 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Quantum Federated Learning
Jun 16, 2023



Quantum Federated Learning (QFL) is an emerging interdisciplinary field that merges the principles of Quantum Computing (QC) and Federated Learning (FL), with the goal of leveraging quantum technologies to enhance privacy, security, and efficiency in the learning process. Currently, there is no comprehensive survey for this interdisciplinary field. This review offers a thorough, holistic examination of QFL. We aim to provide a comprehensive understanding of the principles, techniques, and emerging applications of QFL. We discuss the current state of research in this rapidly evolving field, identify challenges and opportunities associated with integrating these technologies, and outline future directions and open research questions. We propose a unique taxonomy of QFL techniques, categorized according to their characteristics and the quantum techniques employed. As the field of QFL continues to progress, we can anticipate further breakthroughs and applications across various industries, driving innovation and addressing challenges related to data privacy, security, and resource optimization. This review serves as a first-of-its-kind comprehensive guide for researchers and practitioners interested in understanding and advancing the field of QFL.
Sim-on-Wheels: Physical World in the Loop Simulation for Self-Driving
Jun 15, 2023We present Sim-on-Wheels, a safe, realistic, and vehicle-in-loop framework to test autonomous vehicles' performance in the real world under safety-critical scenarios. Sim-on-wheels runs on a self-driving vehicle operating in the physical world. It creates virtual traffic participants with risky behaviors and seamlessly inserts the virtual events into images perceived from the physical world in real-time. The manipulated images are fed into autonomy, allowing the self-driving vehicle to react to such virtual events. The full pipeline runs on the actual vehicle and interacts with the physical world, but the safety-critical events it sees are virtual. Sim-on-Wheels is safe, interactive, realistic, and easy to use. The experiments demonstrate the potential of Sim-on-Wheels to facilitate the process of testing autonomous driving in challenging real-world scenes with high fidelity and low risk.
Variational Bayesian Framework for Advanced Image Generation with Domain-Related Variables
May 23, 2023


Deep generative models (DGMs) and their conditional counterparts provide a powerful ability for general-purpose generative modeling of data distributions. However, it remains challenging for existing methods to address advanced conditional generative problems without annotations, which can enable multiple applications like image-to-image translation and image editing. We present a unified Bayesian framework for such problems, which introduces an inference stage on latent variables within the learning process. In particular, we propose a variational Bayesian image translation network (VBITN) that enables multiple image translation and editing tasks. Comprehensive experiments show the effectiveness of our method on unsupervised image-to-image translation, and demonstrate the novel advanced capabilities for semantic editing and mixed domain translation.
* 5 pages, 2 figures,
Deep GEM-Based Network for Weakly Supervised UWB Ranging Error Mitigation
May 23, 2023Ultra-wideband (UWB)-based techniques, while becoming mainstream approaches for high-accurate positioning, tend to be challenged by ranging bias in harsh environments. The emerging learning-based methods for error mitigation have shown great performance improvement via exploiting high semantic features from raw data. However, these methods rely heavily on fully labeled data, leading to a high cost for data acquisition. We present a learning framework based on weak supervision for UWB ranging error mitigation. Specifically, we propose a deep learning method based on the generalized expectation-maximization (GEM) algorithm for robust UWB ranging error mitigation under weak supervision. Such method integrate probabilistic modeling into the deep learning scheme, and adopt weakly supervised labels as prior information. Extensive experiments in various supervision scenarios illustrate the superiority of the proposed method.
* 6 pages, 4 figures, Published in: MILCOM 2021 - 2021 IEEE Military Communications Conference (MILCOM)
A Deep Learning Approach for Generating Soft Range Information from RF Data
May 23, 2023



Radio frequency (RF)-based techniques are widely adopted for indoor localization despite the challenges in extracting sufficient information from measurements. Soft range information (SRI) offers a promising alternative for highly accurate localization that gives all probable range values rather than a single estimate of distance. We propose a deep learning approach to generate accurate SRI from RF measurements. In particular, the proposed approach is implemented by a network with two neural modules and conducts the generation directly from raw data. Extensive experiments on a case study with two public datasets are conducted to quantify the efficiency in different indoor localization tasks. The results show that the proposed approach can generate highly accurate SRI, and significantly outperforms conventional techniques in both non-line-of-sight (NLOS) detection and ranging error mitigation.
* Published in: 2021 IEEE Globecom Workshops (GC Wkshps)
Generalized Expectation Maximization Framework for Blind Image Super Resolution
May 23, 2023



Learning-based methods for blind single image super resolution (SISR) conduct the restoration by a learned mapping between high-resolution (HR) images and their low-resolution (LR) counterparts degraded with arbitrary blur kernels. However, these methods mostly require an independent step to estimate the blur kernel, leading to error accumulation between steps. We propose an end-to-end learning framework for the blind SISR problem, which enables image restoration within a unified Bayesian framework with either full- or semi-supervision. The proposed method, namely SREMN, integrates learning techniques into the generalized expectation-maximization (GEM) algorithm and infers HR images from the maximum likelihood estimation (MLE). Extensive experiments show the superiority of the proposed method with comparison to existing work and novelty in semi-supervised learning.
Efficient Planar Pose Estimation via UWB Measurements
Sep 15, 2022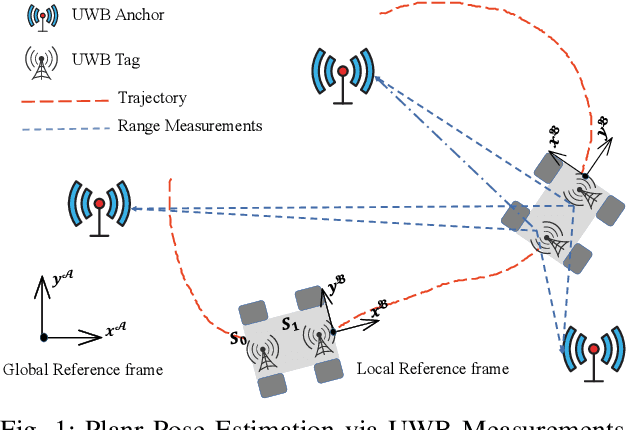
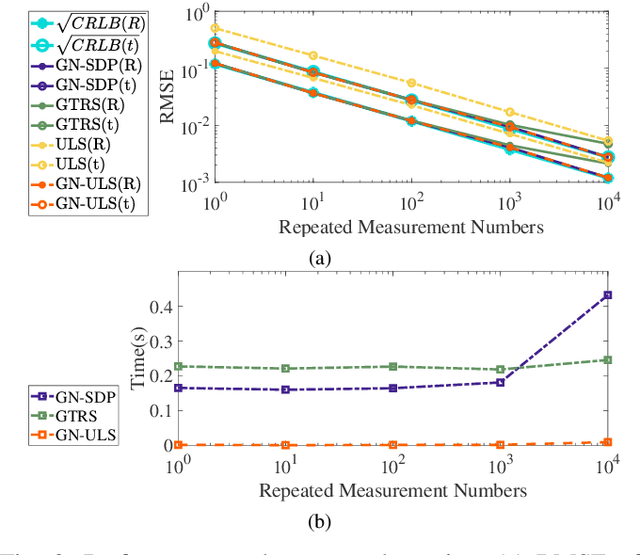
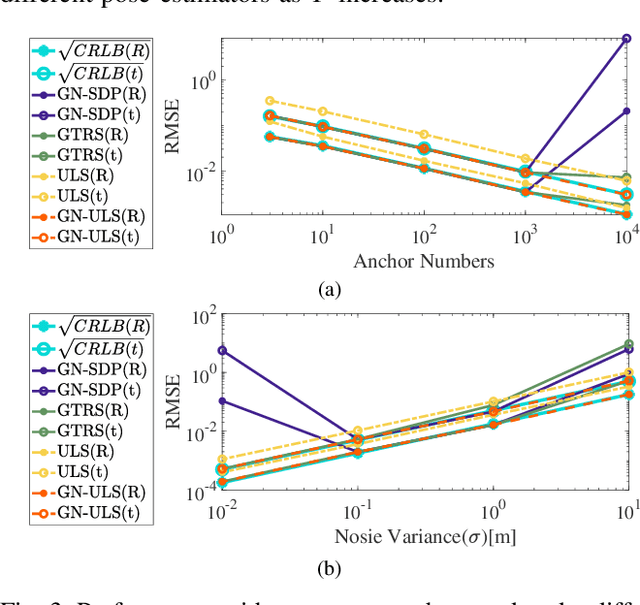

State estimation is an essential part of autonomous systems. Integrating the Ultra-Wideband(UWB) technique has been shown to correct the long-term estimation drift and bypass the complexity of loop closure detection. However, few works on robotics adopt UWB as a stand-alone state estimation solution. The primary purpose of this work is to investigate planar pose estimation using only UWB range measurements and study the estimator's statistical efficiency. We prove the excellent property of a two-step scheme, which says that we can refine a consistent estimator to be asymptotically efficient by one step of Gauss-Newton iteration. Grounded on this result, we design the GN-ULS estimator and evaluate it through simulations and collected datasets. GN-ULS attains millimeter and sub-degree level accuracy on our static datasets and attains centimeter and degree level accuracy on our dynamic datasets, presenting the possibility of using only UWB for real-time state estimation.
Injecting Image Details into CLIP's Feature Space
Aug 31, 2022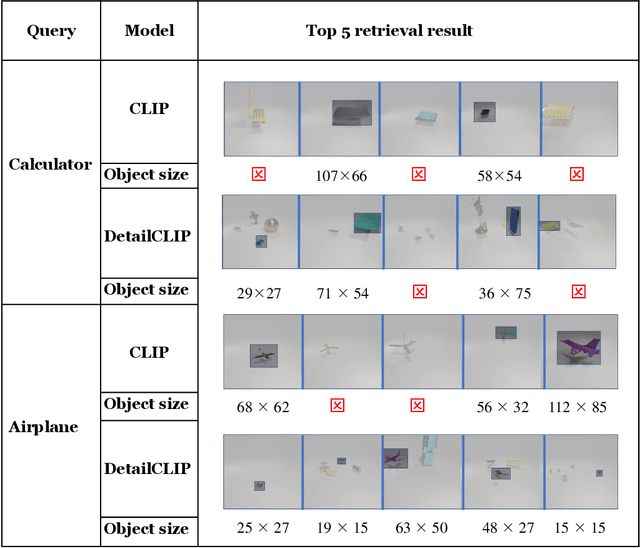
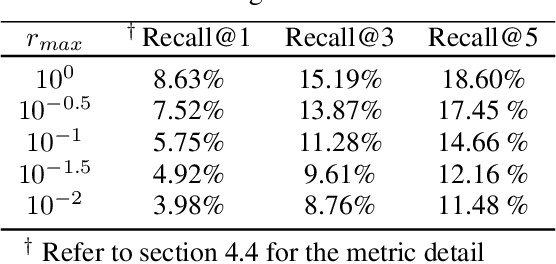
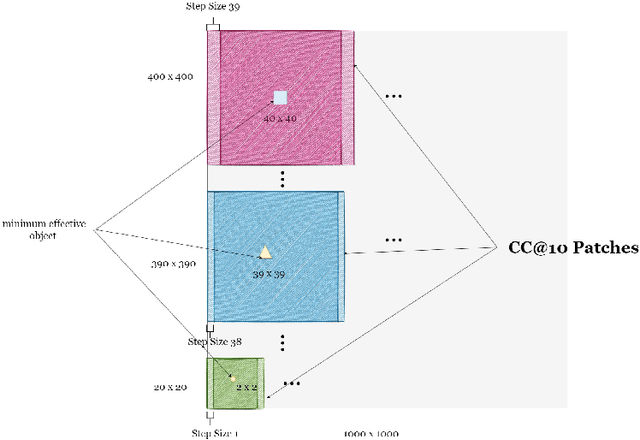
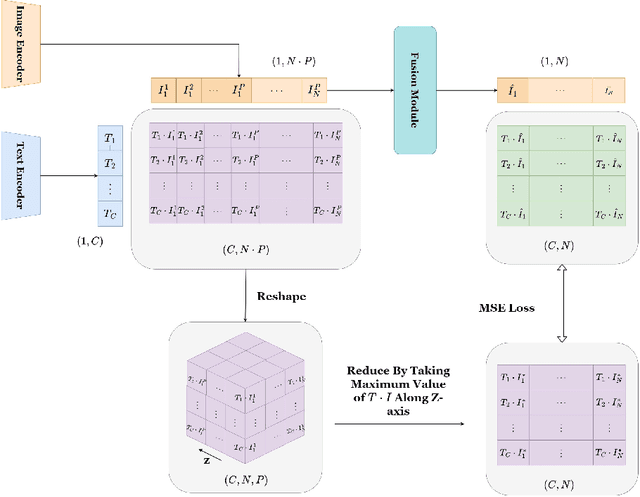
Although CLIP-like Visual Language Models provide a functional joint feature space for image and text, due to the limitation of the CILP-like model's image input size (e.g., 224), subtle details are lost in the feature representation if we input high-resolution images (e.g., 2240). In this work, we introduce an efficient framework that can produce a single feature representation for a high-resolution image that injects image details and shares the same semantic space as the original CLIP. In the framework, we train a feature fusing model based on CLIP features extracted from a carefully designed image patch method that can cover objects of any scale, weakly supervised by image-agnostic class prompted queries. We validate our framework by retrieving images from class prompted queries on the real world and synthetic datasets, showing significant performance improvement on these tasks. Furthermore, to fully demonstrate our framework's detail retrieval ability, we construct a CLEVR-like synthetic dataset called CLVER-DS, which is fully annotated and has a controllable object scale.
CoCAtt: A Cognitive-Conditioned Driver Attention Dataset (Supplementary Material)
Jul 08, 2022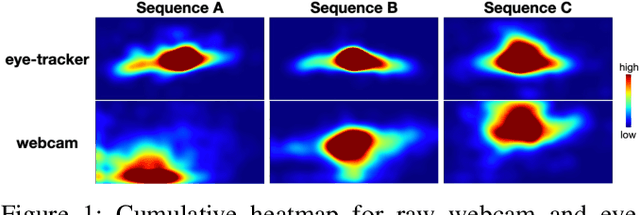
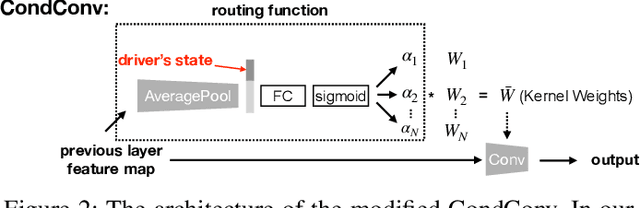
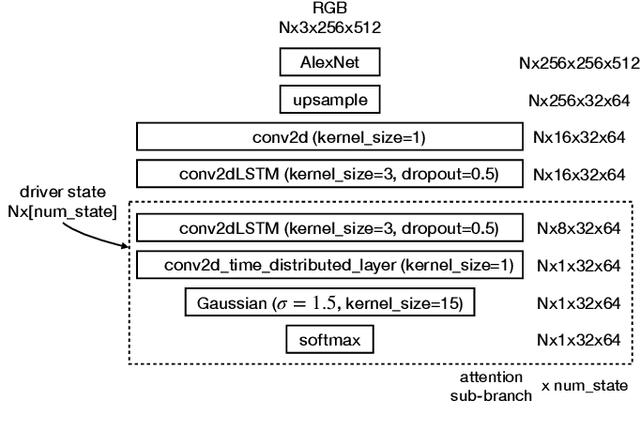

The task of driver attention prediction has drawn considerable interest among researchers in robotics and the autonomous vehicle industry. Driver attention prediction can play an instrumental role in mitigating and preventing high-risk events, like collisions and casualties. However, existing driver attention prediction models neglect the distraction state and intention of the driver, which can significantly influence how they observe their surroundings. To address these issues, we present a new driver attention dataset, CoCAtt (Cognitive-Conditioned Attention). Unlike previous driver attention datasets, CoCAtt includes per-frame annotations that describe the distraction state and intention of the driver. In addition, the attention data in our dataset is captured in both manual and autopilot modes using eye-tracking devices of different resolutions. Our results demonstrate that incorporating the above two driver states into attention modeling can improve the performance of driver attention prediction. To the best of our knowledge, this work is the first to provide autopilot attention data. Furthermore, CoCAtt is currently the largest and the most diverse driver attention dataset in terms of autonomy levels, eye tracker resolutions, and driving scenarios. CoCAtt is available for download at https://cocatt-dataset.github.io.
Learning Dynamic View Synthesis With Few RGBD Cameras
Apr 22, 2022
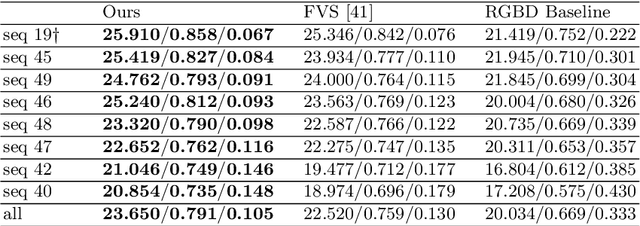
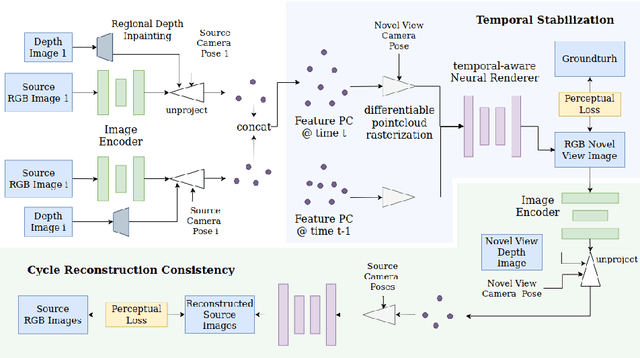

There have been significant advancements in dynamic novel view synthesis in recent years. However, current deep learning models often require (1) prior models (e.g., SMPL human models), (2) heavy pre-processing, or (3) per-scene optimization. We propose to utilize RGBD cameras to remove these limitations and synthesize free-viewpoint videos of dynamic indoor scenes. We generate feature point clouds from RGBD frames and then render them into free-viewpoint videos via a neural renderer. However, the inaccurate, unstable, and incomplete depth measurements induce severe distortions, flickering, and ghosting artifacts. We enforce spatial-temporal consistency via the proposed Cycle Reconstruction Consistency and Temporal Stabilization module to reduce these artifacts. We introduce a simple Regional Depth-Inpainting module that adaptively inpaints missing depth values to render complete novel views. Additionally, we present a Human-Things Interactions dataset to validate our approach and facilitate future research. The dataset consists of 43 multi-view RGBD video sequences of everyday activities, capturing complex interactions between human subjects and their surroundings. Experiments on the HTI dataset show that our method outperforms the baseline per-frame image fidelity and spatial-temporal consistency. We will release our code, and the dataset on the website soon.