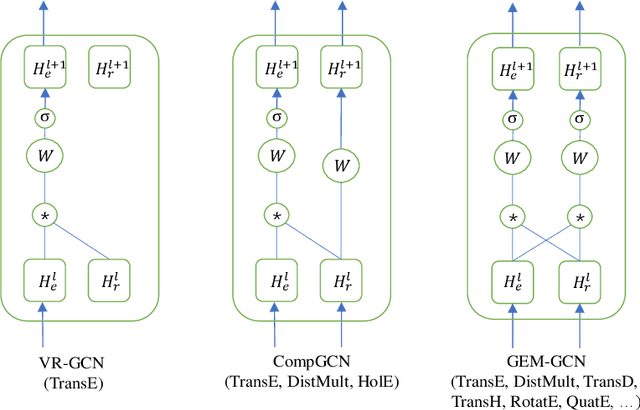
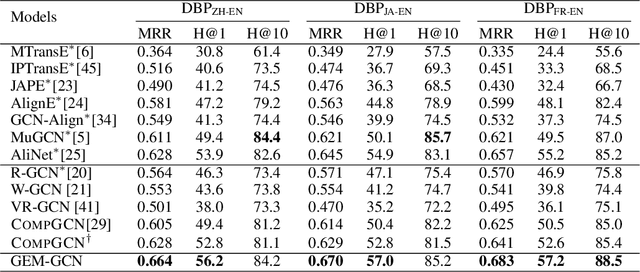
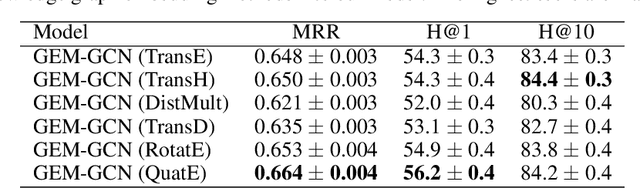

Graph Convolutional Networks (GCNs) have received increasing attention in recent machine learning. How to effectively leverage the rich structural information in complex graphs, such as knowledge graphs with heterogeneous types of entities and relations, is a primary open challenge in the field. Most GCN methods are either restricted to graphs with a homogeneous type of edges (e.g., citation links only), or focusing on representation learning for nodes only instead of jointly optimizing the embeddings of both nodes and edges for target-driven objectives. This paper addresses these limitations by proposing a novel framework, namely the GEneralized Multi-relational Graph Convolutional Networks (GEM-GCN), which combines the power of GCNs in graph-based belief propagation and the strengths of advanced knowledge-base embedding methods, and goes beyond. Our theoretical analysis shows that GEM-GCN offers an elegant unification of several well-known GCN methods as specific cases, with a new perspective of graph convolution. Experimental results on benchmark datasets show the advantageous performance of GEM-GCN over strong baseline methods in the tasks of knowledge graph alignment and entity classification.
Graph-Revised Convolutional Network
Nov 17, 2019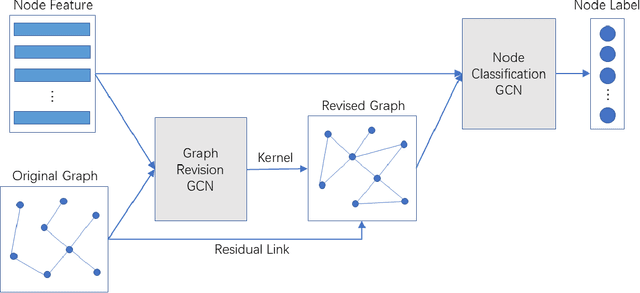
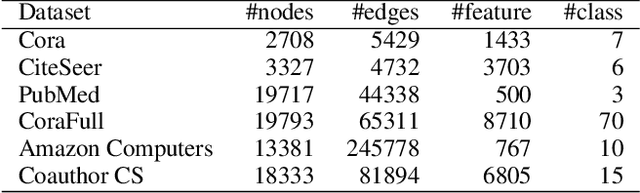
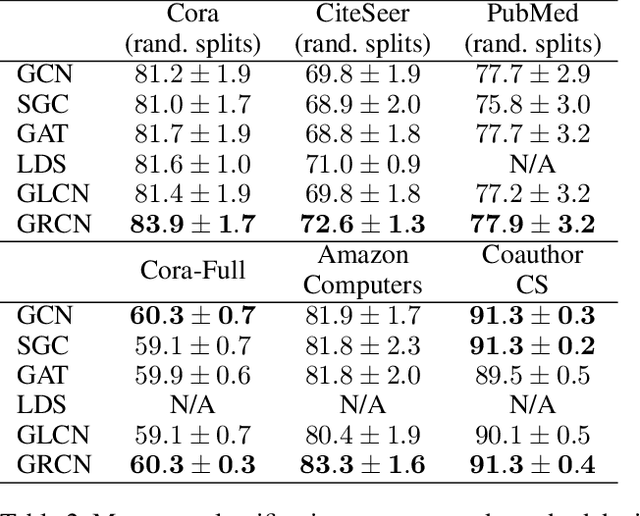
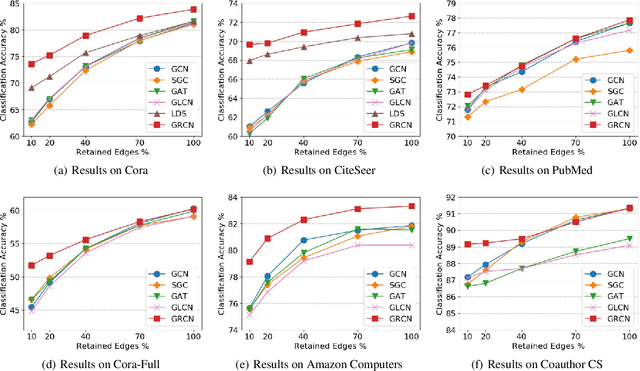
Graph Convolutional Networks (GCNs) have received increasing attention in the machine learning community for effectively leveraging both the content features of nodes and the linkage patterns across graphs in various applications. As real-world graphs are often incomplete and noisy, treating them as ground-truth information, which is a common practice in most GCNs, unavoidably leads to sub-optimal solutions. Existing efforts for addressing this problem either involve an over-parameterized model which is difficult to scale, or simply re-weight observed edges without dealing with the missing-edge issue. This paper proposes a novel framework called Graph-Revised Convolutional Network (GRCN), which avoids both extremes. Specifically, a GCN-based graph revision module is introduced for predicting missing edges and revising edge weights w.r.t. downstream tasks via joint optimization. A theoretical analysis reveals the connection between GRCN and previous work on multigraph belief propagation. Experiments on six benchmark datasets show that GRCN consistently outperforms strong baseline methods by a large margin, especially when the original graphs are severely incomplete or the labeled instances for model training are highly sparse.
Active Learning for Graph Neural Networks via Node Feature Propagation
Oct 16, 2019
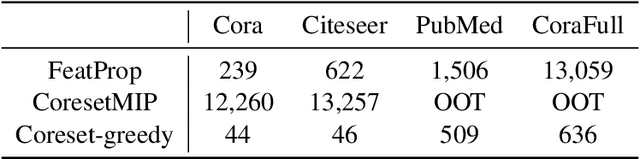
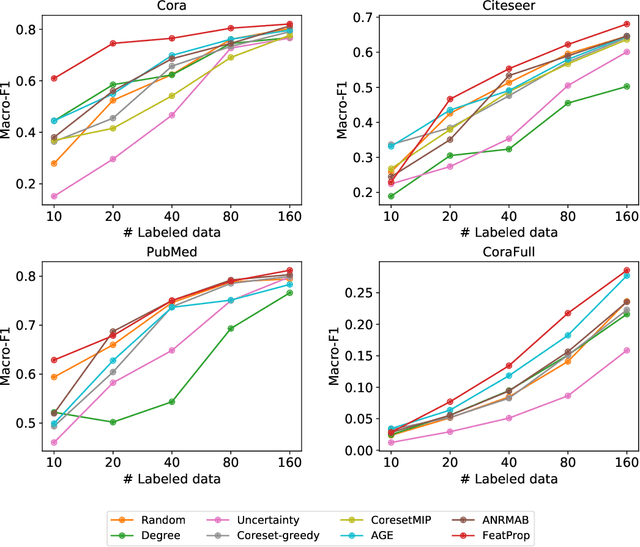
Graph Neural Networks (GNNs) for prediction tasks like node classification or edge prediction have received increasing attention in recent machine learning from graphically structured data. However, a large quantity of labeled graphs is difficult to obtain, which significantly limits the true success of GNNs. Although active learning has been widely studied for addressing label-sparse issues with other data types like text, images, etc., how to make it effective over graphs is an open question for research. In this paper, we present an investigation on active learning with GNNs for node classification tasks. Specifically, we propose a new method, which uses node feature propagation followed by K-Medoids clustering of the nodes for instance selection in active learning. With a theoretical bound analysis we justify the design choice of our approach. In our experiments on four benchmark datasets, the proposed method outperforms other representative baseline methods consistently and significantly.
StoryGAN: A Sequential Conditional GAN for Story Visualization
Dec 06, 2018

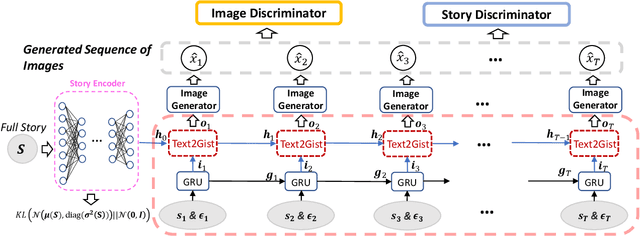
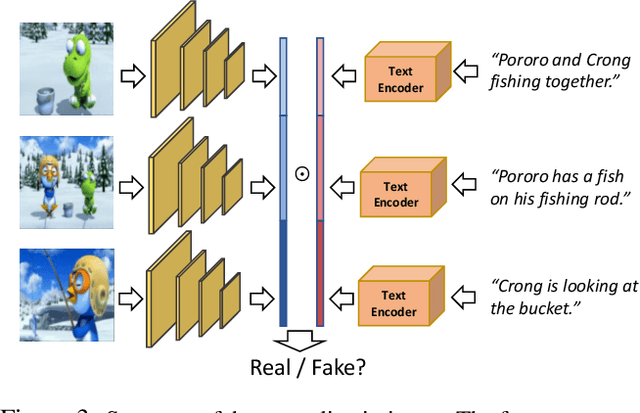
In this work we propose a new task called Story Visualization. Given a multi-sentence paragraph, the story is visualized by generating a sequence of images, one for each sentence. In contrast to video generation, story visualization focuses less on the continuity in generated images (frames), but more on the global consistency across dynamic scenes and characters -- a challenge that has not been addressed by any single-image or video generation methods. Therefore, we propose a new story-to-image-sequence generation model, StoryGAN, based on the sequential conditional GAN framework. Our model is unique in that it consists of a deep Context Encoder that dynamically tracks the story flow, and two discriminators at the story and image levels, respectively, to enhance the image quality and the consistency of the generated sequences. To evaluate the model, we modified existing datasets to create the CLEVR-SV and Pororo-SV datasets. Empirically, StoryGAN outperformed state-of-the-art models in image quality, contextual consistency metrics, and human evaluation.
Switch-based Active Deep Dyna-Q: Efficient Adaptive Planning for Task-Completion Dialogue Policy Learning
Nov 19, 2018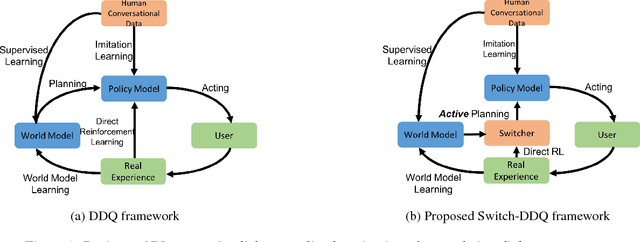

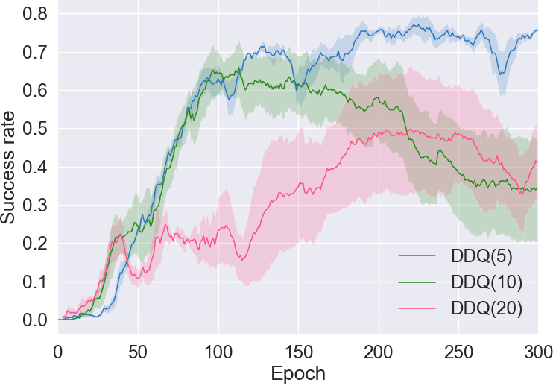
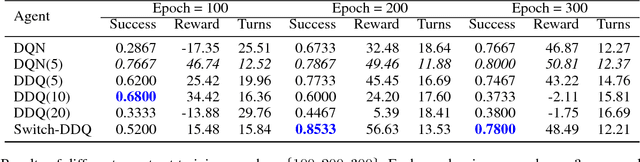
Training task-completion dialogue agents with reinforcement learning usually requires a large number of real user experiences. The Dyna-Q algorithm extends Q-learning by integrating a world model, and thus can effectively boost training efficiency using simulated experiences generated by the world model. The effectiveness of Dyna-Q, however, depends on the quality of the world model - or implicitly, the pre-specified ratio of real vs. simulated experiences used for Q-learning. To this end, we extend the recently proposed Deep Dyna-Q (DDQ) framework by integrating a switcher that automatically determines whether to use a real or simulated experience for Q-learning. Furthermore, we explore the use of active learning for improving sample efficiency, by encouraging the world model to generate simulated experiences in the state-action space where the agent has not (fully) explored. Our results show that by combining switcher and active learning, the new framework named as Switch-based Active Deep Dyna-Q (Switch-DDQ), leads to significant improvement over DDQ and Q-learning baselines in both simulation and human evaluations.
Unsupervised Cross-lingual Transfer of Word Embedding Spaces
Sep 10, 2018
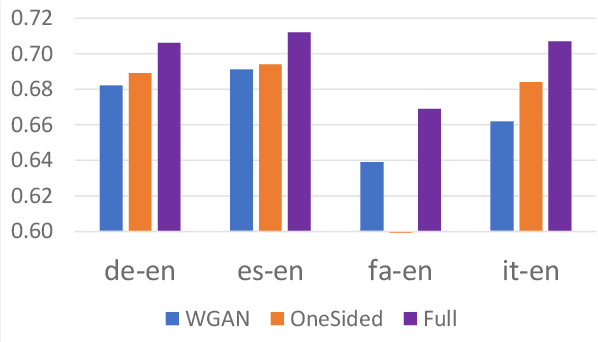
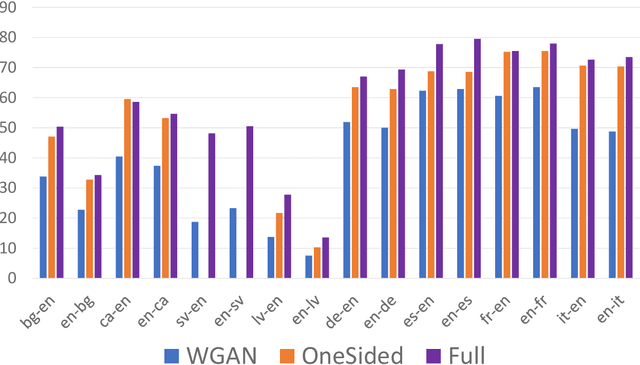
Cross-lingual transfer of word embeddings aims to establish the semantic mappings among words in different languages by learning the transformation functions over the corresponding word embedding spaces. Successfully solving this problem would benefit many downstream tasks such as to translate text classification models from resource-rich languages (e.g. English) to low-resource languages. Supervised methods for this problem rely on the availability of cross-lingual supervision, either using parallel corpora or bilingual lexicons as the labeled data for training, which may not be available for many low resource languages. This paper proposes an unsupervised learning approach that does not require any cross-lingual labeled data. Given two monolingual word embedding spaces for any language pair, our algorithm optimizes the transformation functions in both directions simultaneously based on distributional matching as well as minimizing the back-translation losses. We use a neural network implementation to calculate the Sinkhorn distance, a well-defined distributional similarity measure, and optimize our objective through back-propagation. Our evaluation on benchmark datasets for bilingual lexicon induction and cross-lingual word similarity prediction shows stronger or competitive performance of the proposed method compared to other state-of-the-art supervised and unsupervised baseline methods over many language pairs.
Contextual Encoding for Translation Quality Estimation
Sep 01, 2018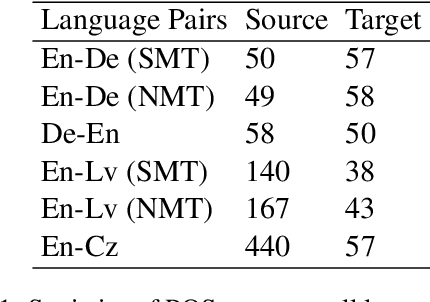
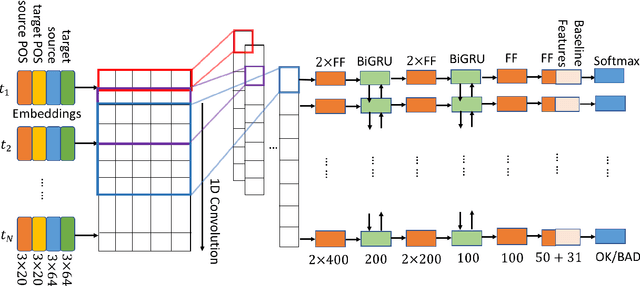

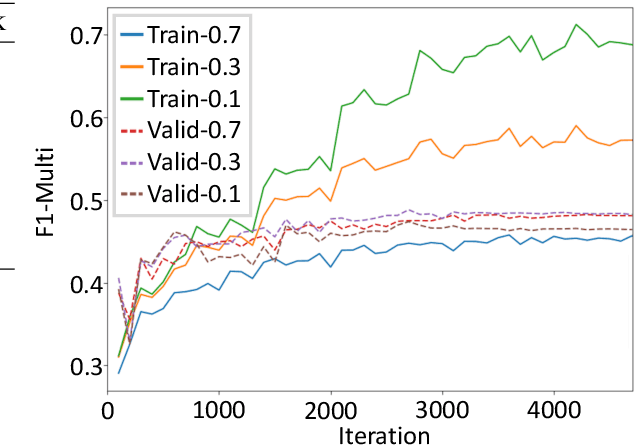
The task of word-level quality estimation (QE) consists of taking a source sentence and machine-generated translation, and predicting which words in the output are correct and which are wrong. In this paper, propose a method to effectively encode the local and global contextual information for each target word using a three-part neural network approach. The first part uses an embedding layer to represent words and their part-of-speech tags in both languages. The second part leverages a one-dimensional convolution layer to integrate local context information for each target word. The third part applies a stack of feed-forward and recurrent neural networks to further encode the global context in the sentence before making the predictions. This model was submitted as the CMU entry to the WMT2018 shared task on QE, and achieves strong results, ranking first in three of the six tracks.
Analogical Inference for Multi-Relational Embeddings
Jul 06, 2017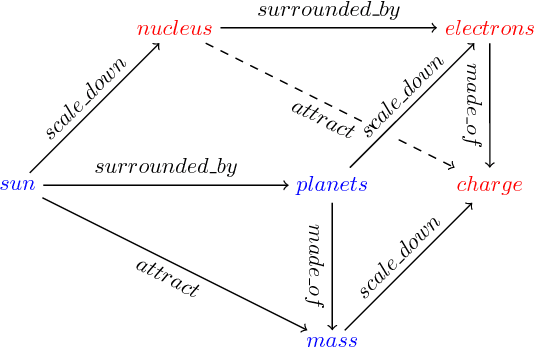

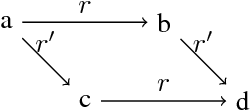
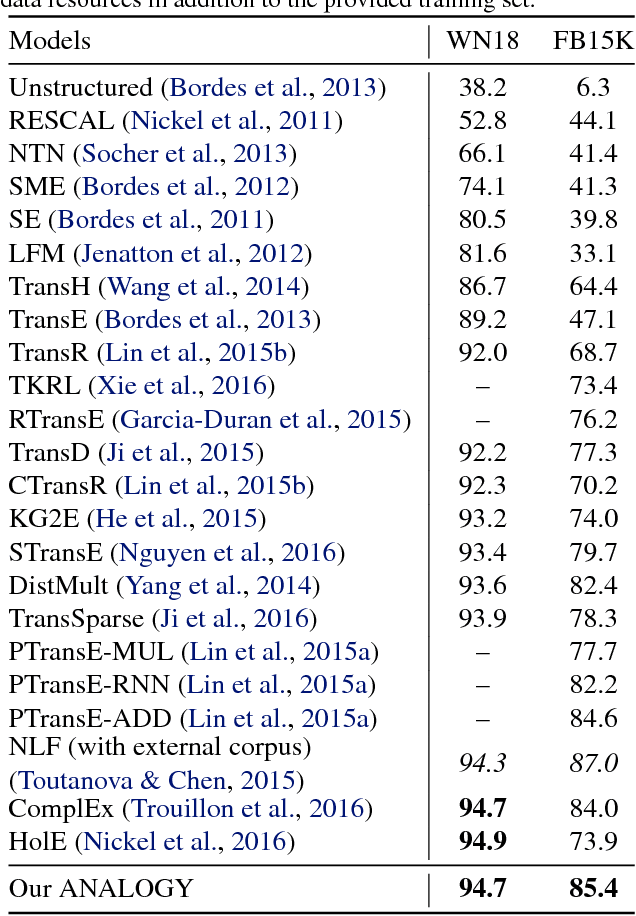
Large-scale multi-relational embedding refers to the task of learning the latent representations for entities and relations in large knowledge graphs. An effective and scalable solution for this problem is crucial for the true success of knowledge-based inference in a broad range of applications. This paper proposes a novel framework for optimizing the latent representations with respect to the \textit{analogical} properties of the embedded entities and relations. By formulating the learning objective in a differentiable fashion, our model enjoys both theoretical power and computational scalability, and significantly outperformed a large number of representative baseline methods on benchmark datasets. Furthermore, the model offers an elegant unification of several well-known methods in multi-relational embedding, which can be proven to be special instantiations of our framework.
Review Networks for Caption Generation
Oct 27, 2016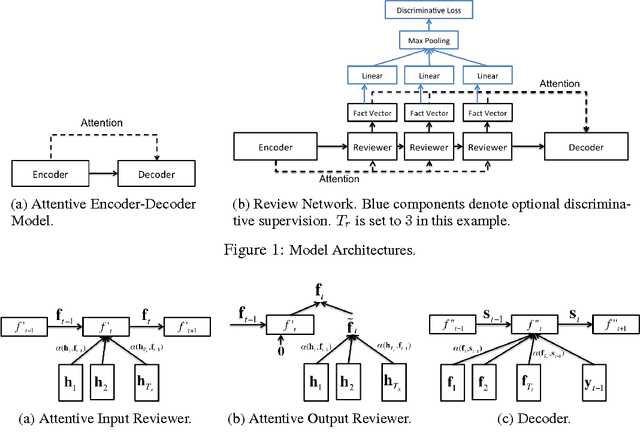
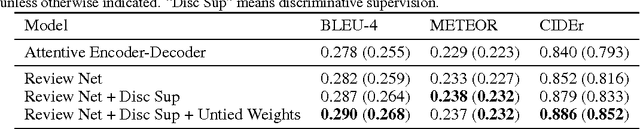
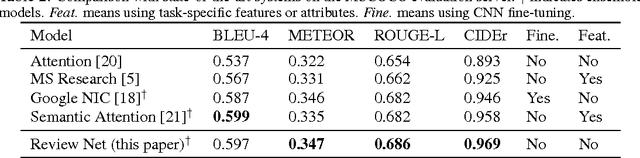

We propose a novel extension of the encoder-decoder framework, called a review network. The review network is generic and can enhance any existing encoder- decoder model: in this paper, we consider RNN decoders with both CNN and RNN encoders. The review network performs a number of review steps with attention mechanism on the encoder hidden states, and outputs a thought vector after each review step; the thought vectors are used as the input of the attention mechanism in the decoder. We show that conventional encoder-decoders are a special case of our framework. Empirically, we show that our framework improves over state-of- the-art encoder-decoder systems on the tasks of image captioning and source code captioning.