 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIGA: A Unified Multi-task Generation Framework for Conversational Text-to-SQL
Dec 19, 2022



Conversational text-to-SQL is designed to translate multi-turn natural language questions into their corresponding SQL queries. Most state-of-the-art conversational text- to-SQL methods are incompatible with generative pre-trained language models (PLMs), such as T5. In this paper, we present a two-stage unified MultI-task Generation frAmework (MIGA) that leverages PLMs' ability to tackle conversational text-to-SQL. In the pre-training stage, MIGA first decomposes the main task into several related sub-tasks and then unifies them into the same sequence-to-sequence (Seq2Seq) paradigm with task-specific natural language prompts to boost the main task from multi-task training. Later in the fine-tuning stage, we propose four SQL perturbations to alleviate the error propagation problem. MIGA tends to achieve state-of-the-art performance on two benchmarks (SparC and CoSQL). We also provide extensive analyses and discussions to shed light on some new perspectives for conversational text-to-SQL.
Lamarckian Platform: Pushing the Boundaries of Evolutionary Reinforcement Learning towards Asynchronous Commercial Games
Sep 21, 2022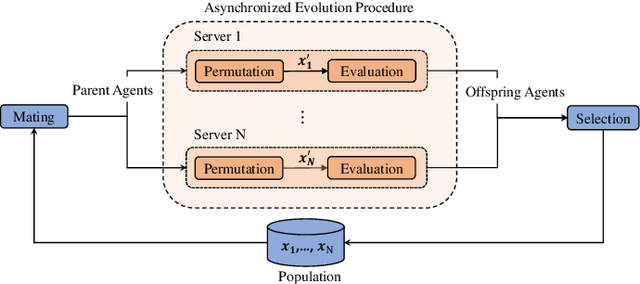
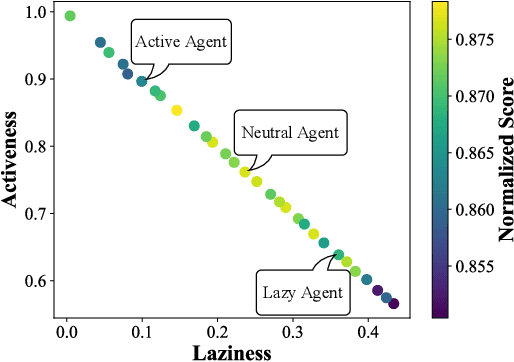

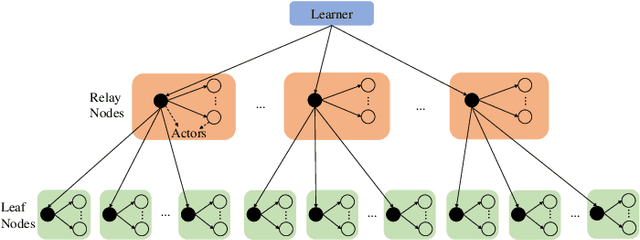
Despite the emerging progress of integrating evolutionary computation into reinforcement learning, the absence of a high-performance platform endowing composability and massive parallelism causes non-trivial difficulties for research and applications related to asynchronous commercial games. Here we introduce Lamarckian - an open-source platform featuring support for evolutionary reinforcement learning scalable to distributed computing resources. To improve the training speed and data efficiency, Lamarckian adopts optimized communication methods and an asynchronous evolutionary reinforcement learning workflow. To meet the demand for an asynchronous interface by commercial games and various methods, Lamarckian tailors an asynchronous Markov Decision Process interface and designs an object-oriented software architecture with decoupled modules. In comparison with the state-of-the-art RLlib, we empirically demonstrate the unique advantages of Lamarckian on benchmark tests with up to 6000 CPU cores: i) both the sampling efficiency and training speed are doubled when running PPO on Google football game; ii) the training speed is 13 times faster when running PBT+PPO on Pong game. Moreover, we also present two use cases: i) how Lamarckian is applied to generating behavior-diverse game AI; ii) how Lamarckian is applied to game balancing tests for an asynchronous commercial game.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022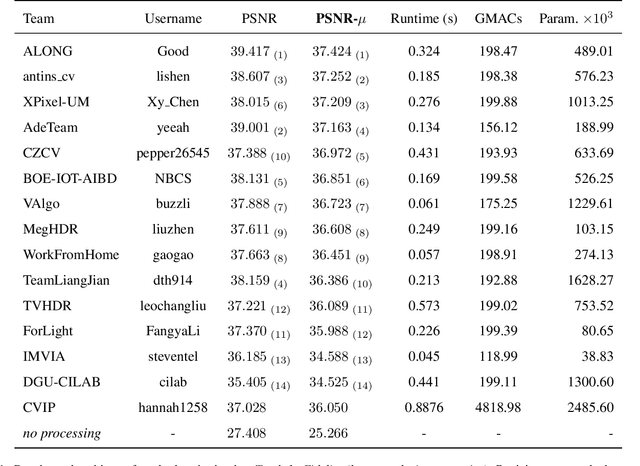
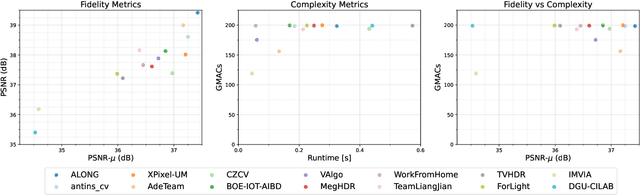
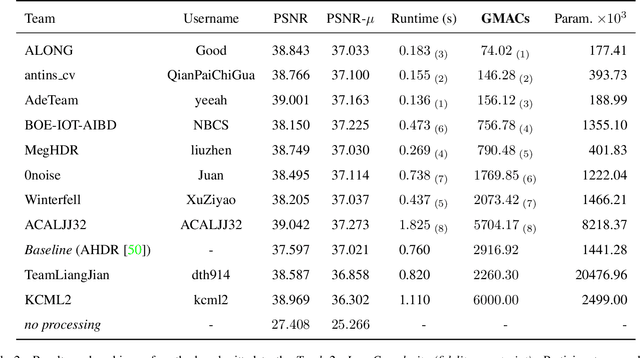
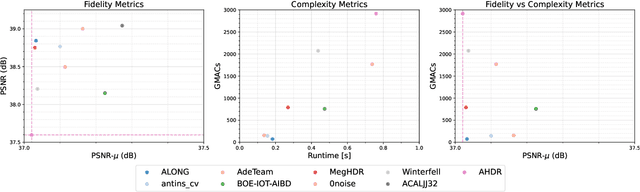
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
PerfectDou: Dominating DouDizhu with Perfect Information Distillation
Apr 05, 2022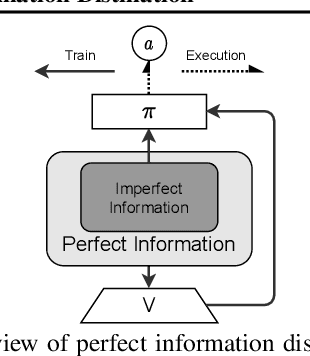

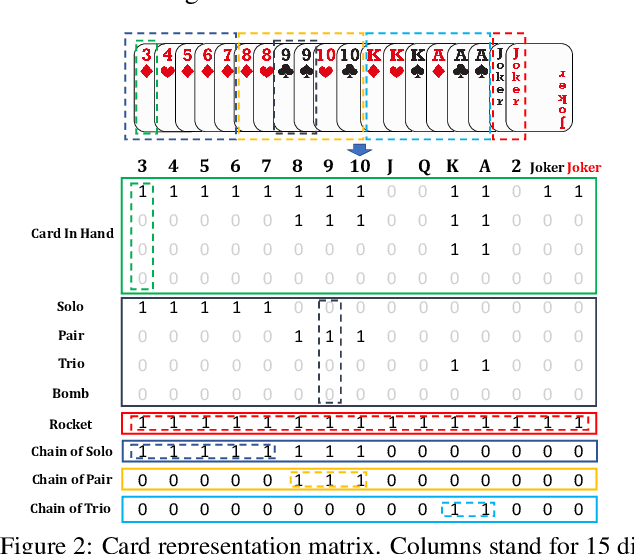
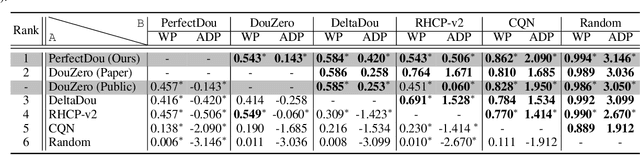
As a challenging multi-player card game, DouDizhu has recently drawn much attention for analyzing competition and collaboration in imperfect-information games. In this paper, we propose PerfectDou, a state-of-the-art DouDizhu AI system that dominates the game, in an actor-critic framework with a proposed technique named perfect information distillation. In detail, we adopt a perfect-training-imperfect-execution framework that allows the agents to utilize the global information to guide the training of the policies as if it is a perfect information game and the trained policies can be used to play the imperfect information game during the actual gameplay. To this end, we characterize card and game features for DouDizhu to represent the perfect and imperfect information. To train our system, we adopt proximal policy optimization with generalized advantage estimation in a parallel training paradigm. In experiments we show how and why PerfectDou beats all existing AI programs, and achieves state-of-the-art performance.
Spatial-Temporal Parallel Transformer for Arm-Hand Dynamic Estimation
Mar 30, 2022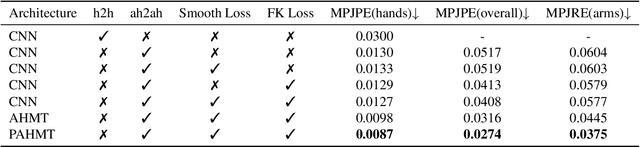
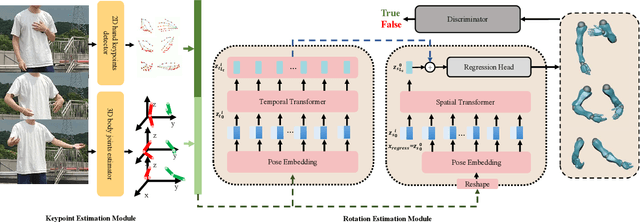

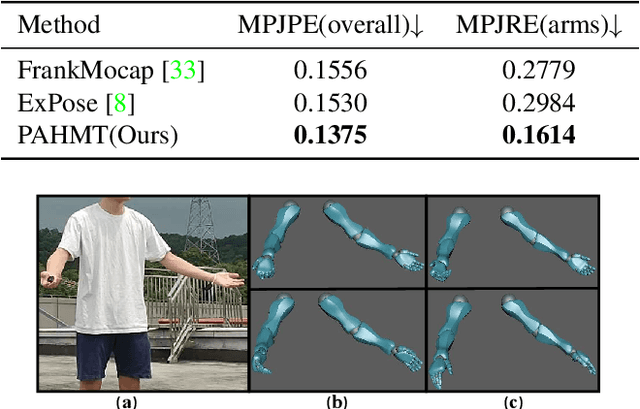
We propose an approach to estimate arm and hand dynamics from monocular video by utilizing the relationship between arm and hand. Although monocular full human motion capture technologies have made great progress in recent years, recovering accurate and plausible arm twists and hand gestures from in-the-wild videos still remains a challenge. To solve this problem, our solution is proposed based on the fact that arm poses and hand gestures are highly correlated in most real situations. To fully exploit arm-hand correlation as well as inter-frame information, we carefully design a Spatial-Temporal Parallel Arm-Hand Motion Transformer (PAHMT) to predict the arm and hand dynamics simultaneously. We also introduce new losses to encourage the estimations to be smooth and accurate. Besides, we collect a motion capture dataset including 200K frames of hand gestures and use this data to train our model. By integrating a 2D hand pose estimation model and a 3D human pose estimation model, the proposed method can produce plausible arm and hand dynamics from monocular video. Extensive evaluations demonstrate that the proposed method has advantages over previous state-of-the-art approaches and shows robustness under various challenging scenarios.
DGC-vector: A new speaker embedding for zero-shot voice conversion
Mar 18, 2022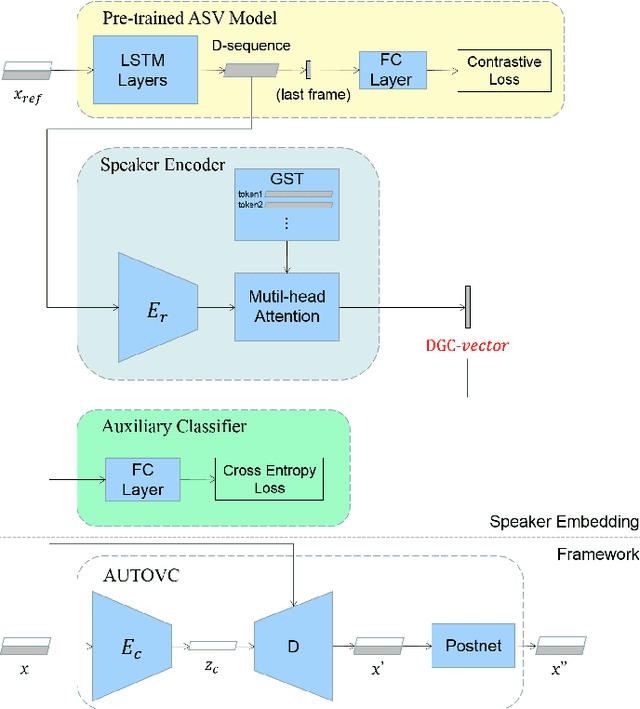
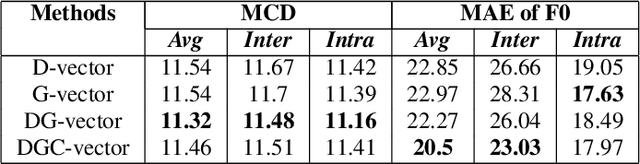
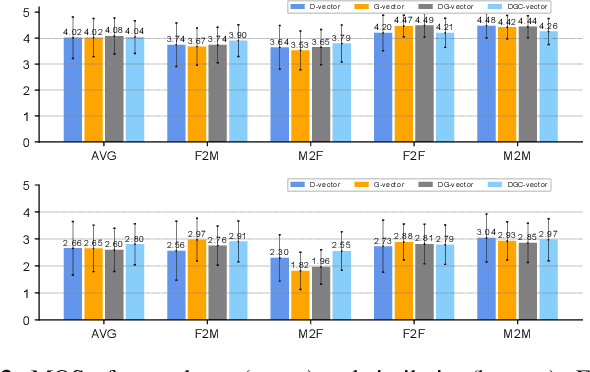
Recently, more and more zero-shot voice conversion algorithms have been proposed. As a fundamental part of zero-shot voice conversion, speaker embeddings are the key to improving the converted speech's speaker similarity. In this paper, we study the impact of speaker embeddings on zero-shot voice conversion performance. To better represent the characteristics of the target speaker and improve the speaker similarity in zero-shot voice conversion, we propose a novel speaker representation method in this paper. Our method combines the advantages of D-vector, global style token (GST) based speaker representation and auxiliary supervision. Objective and subjective evaluations show that the proposed method achieves a decent performance on zero-shot voice conversion and significantly improves speaker similarity over D-vector and GST-based speaker embedding.
Improve few-shot voice cloning using multi-modal learning
Mar 18, 2022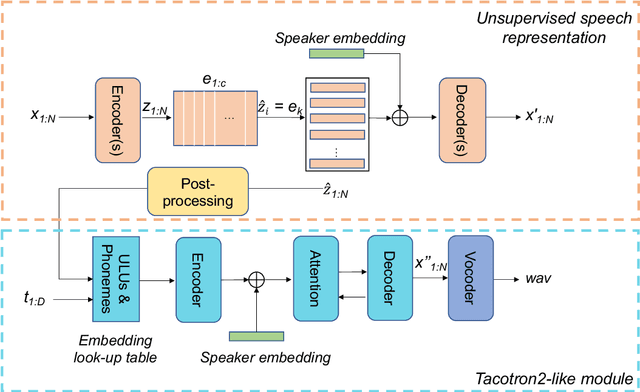
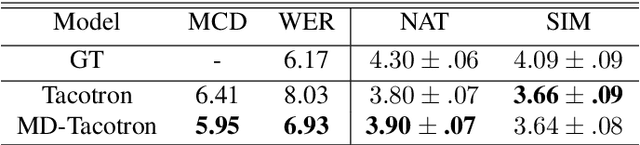
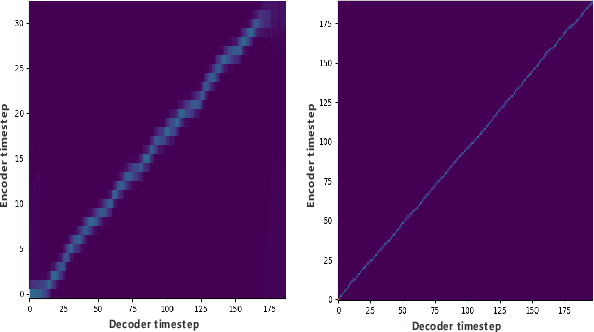

Recently, few-shot voice cloning has achieved a significant improvement. However, most models for few-shot voice cloning are single-modal, and multi-modal few-shot voice cloning has been understudied. In this paper, we propose to use multi-modal learning to improve the few-shot voice cloning performance. Inspired by the recent works on unsupervised speech representation, the proposed multi-modal system is built by extending Tacotron2 with an unsupervised speech representation module. We evaluate our proposed system in two few-shot voice cloning scenarios, namely few-shot text-to-speech(TTS) and voice conversion(VC). Experimental results demonstrate that the proposed multi-modal learning can significantly improve the few-shot voice cloning performance over their counterpart single-modal systems.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022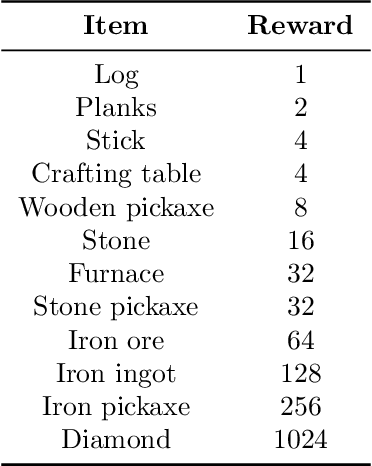
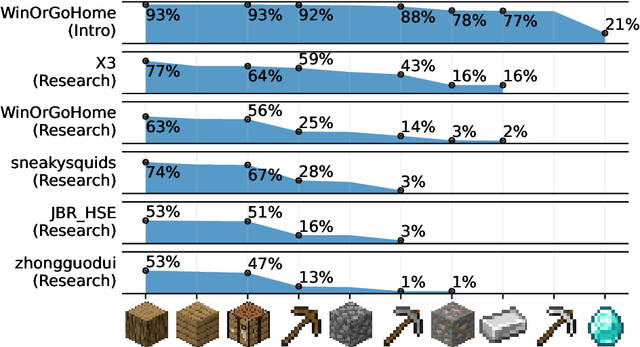
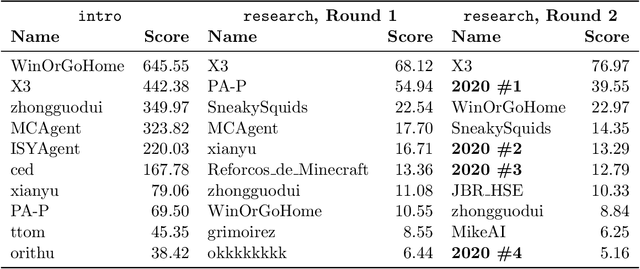
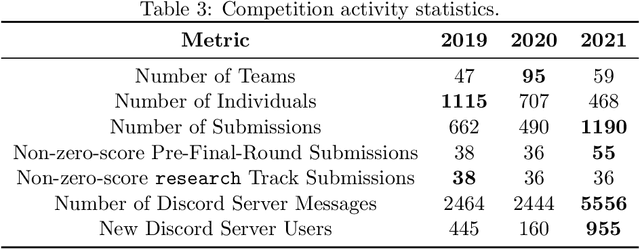
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Revisiting IPA-based Cross-lingual Text-to-speech
Oct 18, 2021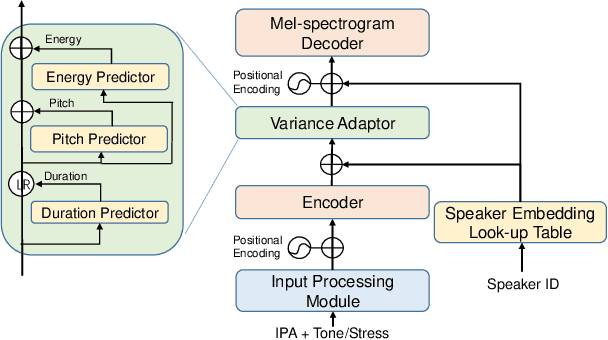
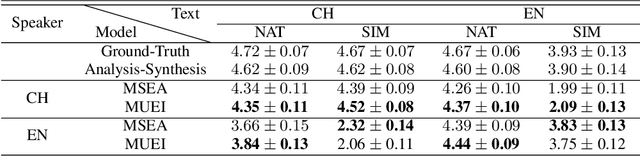
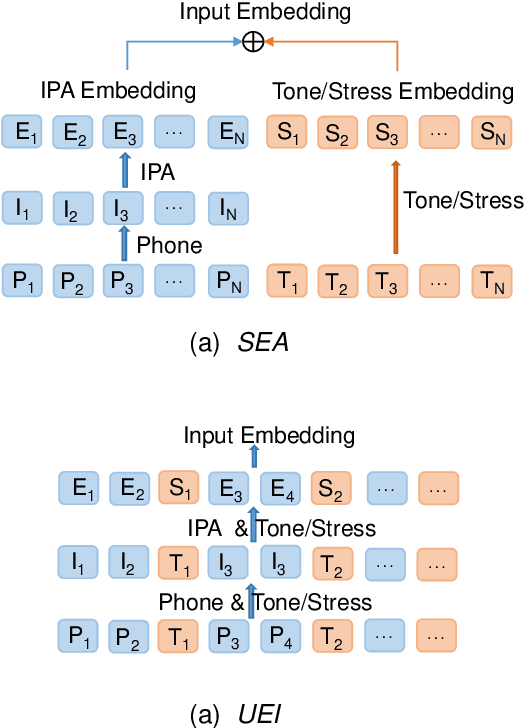
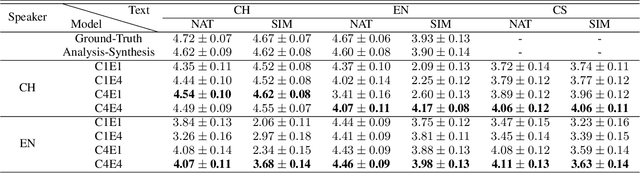
International Phonetic Alphabet (IPA) has been widely used in cross-lingual text-to-speech (TTS) to achieve cross-lingual voice cloning (CL VC). However, IPA itself has been understudied in cross-lingual TTS. In this paper, we report some empirical findings of building a cross-lingual TTS model using IPA as inputs. Experiments show that the way to process the IPA and suprasegmental sequence has a negligible impact on the CL VC performance. Furthermore, we find that using a dataset including one speaker per language to build an IPA-based TTS system would fail CL VC since the language-unique IPA and tone/stress symbols could leak the speaker information. In addition, we experiment with different combinations of speakers in the training dataset to further investigate the effect of the number of speakers on the CL VC performance.
Improve Cross-lingual Voice Cloning Using Low-quality Code-switched Data
Oct 14, 2021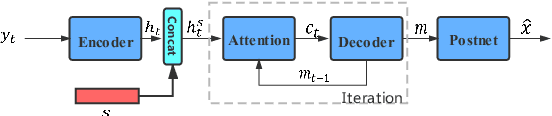
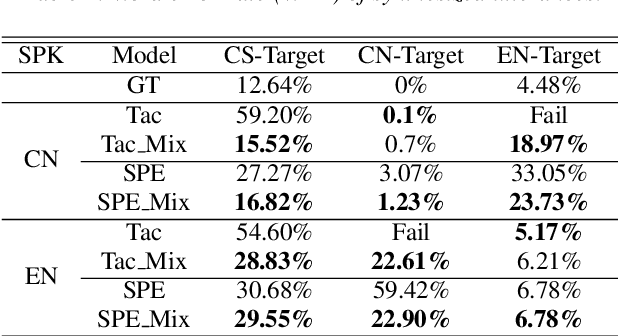
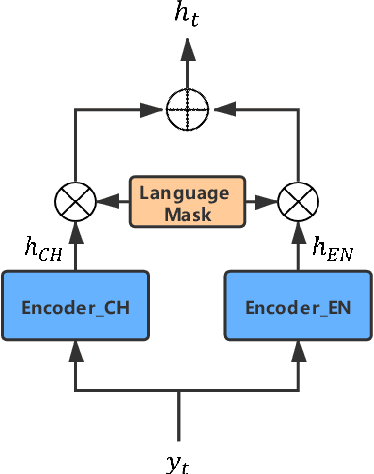
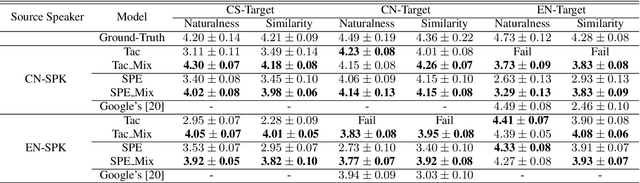
Recently, sequence-to-sequence (seq-to-seq) models have been successfully applied in text-to-speech (TTS) to synthesize speech for single-language text. To synthesize speech for multiple languages usually requires multi-lingual speech from the target speaker. However, it is both laborious and expensive to collect high-quality multi-lingual TTS data for the target speakers. In this paper, we proposed to use low-quality code-switched found data from the non-target speakers to achieve cross-lingual voice cloning for the target speakers. Experiments show that our proposed method can generate high-quality code-switched speech in the target voices in terms of both naturalness and speaker consistency. More importantly, we find that our method can achieve a comparable result to the state-of-the-art (SOTA) performance in cross-lingual voice cloning.