 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Two-way Partial AUC with an End-to-end Framework
Jun 23, 2022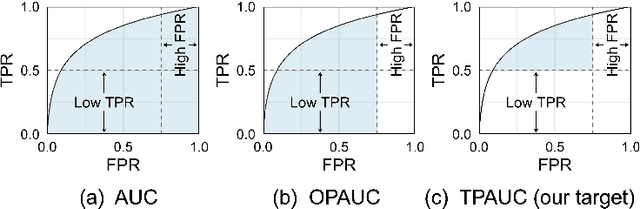

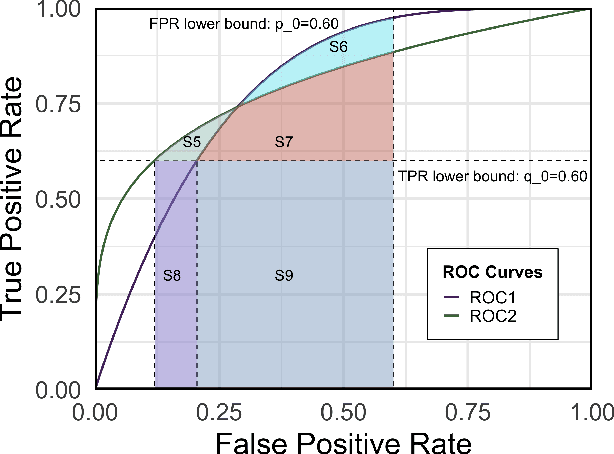
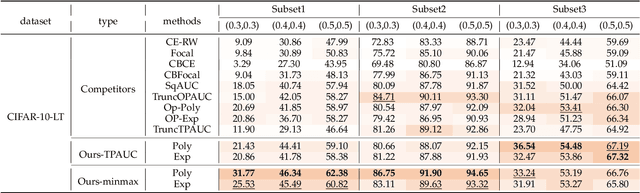
The Area Under the ROC Curve (AUC) is a crucial metric for machine learning, which evaluates the average performance over all possible True Positive Rates (TPRs) and False Positive Rates (FPRs). Based on the knowledge that a skillful classifier should simultaneously embrace a high TPR and a low FPR, we turn to study a more general variant called Two-way Partial AUC (TPAUC), where only the region with $\mathsf{TPR} \ge \alpha, \mathsf{FPR} \le \beta$ is included in the area. Moreover, recent work shows that the TPAUC is essentially inconsistent with the existing Partial AUC metrics where only the FPR range is restricted, opening a new problem to seek solutions to leverage high TPAUC. Motivated by this, we present the first trial in this paper to optimize this new metric. The critical challenge along this course lies in the difficulty of performing gradient-based optimization with end-to-end stochastic training, even with a proper choice of surrogate loss. To address this issue, we propose a generic framework to construct surrogate optimization problems, which supports efficient end-to-end training with deep learning. Moreover, our theoretical analyses show that: 1) the objective function of the surrogate problems will achieve an upper bound of the original problem under mild conditions, and 2) optimizing the surrogate problems leads to good generalization performance in terms of TPAUC with a high probability. Finally, empirical studies over several benchmark datasets speak to the efficacy of our framework.
Machine Learning-Friendly Biomedical Datasets for Equivalence and Subsumption Ontology Matching
May 06, 2022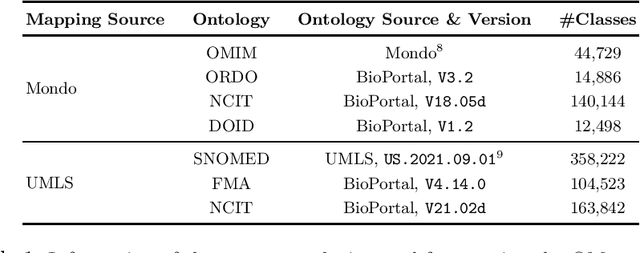
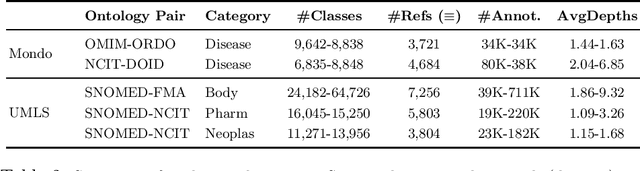
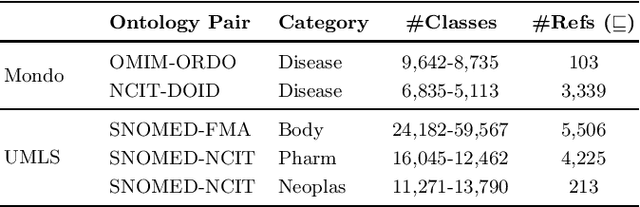
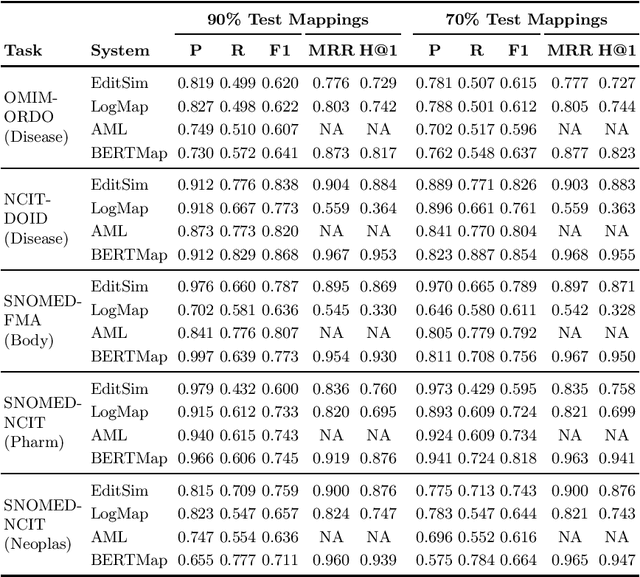
Ontology Matching (OM) plays an important role in many domains such as bioinformatics and the Semantic Web, and its research is becoming increasingly popular, especially with the application of machine learning (ML) techniques. Although the Ontology Alignment Evaluation Initiative (OAEI) represents an impressive effort for the systematic evaluation of OM systems, it still suffers from several limitations including limited evaluation of subsumption mappings, suboptimal reference mappings, and limited support for the evaluation of ML-based systems. To tackle these limitations, we introduce five new biomedical OM tasks involving ontologies extracted from Mondo and UMLS. Each task includes both equivalence and subsumption matching; the quality of reference mappings is ensured by human curation, ontology pruning, etc.; and a comprehensive evaluation framework is proposed to measure OM performance from various perspectives for both ML-based and non-ML-based OM systems. We report evaluation results for OM systems of different types to demonstrate the usage of these resources, all of which are publicly available
RMGN: A Regional Mask Guided Network for Parser-free Virtual Try-on
Apr 24, 2022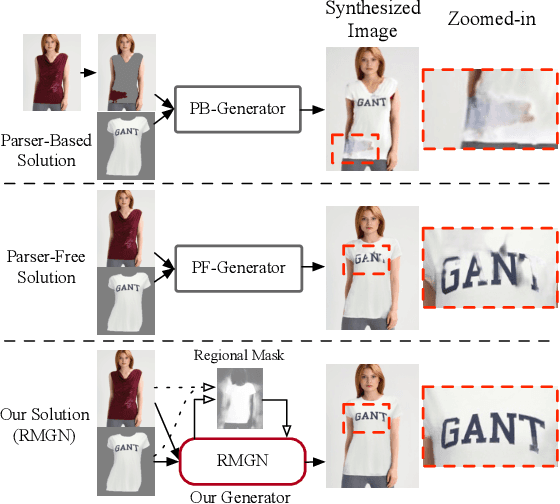
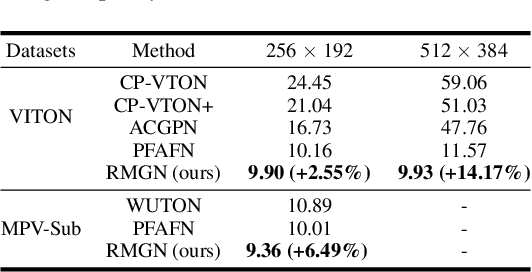
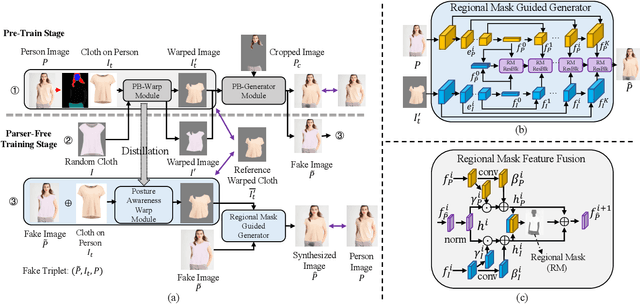
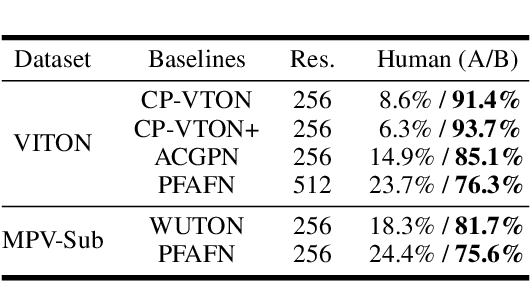
Virtual try-on(VTON) aims at fitting target clothes to reference person images, which is widely adopted in e-commerce.Existing VTON approaches can be narrowly categorized into Parser-Based(PB) and Parser-Free(PF) by whether relying on the parser information to mask the persons' clothes and synthesize try-on images. Although abandoning parser information has improved the applicability of PF methods, the ability of detail synthesizing has also been sacrificed. As a result, the distraction from original cloth may persistin synthesized images, especially in complicated postures and high resolution applications. To address the aforementioned issue, we propose a novel PF method named Regional Mask Guided Network(RMGN). More specifically, a regional mask is proposed to explicitly fuse the features of target clothes and reference persons so that the persisted distraction can be eliminated. A posture awareness loss and a multi-level feature extractor are further proposed to handle the complicated postures and synthesize high resolution images. Extensive experiments demonstrate that our proposed RMGN outperforms both state-of-the-art PB and PF methods.Ablation studies further verify the effectiveness ofmodules in RMGN.
Diverse Instance Discovery: Vision-Transformer for Instance-Aware Multi-Label Image Recognition
Apr 22, 2022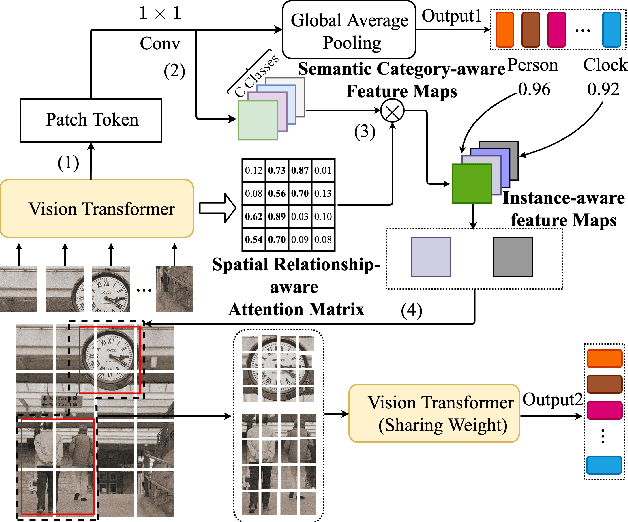
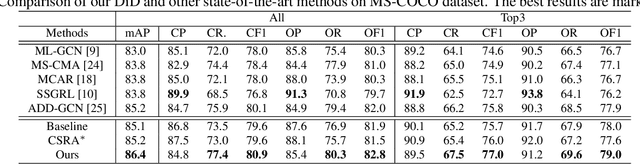
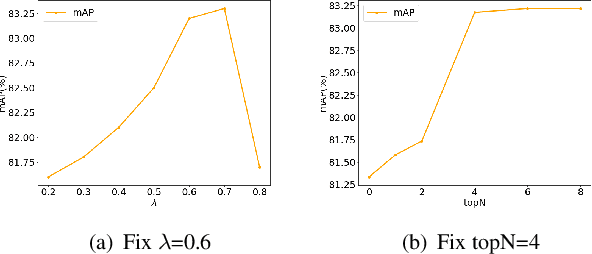
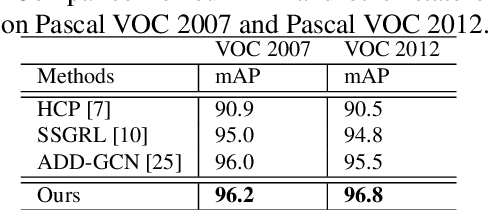
Previous works on multi-label image recognition (MLIR) usually use CNNs as a starting point for research. In this paper, we take pure Vision Transformer (ViT) as the research base and make full use of the advantages of Transformer with long-range dependency modeling to circumvent the disadvantages of CNNs limited to local receptive field. However, for multi-label images containing multiple objects from different categories, scales, and spatial relations, it is not optimal to use global information alone. Our goal is to leverage ViT's patch tokens and self-attention mechanism to mine rich instances in multi-label images, named diverse instance discovery (DiD). To this end, we propose a semantic category-aware module and a spatial relationship-aware module, respectively, and then combine the two by a re-constraint strategy to obtain instance-aware attention maps. Finally, we propose a weakly supervised object localization-based approach to extract multi-scale local features, to form a multi-view pipeline. Our method requires only weakly supervised information at the label level, no additional knowledge injection or other strongly supervised information is required. Experiments on three benchmark datasets show that our method significantly outperforms previous works and achieves state-of-the-art results under fair experimental comparisons.
D^2ETR: Decoder-Only DETR with Computationally Efficient Cross-Scale Attention
Mar 02, 2022
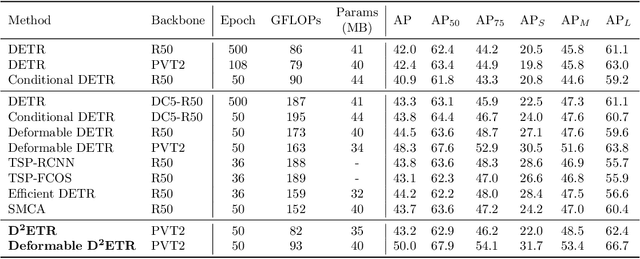
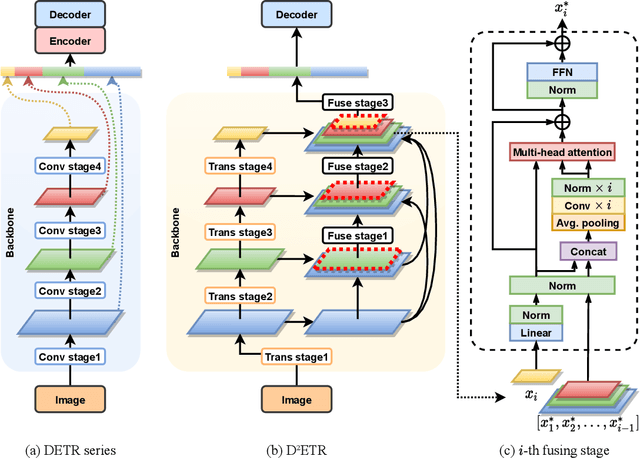
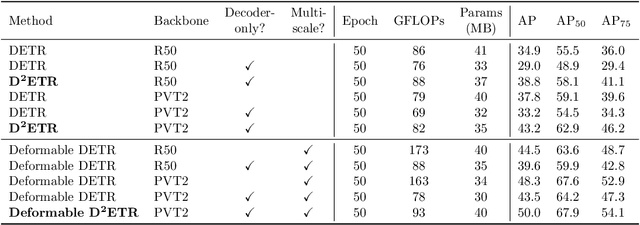
DETR is the first fully end-to-end detector that predicts a final set of predictions without post-processing. However, it suffers from problems such as low performance and slow convergence. A series of works aim to tackle these issues in different ways, but the computational cost is yet expensive due to the sophisticated encoder-decoder architecture. To alleviate this issue, we propose a decoder-only detector called D^2ETR. In the absence of encoder, the decoder directly attends to the fine-fused feature maps generated by the Transformer backbone with a novel computationally efficient cross-scale attention module. D^2ETR demonstrates low computational complexity and high detection accuracy in evaluations on the COCO benchmark, outperforming DETR and its variants.
Contextual Semantic Embeddings for Ontology Subsumption Prediction
Feb 20, 2022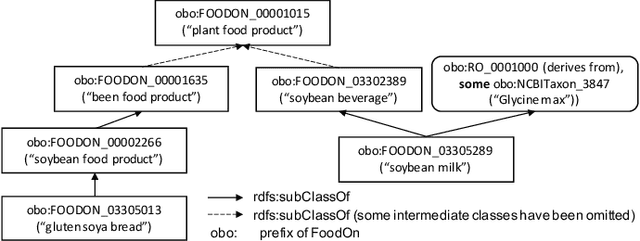
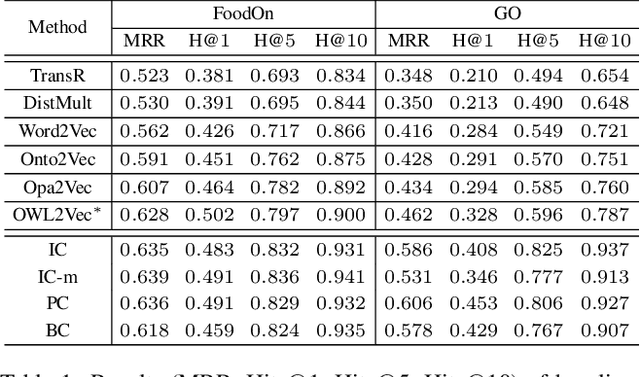
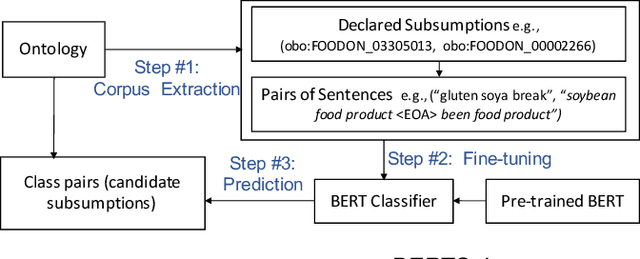
Automating ontology curation is a crucial task in knowledge engineering. Prediction by machine learning techniques such as semantic embedding is a promising direction, but the relevant research is still preliminary. In this paper, we present a class subsumption prediction method named BERTSubs, which uses the pre-trained language model BERT to compute contextual embeddings of the class labels and customized input templates to incorporate contexts of surrounding classes. The evaluation on two large-scale real-world ontologies has shown its better performance than the state-of-the-art.
Beyond ImageNet Attack: Towards Crafting Adversarial Examples for Black-box Domains
Feb 10, 2022
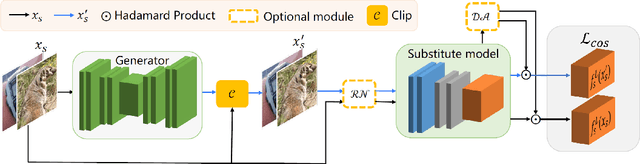
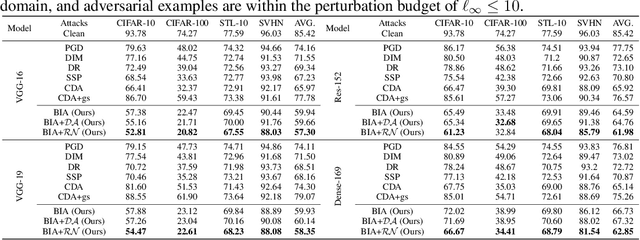
Adversarial examples have posed a severe threat to deep neural networks due to their transferable nature. Currently, various works have paid great efforts to enhance the cross-model transferability, which mostly assume the substitute model is trained in the same domain as the target model. However, in reality, the relevant information of the deployed model is unlikely to leak. Hence, it is vital to build a more practical black-box threat model to overcome this limitation and evaluate the vulnerability of deployed models. In this paper, with only the knowledge of the ImageNet domain, we propose a Beyond ImageNet Attack (BIA) to investigate the transferability towards black-box domains (unknown classification tasks). Specifically, we leverage a generative model to learn the adversarial function for disrupting low-level features of input images. Based on this framework, we further propose two variants to narrow the gap between the source and target domains from the data and model perspectives, respectively. Extensive experiments on coarse-grained and fine-grained domains demonstrate the effectiveness of our proposed methods. Notably, our methods outperform state-of-the-art approaches by up to 7.71\% (towards coarse-grained domains) and 25.91\% (towards fine-grained domains) on average. Our code is available at \url{https://github.com/qilong-zhang/Beyond-ImageNet-Attack}.
Reading-strategy Inspired Visual Representation Learning for Text-to-Video Retrieval
Jan 23, 2022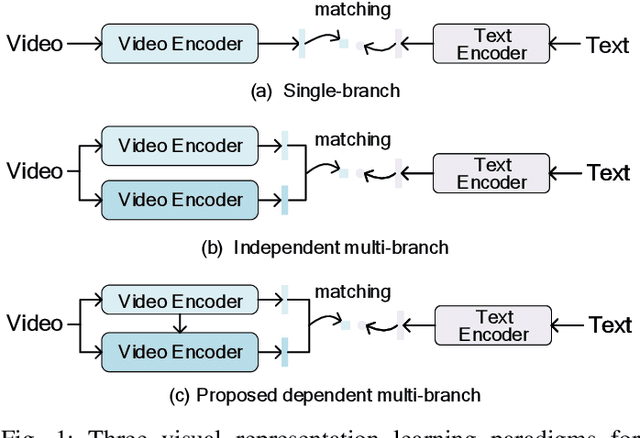
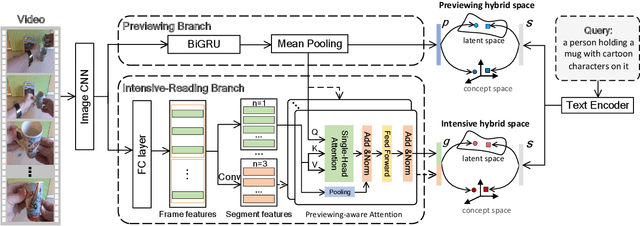
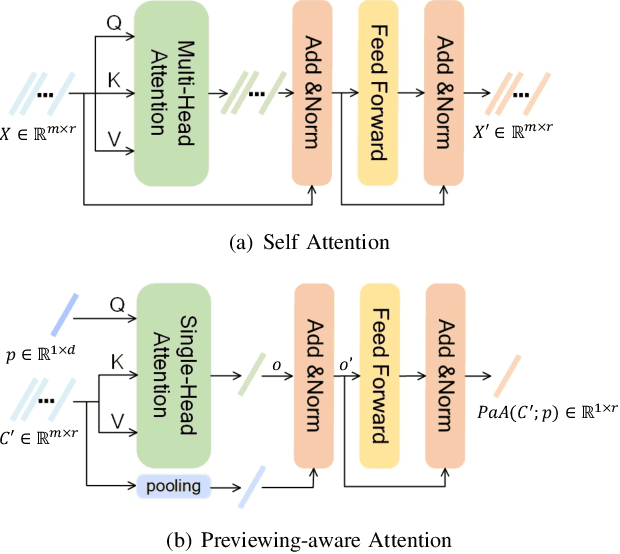
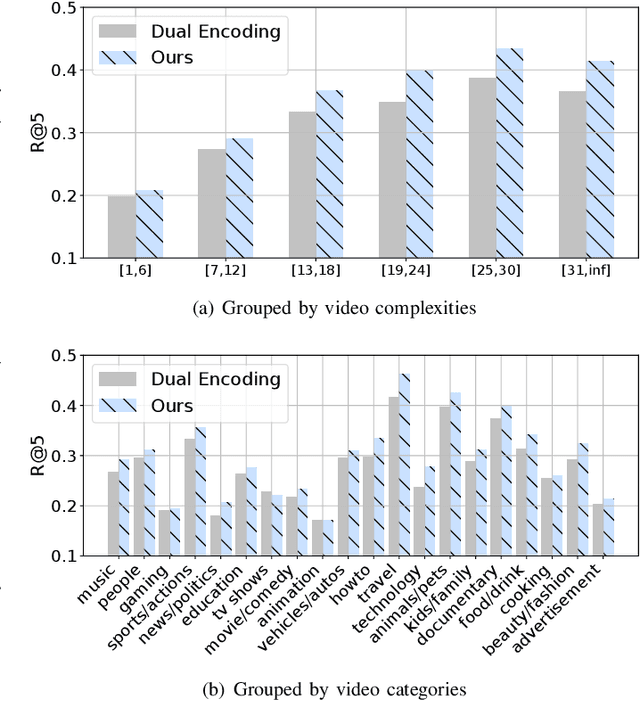
This paper aims for the task of text-to-video retrieval, where given a query in the form of a natural-language sentence, it is asked to retrieve videos which are semantically relevant to the given query, from a great number of unlabeled videos. The success of this task depends on cross-modal representation learning that projects both videos and sentences into common spaces for semantic similarity computation. In this work, we concentrate on video representation learning, an essential component for text-to-video retrieval. Inspired by the reading strategy of humans, we propose a Reading-strategy Inspired Visual Representation Learning (RIVRL) to represent videos, which consists of two branches: a previewing branch and an intensive-reading branch. The previewing branch is designed to briefly capture the overview information of videos, while the intensive-reading branch is designed to obtain more in-depth information. Moreover, the intensive-reading branch is aware of the video overview captured by the previewing branch. Such holistic information is found to be useful for the intensive-reading branch to extract more fine-grained features. Extensive experiments on three datasets are conducted, where our model RIVRL achieves a new state-of-the-art on TGIF and VATEX. Moreover, on MSR-VTT, our model using two video features shows comparable performance to the state-of-the-art using seven video features and even outperforms models pre-trained on the large-scale HowTo100M dataset.
Low-resource Learning with Knowledge Graphs: A Comprehensive Survey
Dec 28, 2021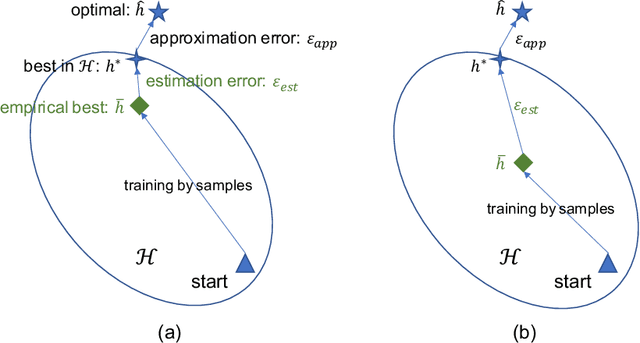
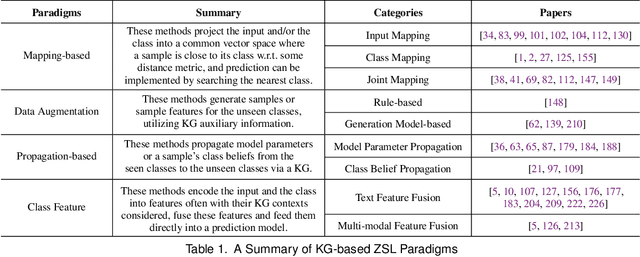
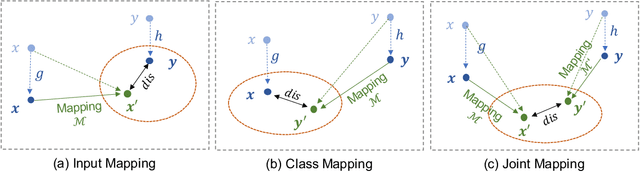
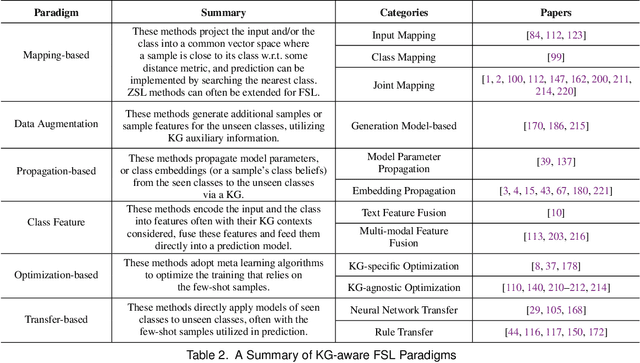
Machine learning methods especially deep neural networks have achieved great success but many of them often rely on a number of labeled samples for training. In real-world applications, we often need to address sample shortage due to e.g., dynamic contexts with emerging prediction targets and costly sample annotation. Therefore, low-resource learning, which aims to learn robust prediction models with no enough resources (especially training samples), is now being widely investigated. Among all the low-resource learning studies, many prefer to utilize some auxiliary information in the form of Knowledge Graph (KG), which is becoming more and more popular for knowledge representation, to reduce the reliance on labeled samples. In this survey, we very comprehensively reviewed over $90$ papers about KG-aware research for two major low-resource learning settings -- zero-shot learning (ZSL) where new classes for prediction have never appeared in training, and few-shot learning (FSL) where new classes for prediction have only a small number of labeled samples that are available. We first introduced the KGs used in ZSL and FSL studies as well as the existing and potential KG construction solutions, and then systematically categorized and summarized KG-aware ZSL and FSL methods, dividing them into different paradigms such as the mapping-based, the data augmentation, the propagation-based and the optimization-based. We next presented different applications, including not only KG augmented tasks in Computer Vision and Natural Language Processing (e.g., image classification, text classification and knowledge extraction), but also tasks for KG curation (e.g., inductive KG completion), and some typical evaluation resources for each task. We eventually discussed some challenges and future directions on aspects such as new learning and reasoning paradigms, and the construction of high quality KGs.
BERTMap: A BERT-based Ontology Alignment System
Dec 23, 2021
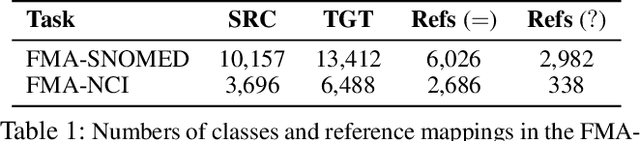
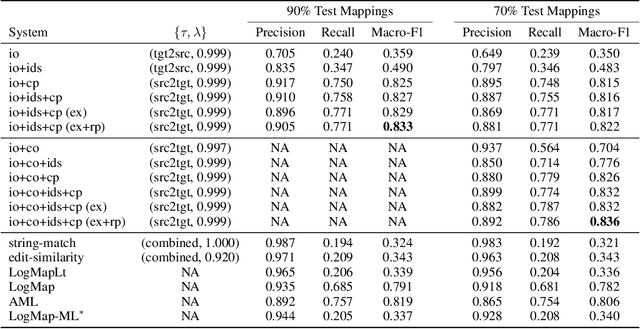
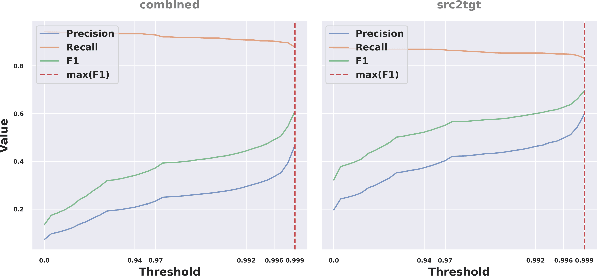
Ontology alignment (a.k.a ontology matching (OM)) plays a critical role in knowledge integration. Owing to the success of machine learning in many domains, it has been applied in OM. However, the existing methods, which often adopt ad-hoc feature engineering or non-contextual word embeddings, have not yet outperformed rule-based systems especially in an unsupervised setting. In this paper, we propose a novel OM system named BERTMap which can support both unsupervised and semi-supervised settings. It first predicts mappings using a classifier based on fine-tuning the contextual embedding model BERT on text semantics corpora extracted from ontologies, and then refines the mappings through extension and repair by utilizing the ontology structure and logic. Our evaluation with three alignment tasks on biomedical ontologies demonstrates that BERTMap can often perform better than the leading OM systems LogMap and AML.