 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Planning in a Compact Latent Action Space
Aug 25, 2022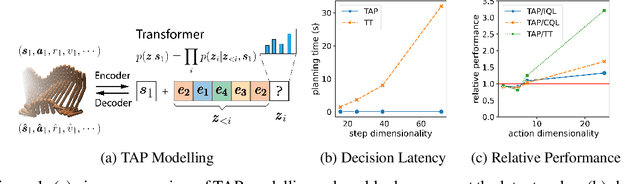
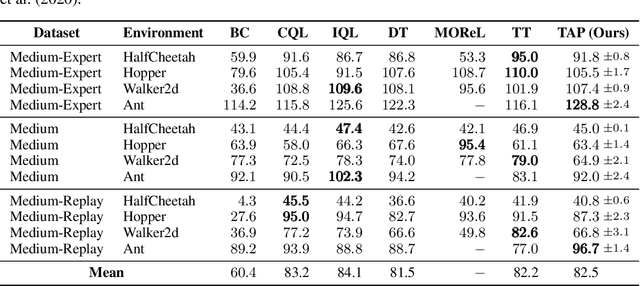
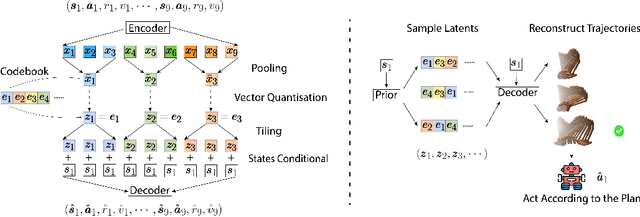
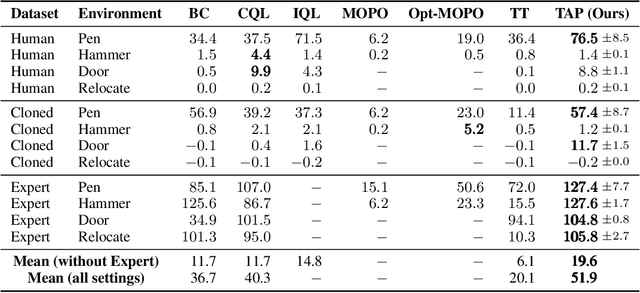
While planning-based sequence modelling methods have shown great potential in continuous control, scaling them to high-dimensional state-action sequences remains an open challenge due to the high computational complexity and innate difficulty of planning in high-dimensional spaces. We propose the Trajectory Autoencoding Planner (TAP), a planning-based sequence modelling RL method that scales to high state-action dimensionalities. Using a state-conditional Vector-Quantized Variational Autoencoder (VQ-VAE), TAP models the conditional distribution of the trajectories given the current state. When deployed as an RL agent, TAP avoids planning step-by-step in a high-dimensional continuous action space but instead looks for the optimal latent code sequences by beam search. Unlike $O(D^3)$ complexity of Trajectory Transformer, TAP enjoys constant $O(C)$ planning computational complexity regarding state-action dimensionality $D$. Our empirical evaluation also shows the increasingly strong performance of TAP with the growing dimensionality. For Adroit robotic hand manipulation tasks with high state and action dimensionality, TAP surpasses existing model-based methods, including TT, with a large margin and also beats strong model-free actor-critic baselines.
AutoShard: Automated Embedding Table Sharding for Recommender Systems
Aug 12, 2022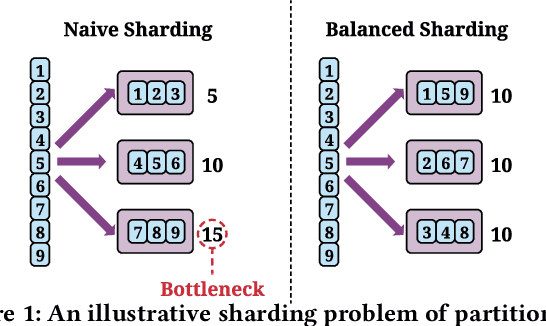
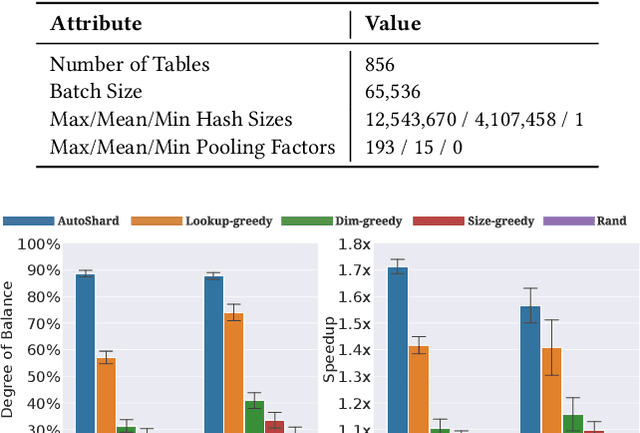

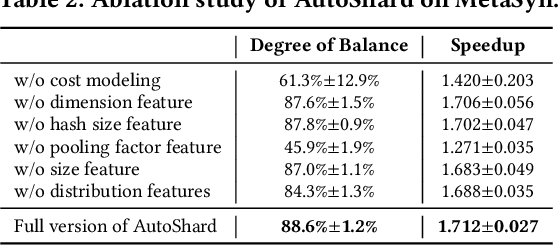
Embedding learning is an important technique in deep recommendation models to map categorical features to dense vectors. However, the embedding tables often demand an extremely large number of parameters, which become the storage and efficiency bottlenecks. Distributed training solutions have been adopted to partition the embedding tables into multiple devices. However, the embedding tables can easily lead to imbalances if not carefully partitioned. This is a significant design challenge of distributed systems named embedding table sharding, i.e., how we should partition the embedding tables to balance the costs across devices, which is a non-trivial task because 1) it is hard to efficiently and precisely measure the cost, and 2) the partition problem is known to be NP-hard. In this work, we introduce our novel practice in Meta, namely AutoShard, which uses a neural cost model to directly predict the multi-table costs and leverages deep reinforcement learning to solve the partition problem. Experimental results on an open-sourced large-scale synthetic dataset and Meta's production dataset demonstrate the superiority of AutoShard over the heuristics. Moreover, the learned policy of AutoShard can transfer to sharding tasks with various numbers of tables and different ratios of the unseen tables without any fine-tuning. Furthermore, AutoShard can efficiently shard hundreds of tables in seconds. The effectiveness, transferability, and efficiency of AutoShard make it desirable for production use. Our algorithms have been deployed in Meta production environment. A prototype is available at https://github.com/daochenzha/autoshard
Denoised MDPs: Learning World Models Better Than the World Itself
Jul 18, 2022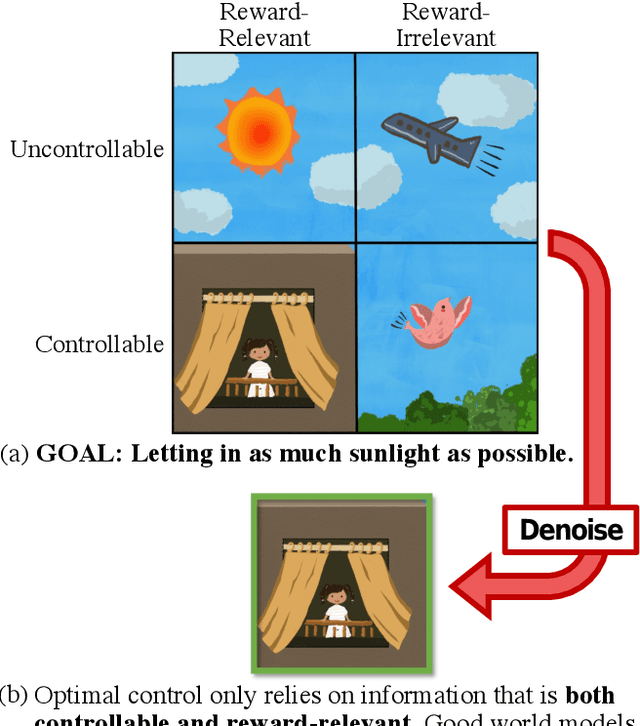
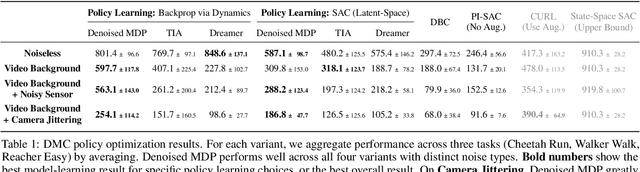
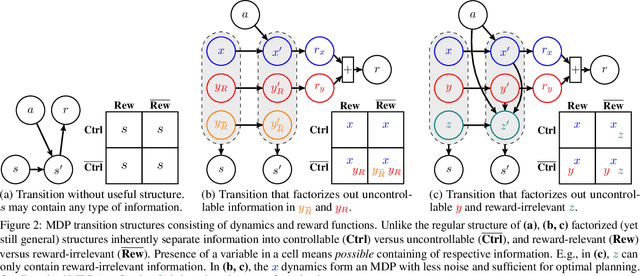
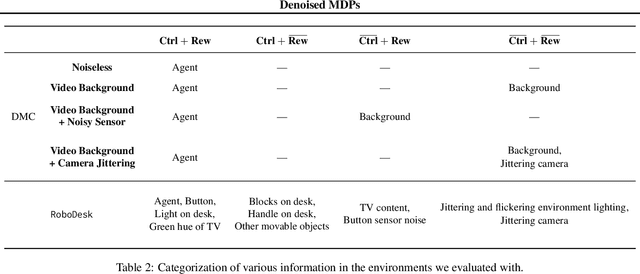
The ability to separate signal from noise, and reason with clean abstractions, is critical to intelligence. With this ability, humans can efficiently perform real world tasks without considering all possible nuisance factors.How can artificial agents do the same? What kind of information can agents safely discard as noises? In this work, we categorize information out in the wild into four types based on controllability and relation with reward, and formulate useful information as that which is both controllable and reward-relevant. This framework clarifies the kinds information removed by various prior work on representation learning in reinforcement learning (RL), and leads to our proposed approach of learning a Denoised MDP that explicitly factors out certain noise distractors. Extensive experiments on variants of DeepMind Control Suite and RoboDesk demonstrate superior performance of our denoised world model over using raw observations alone, and over prior works, across policy optimization control tasks as well as the non-control task of joint position regression.
Understanding the Role of Nonlinearity in Training Dynamics of Contrastive Learning
Jun 02, 2022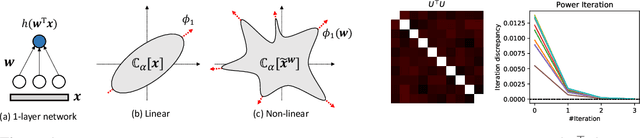
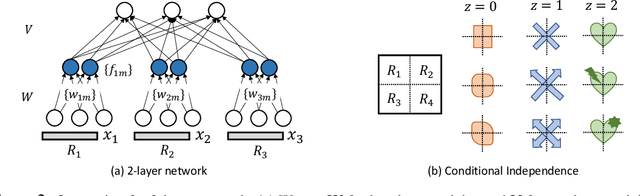

While the empirical success of self-supervised learning (SSL) heavily relies on the usage of deep nonlinear models, many theoretical works proposed to understand SSL still focus on linear ones. In this paper, we study the role of nonlinearity in the training dynamics of contrastive learning (CL) on one and two-layer nonlinear networks with homogeneous activation $h(x) = h'(x)x$. We theoretically demonstrate that (1) the presence of nonlinearity leads to many local optima even in 1-layer setting, each corresponding to certain patterns from the data distribution, while with linear activation, only one major pattern can be learned; and (2) nonlinearity leads to specialized weights into diverse patterns, a behavior that linear activation is proven not capable of. These findings suggest that models with lots of parameters can be regarded as a \emph{brute-force} way to find these local optima induced by nonlinearity, a possible underlying reason why empirical observations such as the lottery ticket hypothesis hold. In addition, for 2-layer setting, we also discover \emph{global modulation}: those local patterns discriminative from the perspective of global-level patterns are prioritized to learn, further characterizing the learning process. Simulation verifies our theoretical findings.
On the Importance of Asymmetry for Siamese Representation Learning
Apr 01, 2022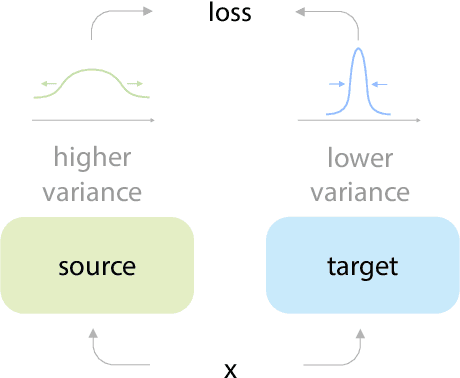

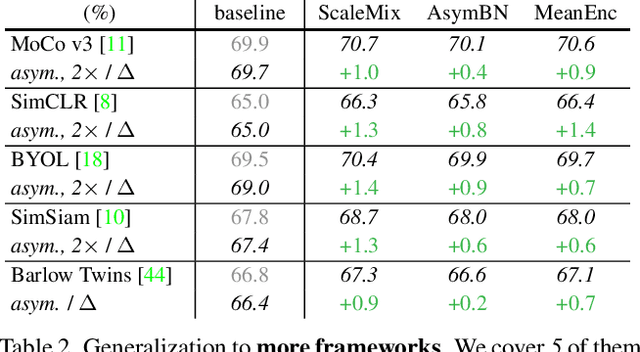
Many recent self-supervised frameworks for visual representation learning are based on certain forms of Siamese networks. Such networks are conceptually symmetric with two parallel encoders, but often practically asymmetric as numerous mechanisms are devised to break the symmetry. In this work, we conduct a formal study on the importance of asymmetry by explicitly distinguishing the two encoders within the network -- one produces source encodings and the other targets. Our key insight is keeping a relatively lower variance in target than source generally benefits learning. This is empirically justified by our results from five case studies covering different variance-oriented designs, and is aligned with our preliminary theoretical analysis on the baseline. Moreover, we find the improvements from asymmetric designs generalize well to longer training schedules, multiple other frameworks and newer backbones. Finally, the combined effect of several asymmetric designs achieves a state-of-the-art accuracy on ImageNet linear probing and competitive results on downstream transfer. We hope our exploration will inspire more research in exploiting asymmetry for Siamese representation learning.
Understanding Curriculum Learning in Policy Optimization for Solving Combinatorial Optimization Problems
Feb 11, 2022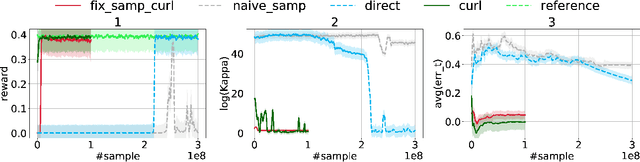
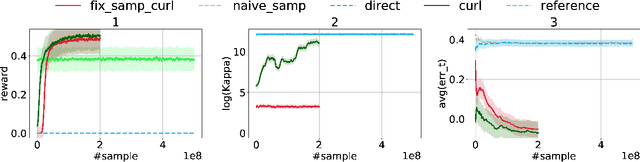
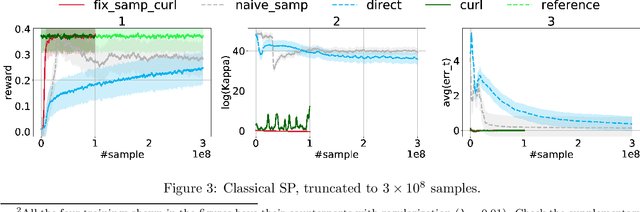
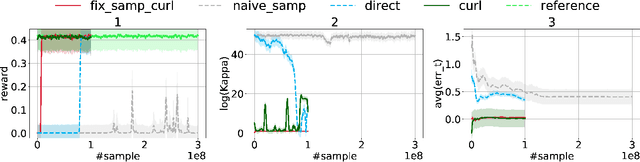
Over the recent years, reinforcement learning (RL) has shown impressive performance in finding strategic solutions for game environments, and recently starts to show promising results in solving combinatorial optimization (CO) problems, inparticular when coupled with curriculum learning to facilitate training. Despite emerging empirical evidence, theoretical study on why RL helps is still at its early stage. This paper presents the first systematic study on policy optimization methods for solving CO problems. We show that CO problems can be naturally formulated as latent Markov Decision Processes (LMDPs), and prove convergence bounds on natural policy gradient (NPG) for solving LMDPs. Furthermore, our theory explains the benefit of curriculum learning: it can find a strong sampling policy and reduce the distribution shift, a critical quantity that governs the convergence rate in our theorem. For a canonical combinatorial problem, Secretary Problem, we formally prove that distribution shift is reduced exponentially with curriculum learning. Our theory also shows we can simplify the curriculum learning scheme used in prior work from multi-step to single-step. Lastly, we provide extensive experiments on Secretary Problem and Online Knapsack to empirically verify our findings.
Deep Contrastive Learning is Provably (almost) Principal Component Analysis
Jan 29, 2022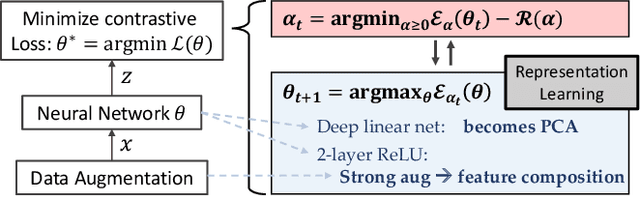

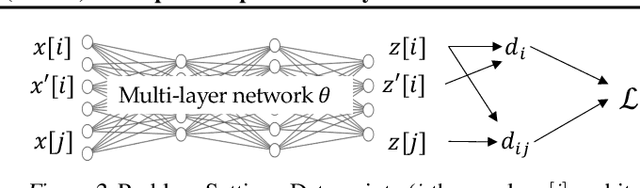
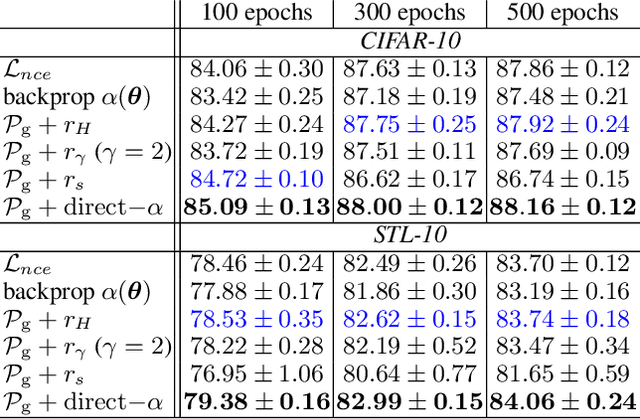
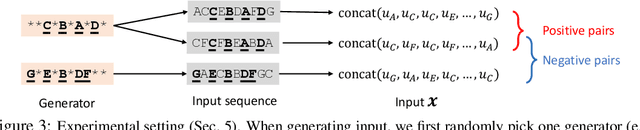
We show that Contrastive Learning (CL) under a family of loss functions (including InfoNCE) has a game-theoretical formulation, where the \emph{max player} finds representation to maximize contrastiveness, and the \emph{min player} puts weights on pairs of samples with similar representation. We show that the max player who does \emph{representation learning} reduces to Principal Component Analysis for deep linear network, and almost all local minima are global, recovering optimal PCA solutions. Experiments show that the formulation yields comparable (or better) performance on CIFAR10 and STL-10 when extending beyond InfoNCE, yielding novel contrastive losses. Furthermore, we extend our theoretical analysis to 2-layer ReLU networks, showing its difference from linear ones, and proving that feature composition is preferred over picking single dominant feature under strong augmentation.
Learning Bounded Context-Free-Grammar via LSTM and the Transformer:Difference and Explanations
Dec 16, 2021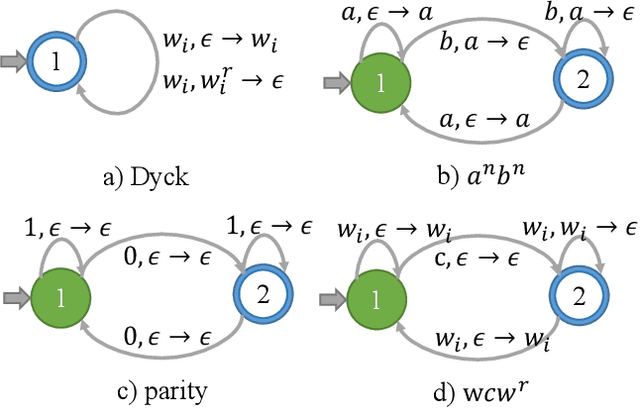
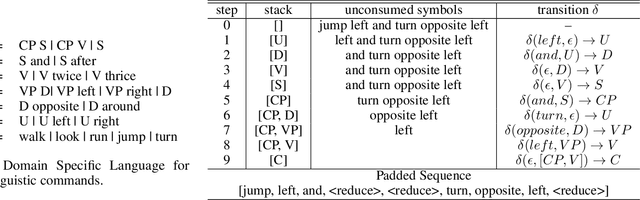
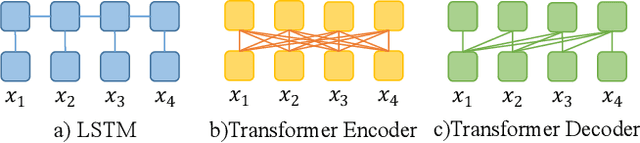
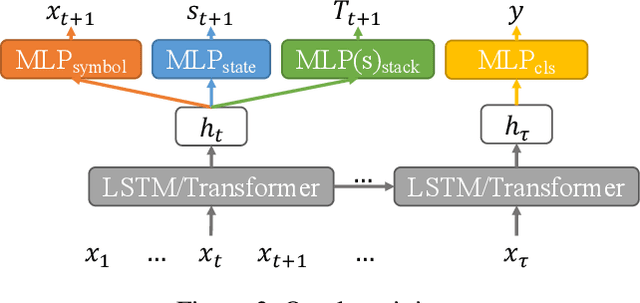
Long Short-Term Memory (LSTM) and Transformers are two popular neural architectures used for natural language processing tasks. Theoretical results show that both are Turing-complete and can represent any context-free language (CFL).In practice, it is often observed that Transformer models have better representation power than LSTM. But the reason is barely understood. We study such practical differences between LSTM and Transformer and propose an explanation based on their latent space decomposition patterns. To achieve this goal, we introduce an oracle training paradigm, which forces the decomposition of the latent representation of LSTM and the Transformer and supervises with the transitions of the Pushdown Automaton (PDA) of the corresponding CFL. With the forced decomposition, we show that the performance upper bounds of LSTM and Transformer in learning CFL are close: both of them can simulate a stack and perform stack operation along with state transitions. However, the absence of forced decomposition leads to the failure of LSTM models to capture the stack and stack operations, while having a marginal impact on the Transformer model. Lastly, we connect the experiment on the prototypical PDA to a real-world parsing task to re-verify the conclusions
Dynamic Graph Representation Learning via Graph Transformer Networks
Nov 19, 2021
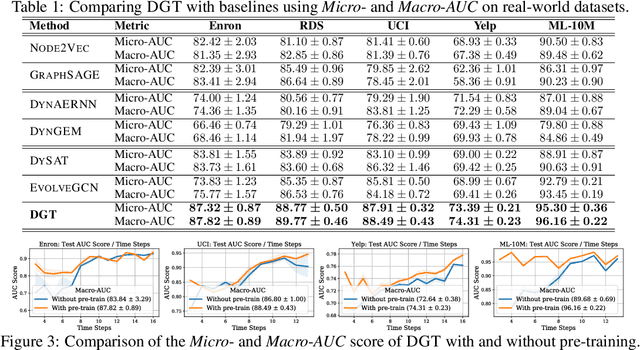
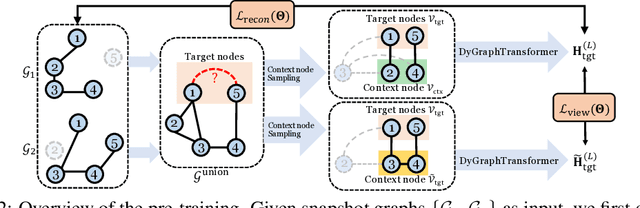
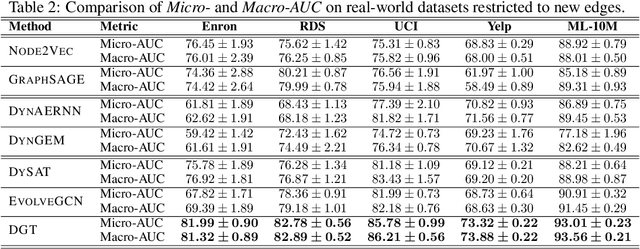
Dynamic graph representation learning is an important task with widespread applications. Previous methods on dynamic graph learning are usually sensitive to noisy graph information such as missing or spurious connections, which can yield degenerated performance and generalization. To overcome this challenge, we propose a Transformer-based dynamic graph learning method named Dynamic Graph Transformer (DGT) with spatial-temporal encoding to effectively learn graph topology and capture implicit links. To improve the generalization ability, we introduce two complementary self-supervised pre-training tasks and show that jointly optimizing the two pre-training tasks results in a smaller Bayesian error rate via an information-theoretic analysis. We also propose a temporal-union graph structure and a target-context node sampling strategy for efficient and scalable training. Extensive experiments on real-world datasets illustrate that DGT presents superior performance compared with several state-of-the-art baselines.
Understanding Dimensional Collapse in Contrastive Self-supervised Learning
Oct 18, 2021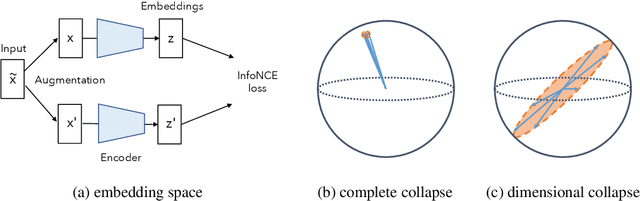

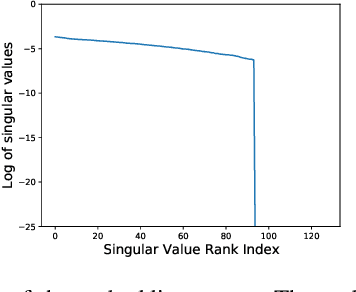
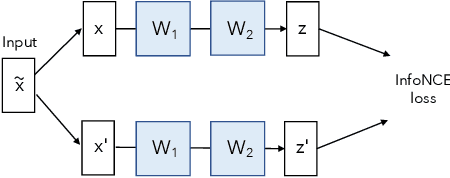
Self-supervised visual representation learning aims to learn useful representations without relying on human annotations. Joint embedding approach bases on maximizing the agreement between embedding vectors from different views of the same image. Various methods have been proposed to solve the collapsing problem where all embedding vectors collapse to a trivial constant solution. Among these methods, contrastive learning prevents collapse via negative sample pairs. It has been shown that non-contrastive methods suffer from a lesser collapse problem of a different nature: dimensional collapse, whereby the embedding vectors end up spanning a lower-dimensional subspace instead of the entire available embedding space. Here, we show that dimensional collapse also happens in contrastive learning. In this paper, we shed light on the dynamics at play in contrastive learning that leads to dimensional collapse. Inspired by our theory, we propose a novel contrastive learning method, called DirectCLR, which directly optimizes the representation space without relying on a trainable projector. Experiments show that DirectCLR outperforms SimCLR with a trainable linear projector on ImageNet.