 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSDC-Net: Multi-Scale Dense and Contextual Networks for Automated Disparity Map for Stereo Matching
Apr 30, 2019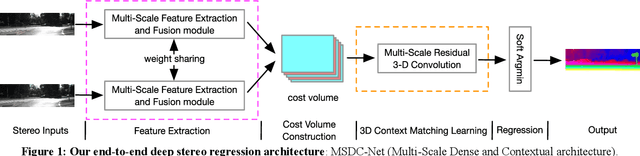

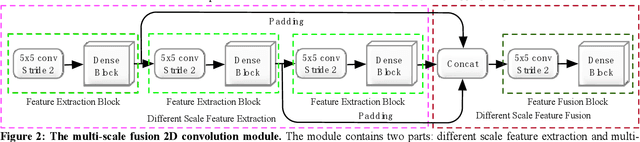
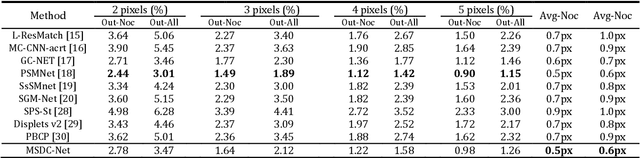
Disparity prediction from stereo images is essential to computer vision applications including autonomous driving, 3D model reconstruction, and object detection. To predict accurate disparity map, we propose a novel deep learning architecture for detectingthe disparity map from a rectified pair of stereo images, called MSDC-Net. Our MSDC-Net contains two modules: multi-scale fusion 2D convolution and multi-scale residual 3D convolution modules. The multi-scale fusion 2D convolution module exploits the potential multi-scale features, which extracts and fuses the different scale features by Dense-Net. The multi-scale residual 3D convolution module learns the different scale geometry context from the cost volume which aggregated by the multi-scale fusion 2D convolution module. Experimental results on Scene Flow and KITTI datasets demonstrate that our MSDC-Net significantly outperforms other approaches in the non-occluded region.
Noise-Aware Unsupervised Deep Lidar-Stereo Fusion
Apr 08, 2019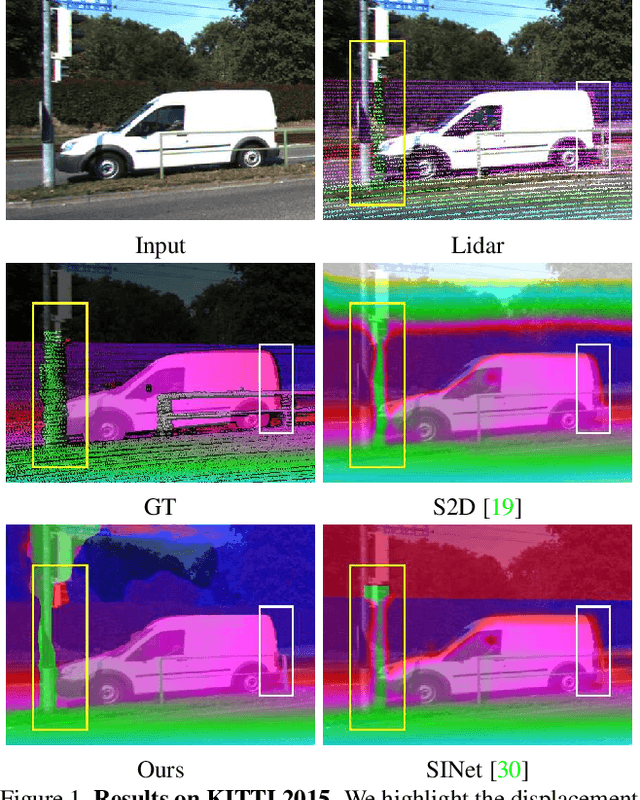

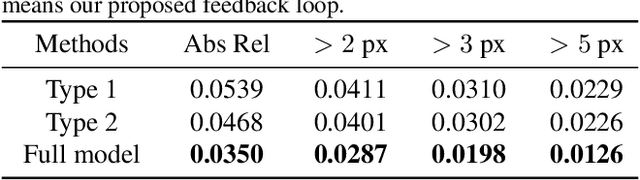
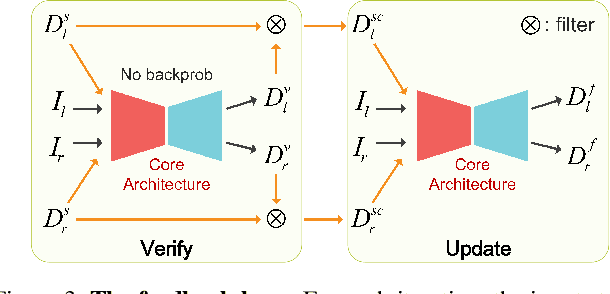
In this paper, we present LidarStereoNet, the first unsupervised Lidar-stereo fusion network, which can be trained in an end-to-end manner without the need of ground truth depth maps. By introducing a novel "Feedback Loop'' to connect the network input with output, LidarStereoNet could tackle both noisy Lidar points and misalignment between sensors that have been ignored in existing Lidar-stereo fusion studies. Besides, we propose to incorporate a piecewise planar model into network learning to further constrain depths to conform to the underlying 3D geometry. Extensive quantitative and qualitative evaluations on both real and synthetic datasets demonstrate the superiority of our method, which outperforms state-of-the-art stereo matching, depth completion and Lidar-Stereo fusion approaches significantly.
Unsupervised Deep Epipolar Flow for Stationary or Dynamic Scenes
Apr 08, 2019
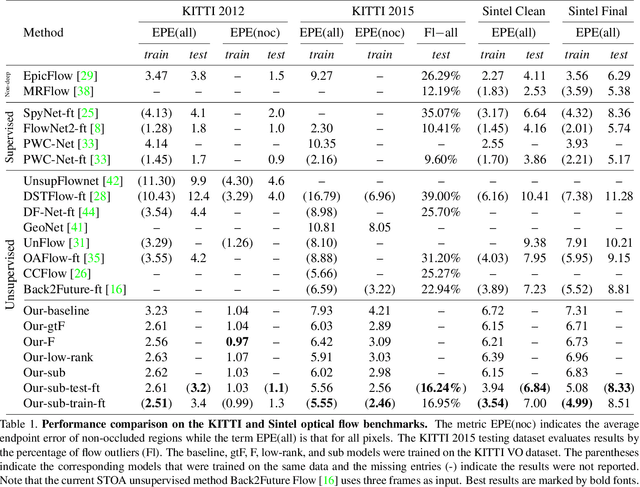

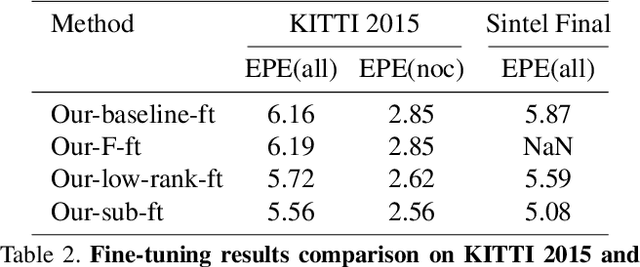
Unsupervised deep learning for optical flow computation has achieved promising results. Most existing deep-net based methods rely on image brightness consistency and local smoothness constraint to train the networks. Their performance degrades at regions where repetitive textures or occlusions occur. In this paper, we propose Deep Epipolar Flow, an unsupervised optical flow method which incorporates global geometric constraints into network learning. In particular, we investigate multiple ways of enforcing the epipolar constraint in flow estimation. To alleviate a ``chicken-and-egg'' type of problem encountered in dynamic scenes where multiple motions may be present, we propose a low-rank constraint as well as a union-of-subspaces constraint for training. Experimental results on various benchmarking datasets show that our method achieves competitive performance compared with supervised methods and outperforms state-of-the-art unsupervised deep-learning methods.
Deep Stacked Hierarchical Multi-patch Network for Image Deblurring
Apr 06, 2019


Despite deep end-to-end learning methods have shown their superiority in removing non-uniform motion blur, there still exist major challenges with the current multi-scale and scale-recurrent models: 1) Deconvolution/upsampling operations in the coarse-to-fine scheme result in expensive runtime; 2) Simply increasing the model depth with finer-scale levels cannot improve the quality of deblurring. To tackle the above problems, we present a deep hierarchical multi-patch network inspired by Spatial Pyramid Matching to deal with blurry images via a fine-to-coarse hierarchical representation. To deal with the performance saturation w.r.t. depth, we propose a stacked version of our multi-patch model. Our proposed basic multi-patch model achieves the state-of-the-art performance on the GoPro dataset while enjoying a 40x faster runtime compared to current multi-scale methods. With 30ms to process an image at 1280x720 resolution, it is the first real-time deep motion deblurring model for 720p images at 30fps. For stacked networks, significant improvements (over 1.2dB) are achieved on the GoPro dataset by increasing the network depth. Moreover, by varying the depth of the stacked model, one can adapt the performance and runtime of the same network for different application scenarios.
Dense Depth Estimation of a Complex Dynamic Scene without Explicit 3D Motion Estimation
Mar 23, 2019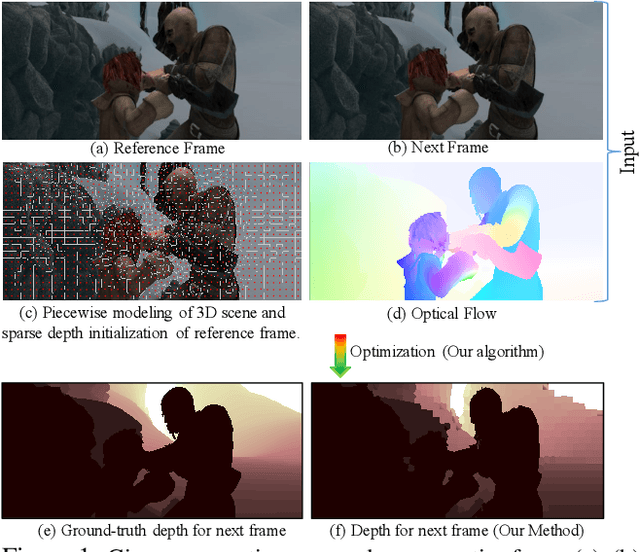
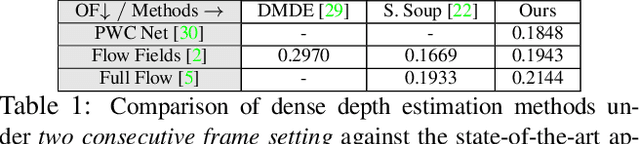
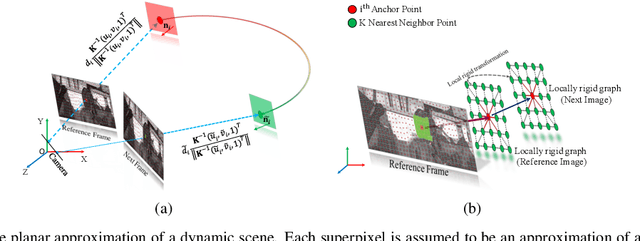
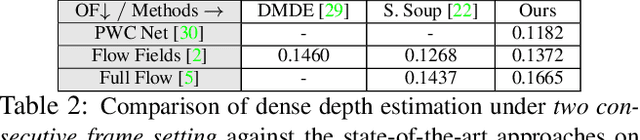
Recent geometric methods need reliable estimates of 3D motion parameters to procure accurate dense depth map of a complex dynamic scene from monocular images \cite{kumar2017monocular, ranftl2016dense}. Generally, to estimate \textbf{precise} measurements of relative 3D motion parameters and to validate its accuracy using image data is a challenging task. In this work, we propose an alternative approach that circumvents the 3D motion estimation requirement to obtain a dense depth map of a dynamic scene. Given per-pixel optical flow correspondences between two consecutive frames and, the sparse depth prior for the reference frame, we show that, we can effectively recover the dense depth map for the successive frames without solving for 3D motion parameters. Our method assumes a piece-wise planar model of a dynamic scene, which undergoes rigid transformation locally, and as-rigid-as-possible transformation globally between two successive frames. Under our assumption, we can avoid the explicit estimation of 3D rotation and translation to estimate scene depth. In essence, our formulation provides an unconventional way to think and recover the dense depth map of a complex dynamic scene which is incremental and motion free in nature. Our proposed method does not make object level or any other high-level prior assumption about the dynamic scene, as a result, it is applicable to a wide range of scenarios. Experimental results on the benchmarks dataset show the competence of our approach for multiple frames.
Bringing Blurry Alive at High Frame-Rate with an Event Camera
Mar 12, 2019
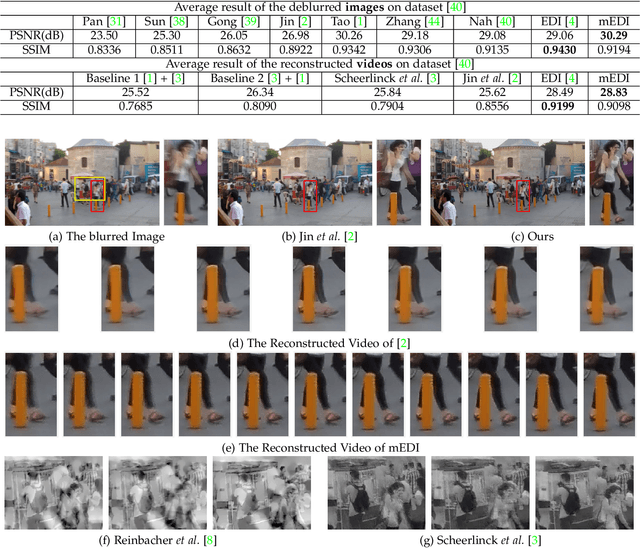
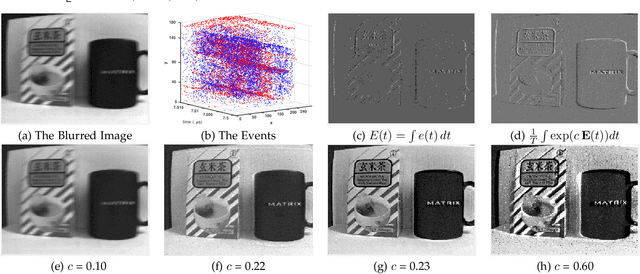

Event-based cameras can measure intensity changes (called `{\it events}') with microsecond accuracy under high-speed motion and challenging lighting conditions. With the active pixel sensor (APS), the event camera allows simultaneous output of the intensity frames. However, the output images are captured at a relatively low frame-rate and often suffer from motion blur. A blurry image can be regarded as the integral of a sequence of latent images, while the events indicate the changes between the latent images. Therefore, we are able to model the blur-generation process by associating event data to a latent image. Based on the abundant event data and the low frame-rate easily blurred images, we propose a simple and effective approach to reconstruct a high-quality and high frame-rate shape video. Starting with a single blurry frame and its event data, we propose the \textbf{Event-based Double Integral (EDI)} model. Then, we extend it to \textbf{ multiple Event-based Double Integral (mEDI)} model to get more smooth and convincing results based on multiple images and their events. We also provide an efficient solver to minimize the proposed energy model. By optimizing the energy model, we achieve significant improvements in removing general blurs and reconstructing high temporal resolution video. The video generation is based on solving a simple non-convex optimization problem in a single scalar variable. Experimental results on both synthetic and real images demonstrate the superiority of our mEDI model and optimization method in comparison to the state-of-the-art.
Ground Plane based Absolute Scale Estimation for Monocular Visual Odometry
Mar 03, 2019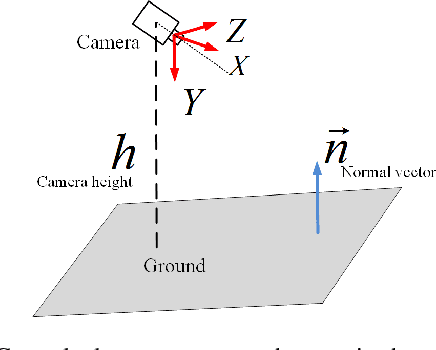
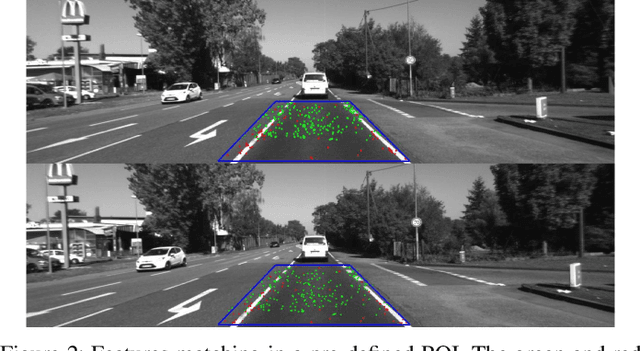
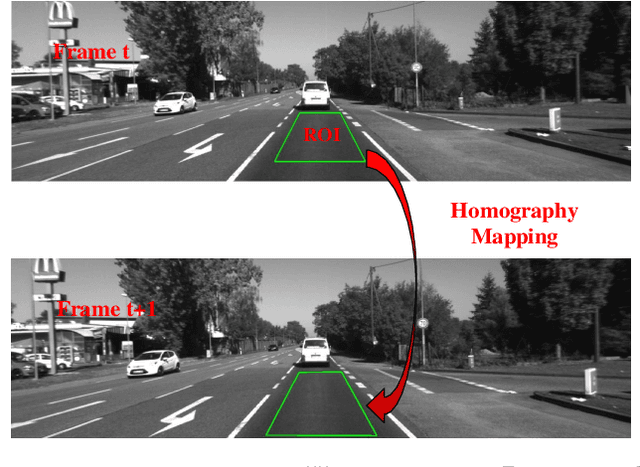

Recovering the absolute metric scale from a monocular camera is a challenging but highly desirable problem for monocular camera-based systems. By using different kinds of cues, various approaches have been proposed for scale estimation, such as camera height, object size etc. In this paper, firstly, we summarize different kinds of scale estimation approaches. Then, we propose a robust divide and conquer the absolute scale estimation method based on the ground plane and camera height by analyzing the advantages and disadvantages of different approaches. By using the estimated scale, an effective scale correction strategy has been proposed to reduce the scale drift during the Monocular Visual Odometry (VO) estimation process. Finally, the effectiveness and robustness of the proposed method have been verified on both public and self-collected image sequences.
Single Image Deblurring and Camera Motion Estimation with Depth Map
Mar 01, 2019
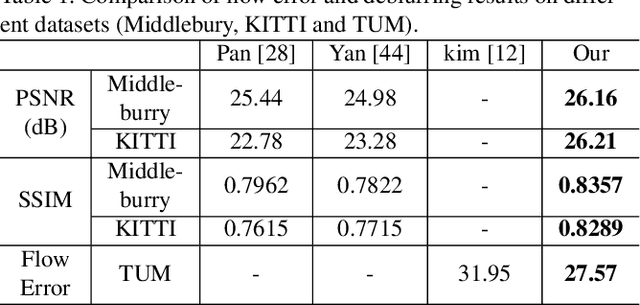
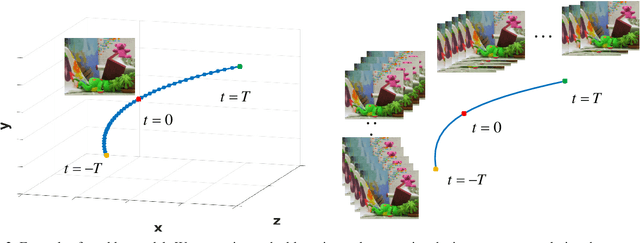

Camera shake during exposure is a major problem in hand-held photography, as it causes image blur that destroys details in the captured images.~In the real world, such blur is mainly caused by both the camera motion and the complex scene structure.~While considerable existing approaches have been proposed based on various assumptions regarding the scene structure or the camera motion, few existing methods could handle the real 6 DoF camera motion.~In this paper, we propose to jointly estimate the 6 DoF camera motion and remove the non-uniform blur caused by camera motion by exploiting their underlying geometric relationships, with a single blurry image and its depth map (either direct depth measurements, or a learned depth map) as input.~We formulate our joint deblurring and 6 DoF camera motion estimation as an energy minimization problem which is solved in an alternative manner. Our model enables the recovery of the 6 DoF camera motion and the latent clean image, which could also achieve the goal of generating a sharp sequence from a single blurry image. Experiments on challenging real-world and synthetic datasets demonstrate that image blur from camera shake can be well addressed within our proposed framework.
ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving
Nov 30, 2018

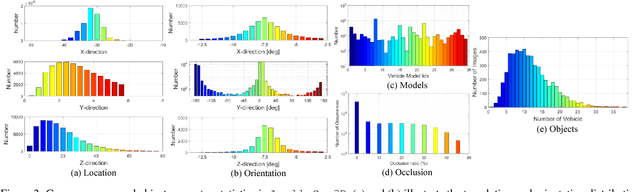
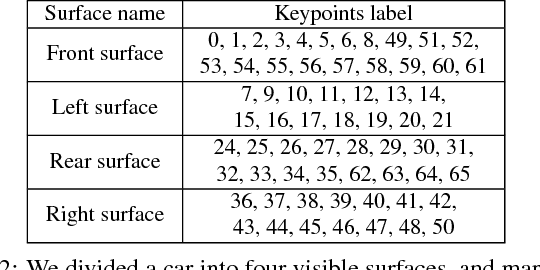
Autonomous driving has attracted remarkable attention from both industry and academia. An important task is to estimate 3D properties(e.g.translation, rotation and shape) of a moving or parked vehicle on the road. This task, while critical, is still under-researched in the computer vision community - partially owing to the lack of large scale and fully-annotated 3D car database suitable for autonomous driving research. In this paper, we contribute the first large-scale database suitable for 3D car instance understanding - ApolloCar3D. The dataset contains 5,277 driving images and over 60K car instances, where each car is fitted with an industry-grade 3D CAD model with absolute model size and semantically labelled keypoints. This dataset is above 20 times larger than PASCAL3D+ and KITTI, the current state-of-the-art. To enable efficient labelling in 3D, we build a pipeline by considering 2D-3D keypoint correspondences for a single instance and 3D relationship among multiple instances. Equipped with such dataset, we build various baseline algorithms with the state-of-the-art deep convolutional neural networks. Specifically, we first segment each car with a pre-trained Mask R-CNN, and then regress towards its 3D pose and shape based on a deformable 3D car model with or without using semantic keypoints. We show that using keypoints significantly improves fitting performance. Finally, we develop a new 3D metric jointly considering 3D pose and 3D shape, allowing for comprehensive evaluation and ablation study. By comparing with human performance we suggest several future directions for further improvements.
Bringing a Blurry Frame Alive at High Frame-Rate with an Event Camera
Nov 27, 2018
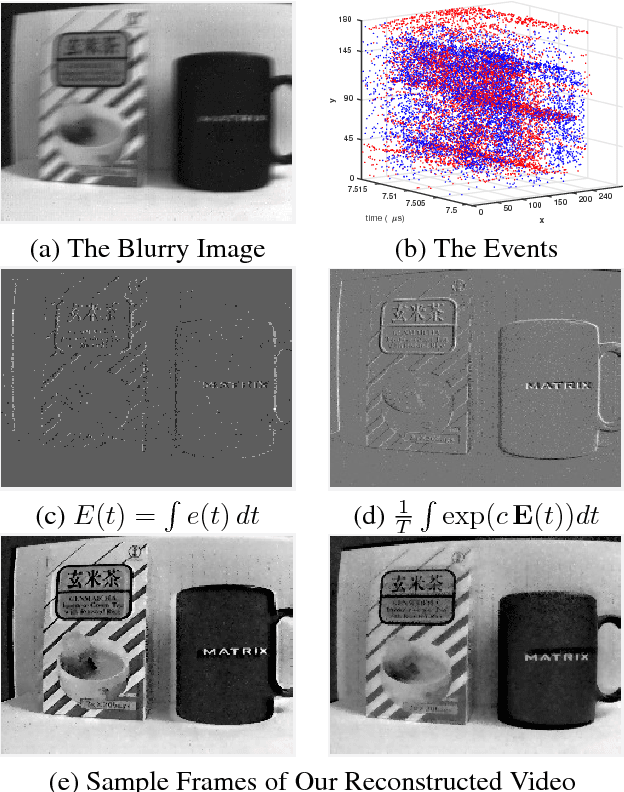
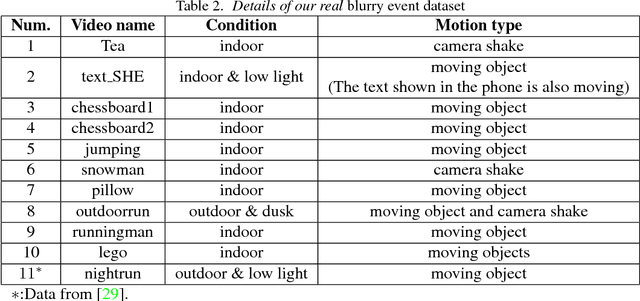

Event-based cameras can measure intensity changes (called `{\it events}') with microsecond accuracy under high-speed motion and challenging lighting conditions. With the active pixel sensor (APS), the event camera allows simultaneous output of the intensity frames. However, the output images are captured at a relatively low frame-rate and often suffer from motion blur. A blurry image can be regarded as the integral of a sequence of latent images, while the events indicate the changes between the latent images. Therefore, we are able to model the blur-generation process by associating event data to a latent image. In this paper, we propose a simple and effective approach, the \textbf{Event-based Double Integral (EDI)} model, to reconstruct a high frame-rate, sharp video from a single blurry frame and its event data. The video generation is based on solving a simple non-convex optimization problem in a single scalar variable. Experimental results on both synthetic and real images demonstrate the superiority of our EDI model and optimization method in comparison to the state-of-the-art.