 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Aided Data Augmentation for Robust Face Understanding
Oct 06, 2020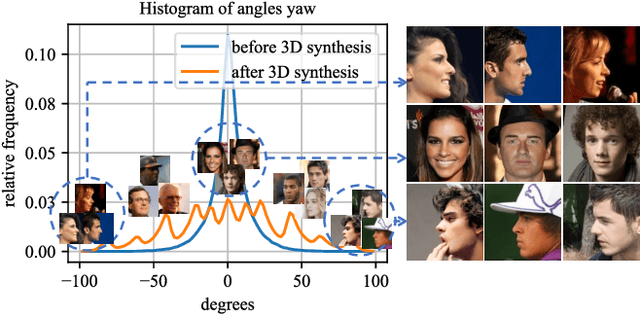

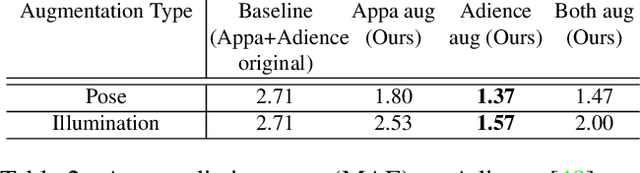
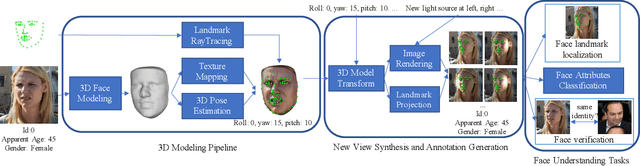
Data augmentation has been highly effective in narrowing the data gap and reducing the cost for human annotation, especially for tasks where ground truth labels are difficult and expensive to acquire. In face recognition, large pose and illumination variation of face images has been a key factor for performance degradation. However, human annotation for the various face understanding tasks including face landmark localization, face attributes classification and face recognition under these challenging scenarios are highly costly to acquire. Therefore, it would be desirable to perform data augmentation for these cases. But simple 2D data augmentation techniques on the image domain are not able to satisfy the requirement of these challenging cases. As such, 3D face modeling, in particular, single image 3D face modeling, stands a feasible solution for these challenging conditions beyond 2D based data augmentation. To this end, we propose a method that produces realistic 3D augmented images from multiple viewpoints with different illumination conditions through 3D face modeling, each associated with geometrically accurate face landmarks, attributes and identity information. Experiments demonstrate that the proposed 3D data augmentation method significantly improves the performance and robustness of various face understanding tasks while achieving state-of-arts on multiple benchmarks.
Towards causal benchmarking of bias in face analysis algorithms
Jul 13, 2020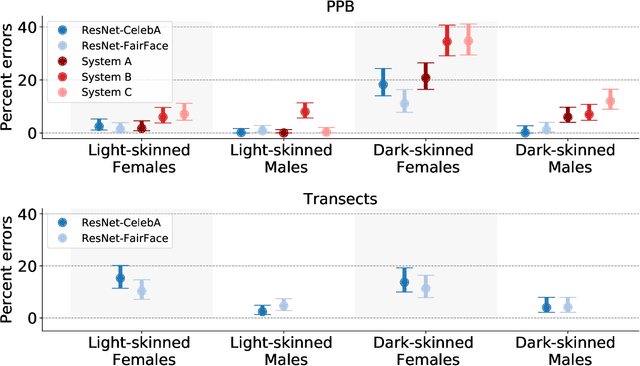
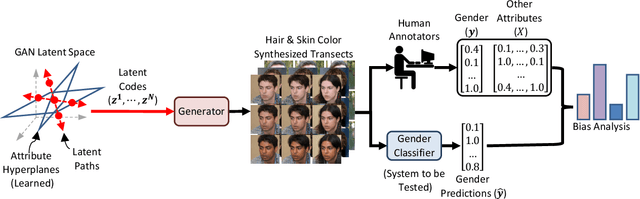


Measuring algorithmic bias is crucial both to assess algorithmic fairness, and to guide the improvement of algorithms. Current methods to measure algorithmic bias in computer vision, which are based on observational datasets, are inadequate for this task because they conflate algorithmic bias with dataset bias. To address this problem we develop an experimental method for measuring algorithmic bias of face analysis algorithms, which manipulates directly the attributes of interest, e.g., gender and skin tone, in order to reveal causal links between attribute variation and performance change. Our proposed method is based on generating synthetic ``transects'' of matched sample images that are designed to differ along specific attributes while leaving other attributes constant. A crucial aspect of our approach is relying on the perception of human observers, both to guide manipulations, and to measure algorithmic bias. Besides allowing the measurement of algorithmic bias, synthetic transects have other advantages with respect to observational datasets: they sample attributes more evenly allowing for more straightforward bias analysis on minority and intersectional groups, they enable prediction of bias in new scenarios, they greatly reduce ethical and legal challenges, and they are economical and fast to obtain, helping make bias testing affordable and widely available. We validate our method by comparing it to a study that employs the traditional observational method for analyzing bias in gender classification algorithms. The two methods reach different conclusions. While the observational method reports gender and skin color biases, the experimental method reveals biases due to gender, hair length, age, and facial hair.
On Improving Temporal Consistency for Online Face Liveness Detection
Jun 11, 2020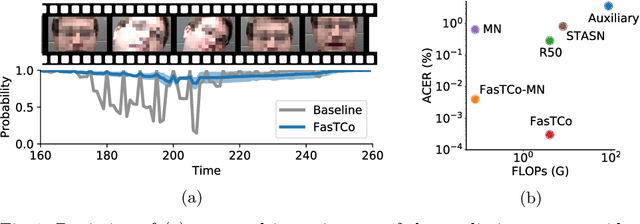
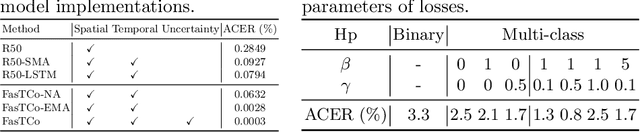
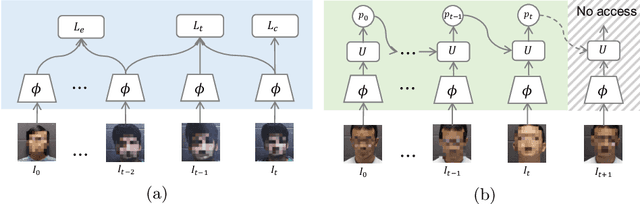

In this paper, we focus on improving the online face liveness detection system to enhance the security of the downstream face recognition system. Most of the existing frame-based methods are suffering from the prediction inconsistency across time. To address the issue, a simple yet effective solution based on temporal consistency is proposed. Specifically, in the training stage, to integrate the temporal consistency constraint, a temporal self-supervision loss and a class consistency loss are proposed in addition to the softmax cross-entropy loss. In the deployment stage, a training-free non-parametric uncertainty estimation module is developed to smooth the predictions adaptively. Beyond the common evaluation approach, a video segment-based evaluation is proposed to accommodate more practical scenarios. Extensive experiments demonstrated that our solution is more robust against several presentation attacks in various scenarios, and significantly outperformed the state-of-the-art on multiple public datasets by at least 40% in terms of ACER. Besides, with much less computational complexity (33% fewer FLOPs), it provides great potential for low-latency online applications.
Motion Guided 3D Pose Estimation from Videos
Apr 29, 2020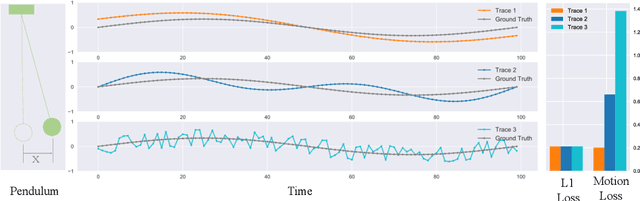



We propose a new loss function, called motion loss, for the problem of monocular 3D Human pose estimation from 2D pose. In computing motion loss, a simple yet effective representation for keypoint motion, called pairwise motion encoding, is introduced. We design a new graph convolutional network architecture, U-shaped GCN (UGCN). It captures both short-term and long-term motion information to fully leverage the additional supervision from the motion loss. We experiment training UGCN with the motion loss on two large scale benchmarks: Human3.6M and MPI-INF-3DHP. Our model surpasses other state-of-the-art models by a large margin. It also demonstrates strong capacity in producing smooth 3D sequences and recovering keypoint motion.
Omni-sourced Webly-supervised Learning for Video Recognition
Mar 29, 2020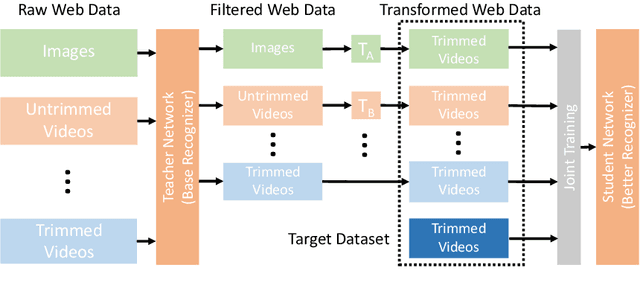

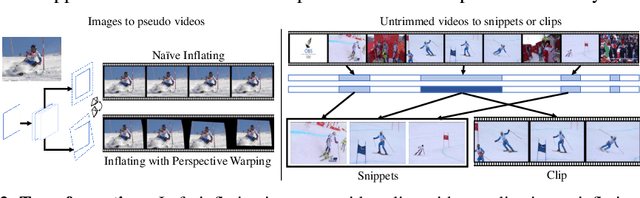

We introduce OmniSource, a novel framework for leveraging web data to train video recognition models. OmniSource overcomes the barriers between data formats, such as images, short videos, and long untrimmed videos for webly-supervised learning. First, data samples with multiple formats, curated by task-specific data collection and automatically filtered by a teacher model, are transformed into a unified form. Then a joint-training strategy is proposed to deal with the domain gaps between multiple data sources and formats in webly-supervised learning. Several good practices, including data balancing, resampling, and cross-dataset mixup are adopted in joint training. Experiments show that by utilizing data from multiple sources and formats, OmniSource is more data-efficient in training. With only 3.5M images and 800K minutes videos crawled from the internet without human labeling (less than 2% of prior works), our models learned with OmniSource improve Top-1 accuracy of 2D- and 3D-ConvNet baseline models by 3.0% and 3.9%, respectively, on the Kinetics-400 benchmark. With OmniSource, we establish new records with different pretraining strategies for video recognition. Our best models achieve 80.4%, 80.5%, and 83.6 Top-1 accuracies on the Kinetics-400 benchmark respectively for training-from-scratch, ImageNet pre-training and IG-65M pre-training.
Towards Backward-Compatible Representation Learning
Mar 29, 2020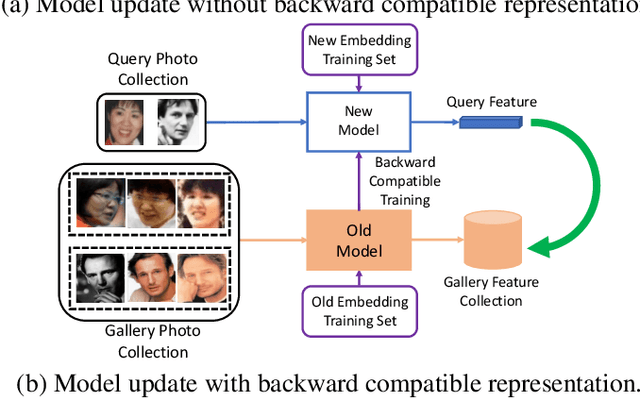
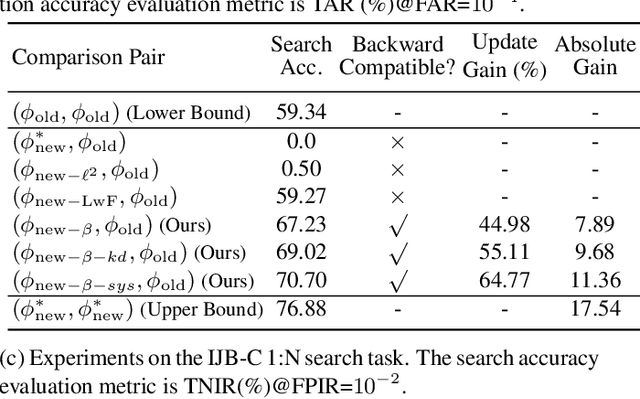

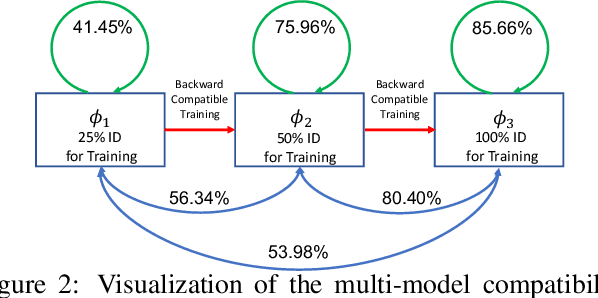
We propose a way to learn visual features that are compatible with previously computed ones even when they have different dimensions and are learned via different neural network architectures and loss functions. Compatible means that, if such features are used to compare images, then "new" features can be compared directly to "old" features, so they can be used interchangeably. This enables visual search systems to bypass computing new features for all previously seen images when updating the embedding models, a process known as backfilling. Backward compatibility is critical to quickly deploy new embedding models that leverage ever-growing large-scale training datasets and improvements in deep learning architectures and training methods. We propose a framework to train embedding models, called backward-compatible training (BCT), as a first step towards backward compatible representation learning. In experiments on learning embeddings for face recognition, models trained with BCT successfully achieve backward compatibility without sacrificing accuracy, thus enabling backfill-free model updates of visual embeddings.
Action recognition with spatial-temporal discriminative filter banks
Aug 20, 2019
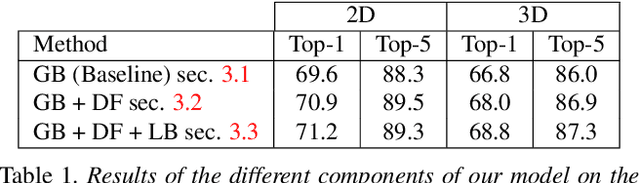
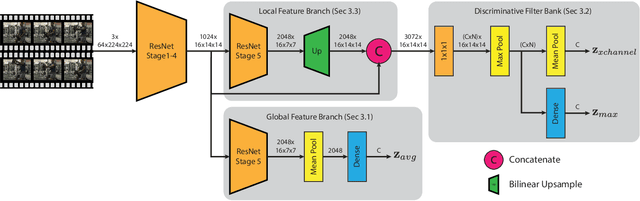

Action recognition has seen a dramatic performance improvement in the last few years. Most of the current state-of-the-art literature either aims at improving performance through changes to the backbone CNN network, or they explore different trade-offs between computational efficiency and performance, again through altering the backbone network. However, almost all of these works maintain the same last layers of the network, which simply consist of a global average pooling followed by a fully connected layer. In this work we focus on how to improve the representation capacity of the network, but rather than altering the backbone, we focus on improving the last layers of the network, where changes have low impact in terms of computational cost. In particular, we show that current architectures have poor sensitivity to finer details and we exploit recent advances in the fine-grained recognition literature to improve our model in this aspect. With the proposed approach, we obtain state-of-the-art performance on Kinetics-400 and Something-Something-V1, the two major large-scale action recognition benchmarks.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019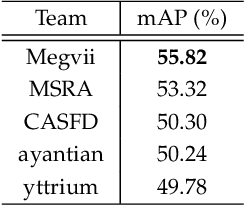

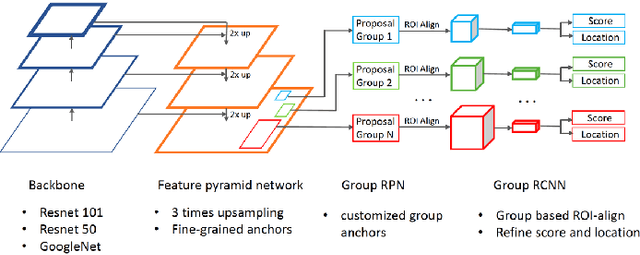
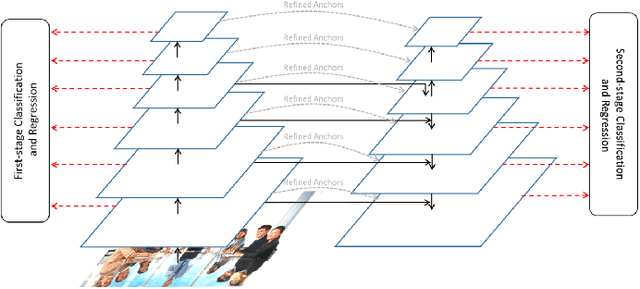
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
From Trailers to Storylines: An Efficient Way to Learn from Movies
Jun 14, 2018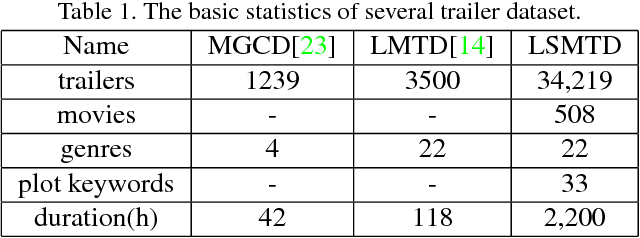

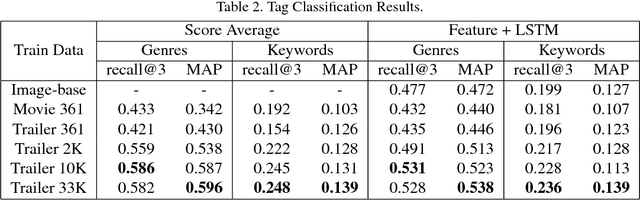
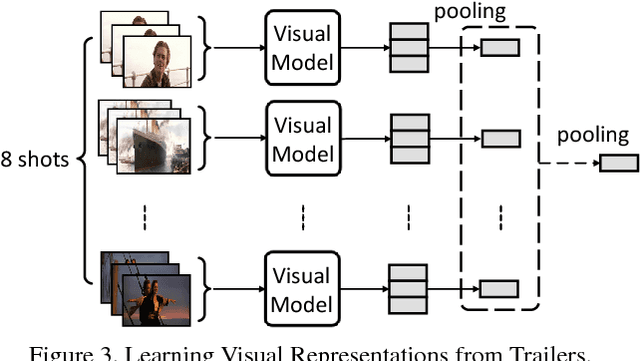
The millions of movies produced in the human history are valuable resources for computer vision research. However, learning a vision model from movie data would meet with serious difficulties. A major obstacle is the computational cost -- the length of a movie is often over one hour, which is substantially longer than the short video clips that previous study mostly focuses on. In this paper, we explore an alternative approach to learning vision models from movies. Specifically, we consider a framework comprised of a visual module and a temporal analysis module. Unlike conventional learning methods, the proposed approach learns these modules from different sets of data -- the former from trailers while the latter from movies. This allows distinctive visual features to be learned within a reasonable budget while still preserving long-term temporal structures across an entire movie. We construct a large-scale dataset for this study and define a series of tasks on top. Experiments on this dataset showed that the proposed method can substantially reduce the training time while obtaining highly effective features and coherent temporal structures.
Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination
May 05, 2018
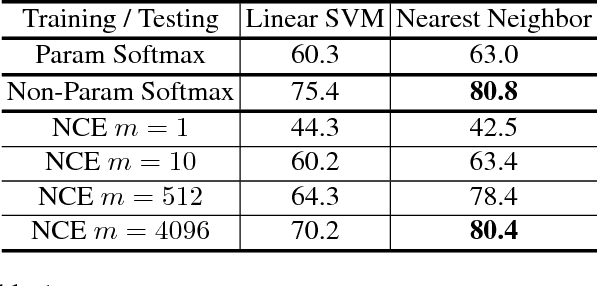
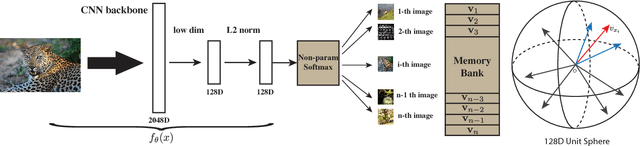
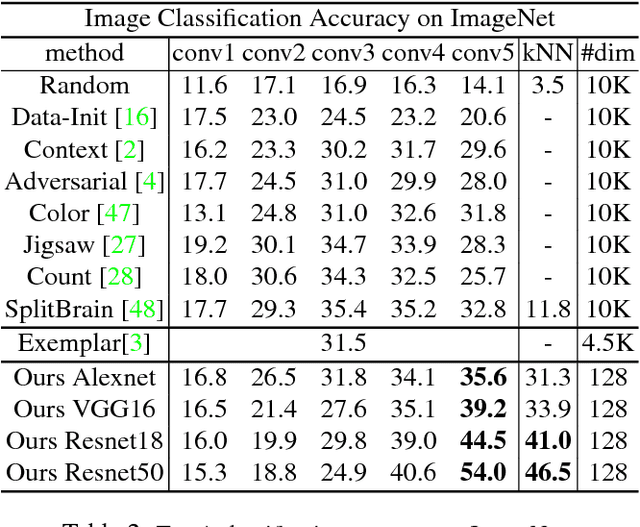
Neural net classifiers trained on data with annotated class labels can also capture apparent visual similarity among categories without being directed to do so. We study whether this observation can be extended beyond the conventional domain of supervised learning: Can we learn a good feature representation that captures apparent similarity among instances, instead of classes, by merely asking the feature to be discriminative of individual instances? We formulate this intuition as a non-parametric classification problem at the instance-level, and use noise-contrastive estimation to tackle the computational challenges imposed by the large number of instance classes. Our experimental results demonstrate that, under unsupervised learning settings, our method surpasses the state-of-the-art on ImageNet classification by a large margin. Our method is also remarkable for consistently improving test performance with more training data and better network architectures. By fine-tuning the learned feature, we further obtain competitive results for semi-supervised learning and object detection tasks. Our non-parametric model is highly compact: With 128 features per image, our method requires only 600MB storage for a million images, enabling fast nearest neighbour retrieval at the run time.