 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
ARAC: Adaptive Regularized Multi-Agent Soft Actor-Critic in Graph-Structured Adversarial Games
Nov 11, 2025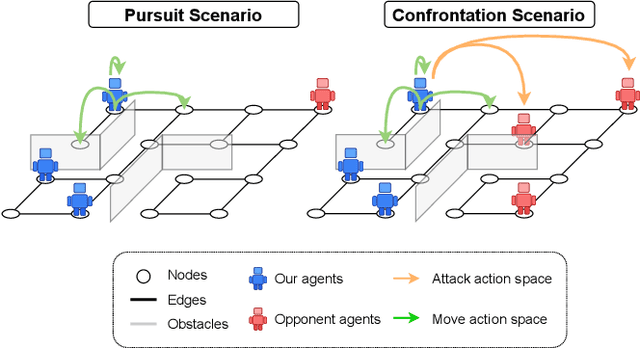
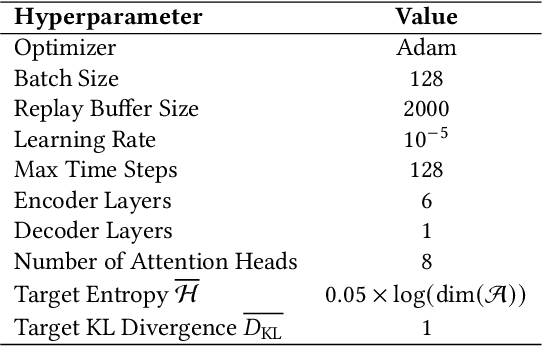
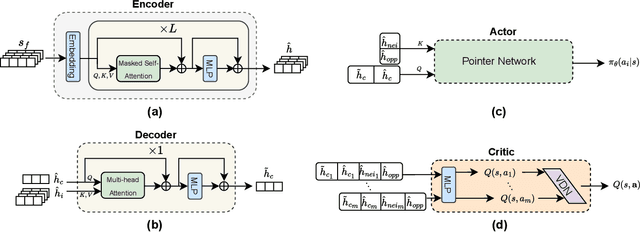
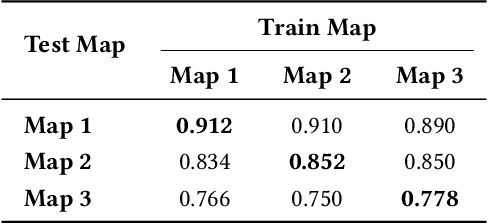
In graph-structured multi-agent reinforcement learning (MARL) adversarial tasks such as pursuit and confrontation, agents must coordinate under highly dynamic interactions, where sparse rewards hinder efficient policy learning. We propose Adaptive Regularized Multi-Agent Soft Actor-Critic (ARAC), which integrates an attention-based graph neural network (GNN) for modeling agent dependencies with an adaptive divergence regularization mechanism. The GNN enables expressive representation of spatial relations and state features in graph environments. Divergence regularization can serve as policy guidance to alleviate the sparse reward problem, but it may lead to suboptimal convergence when the reference policy itself is imperfect. The adaptive divergence regularization mechanism enables the framework to exploit reference policies for efficient exploration in the early stages, while gradually reducing reliance on them as training progresses to avoid inheriting their limitations. Experiments in pursuit and confrontation scenarios demonstrate that ARAC achieves faster convergence, higher final success rates, and stronger scalability across varying numbers of agents compared with MARL baselines, highlighting its effectiveness in complex graph-structured environments.
TetriServe: Efficient DiT Serving for Heterogeneous Image Generation
Oct 02, 2025Diffusion Transformer (DiT) models excel at generating highquality images through iterative denoising steps, but serving them under strict Service Level Objectives (SLOs) is challenging due to their high computational cost, particularly at large resolutions. Existing serving systems use fixed degree sequence parallelism, which is inefficient for heterogeneous workloads with mixed resolutions and deadlines, leading to poor GPU utilization and low SLO attainment. In this paper, we propose step-level sequence parallelism to dynamically adjust the parallel degree of individual requests according to their deadlines. We present TetriServe, a DiT serving system that implements this strategy for highly efficient image generation. Specifically, TetriServe introduces a novel round-based scheduling mechanism that improves SLO attainment: (1) discretizing time into fixed rounds to make deadline-aware scheduling tractable, (2) adapting parallelism at the step level and minimize GPU hour consumption, and (3) jointly packing requests to minimize late completions. Extensive evaluation on state-of-the-art DiT models shows that TetriServe achieves up to 32% higher SLO attainment compared to existing solutions without degrading image quality.
White-box Compiler Fuzzing Empowered by Large Language Models
Oct 24, 2023



Compiler correctness is crucial, as miscompilation falsifying the program behaviors can lead to serious consequences. In the literature, fuzzing has been extensively studied to uncover compiler defects. However, compiler fuzzing remains challenging: Existing arts focus on black- and grey-box fuzzing, which generates tests without sufficient understanding of internal compiler behaviors. As such, they often fail to construct programs to exercise conditions of intricate optimizations. Meanwhile, traditional white-box techniques are computationally inapplicable to the giant codebase of compilers. Recent advances demonstrate that Large Language Models (LLMs) excel in code generation/understanding tasks and have achieved state-of-the-art performance in black-box fuzzing. Nonetheless, prompting LLMs with compiler source-code information remains a missing piece of research in compiler testing. To this end, we propose WhiteFox, the first white-box compiler fuzzer using LLMs with source-code information to test compiler optimization. WhiteFox adopts a dual-model framework: (i) an analysis LLM examines the low-level optimization source code and produces requirements on the high-level test programs that can trigger the optimization; (ii) a generation LLM produces test programs based on the summarized requirements. Additionally, optimization-triggering tests are used as feedback to further enhance the test generation on the fly. Our evaluation on four popular compilers shows that WhiteFox can generate high-quality tests to exercise deep optimizations requiring intricate conditions, practicing up to 80 more optimizations than state-of-the-art fuzzers. To date, WhiteFox has found in total 96 bugs, with 80 confirmed as previously unknown and 51 already fixed. Beyond compiler testing, WhiteFox can also be adapted for white-box fuzzing of other complex, real-world software systems in general.