 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision
Apr 01, 2026Existing humanoid table tennis systems remain limited by their reliance on external sensing and their inability to achieve agile whole-body coordination for precise task execution. These limitations stem from two core challenges: achieving low-latency and robust onboard egocentric perception under fast robot motion, and obtaining sufficiently diverse task-aligned strike motions for learning precise yet natural whole-body behaviors. In this work, we present \methodname, a modular system for agile humanoid table tennis that unifies scalable whole-body skill learning with onboard egocentric perception, eliminating the need for external cameras during deployment. Our work advances prior humanoid table-tennis systems in three key aspects. First, we achieve agile and precise ball interaction with tightly coordinated whole-body control, rather than relying on decoupled upper- and lower-body behaviors. This enables the system to exhibit diverse strike motions, including explosive whole-body smashes and low crouching shots. Second, by augmenting and diversifying strike motions with a generative model, our framework benefits from scalable motion priors and produces natural, robust striking behaviors across a wide workspace. Third, to the best of our knowledge, we demonstrate the first humanoid table-tennis system capable of consecutive strikes using onboard sensing alone, despite the challenges of low-latency perception, ego-motion-induced instability, and limited field of view. Extensive real-world experiments demonstrate stable and precise ball exchanges under high-speed conditions, validating scalable, perception-driven whole-body skill learning for dynamic humanoid interaction tasks.
PerfectDou: Dominating DouDizhu with Perfect Information Distillation
Apr 05, 2022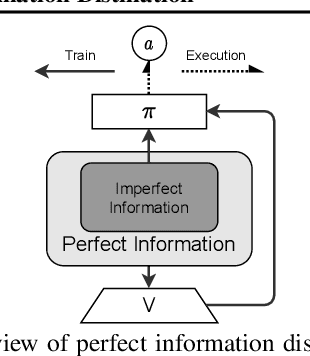

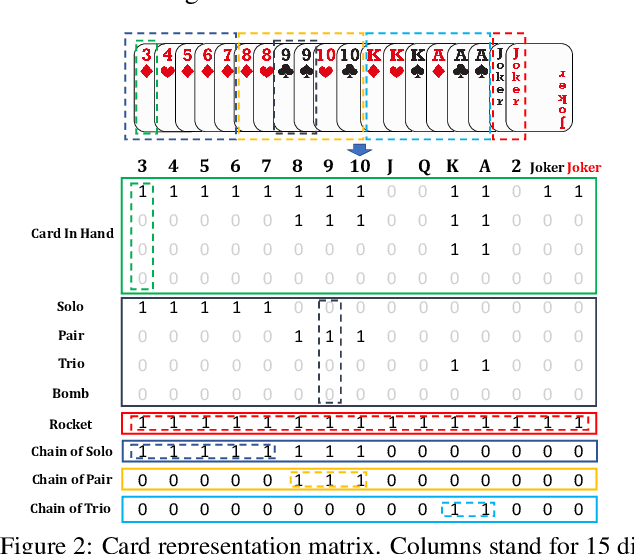
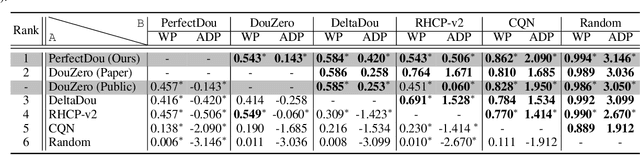
As a challenging multi-player card game, DouDizhu has recently drawn much attention for analyzing competition and collaboration in imperfect-information games. In this paper, we propose PerfectDou, a state-of-the-art DouDizhu AI system that dominates the game, in an actor-critic framework with a proposed technique named perfect information distillation. In detail, we adopt a perfect-training-imperfect-execution framework that allows the agents to utilize the global information to guide the training of the policies as if it is a perfect information game and the trained policies can be used to play the imperfect information game during the actual gameplay. To this end, we characterize card and game features for DouDizhu to represent the perfect and imperfect information. To train our system, we adopt proximal policy optimization with generalized advantage estimation in a parallel training paradigm. In experiments we show how and why PerfectDou beats all existing AI programs, and achieves state-of-the-art performance.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022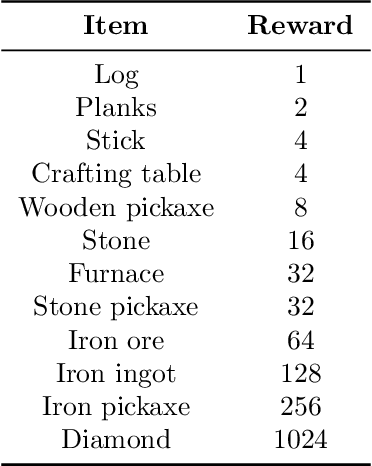
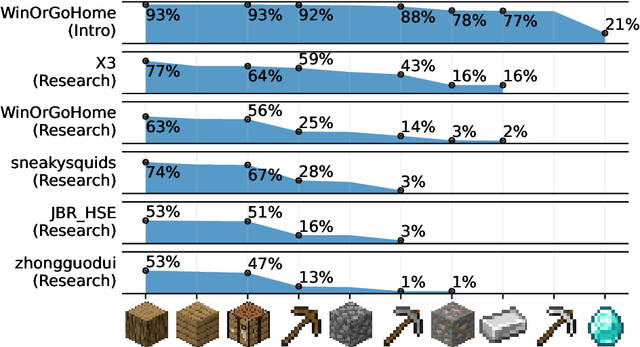
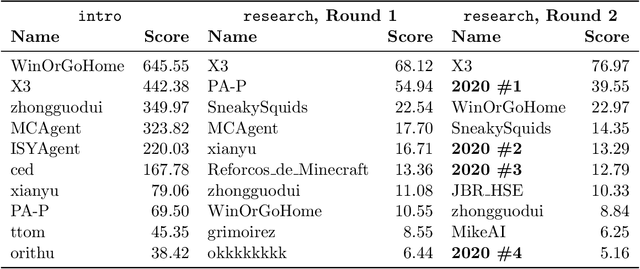
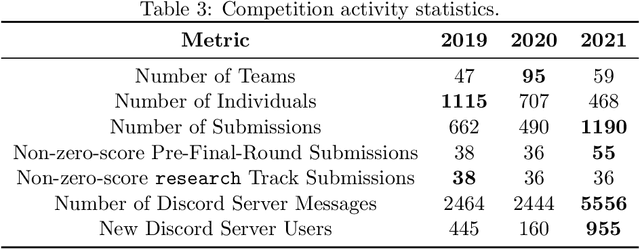
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.