 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUX-PLMs: Pre-training Language Models with Data Multiplexing
Feb 24, 2023



Data multiplexing is a recently proposed method for improving a model's inference efficiency by processing multiple instances simultaneously using an ordered representation mixture. Prior work on data multiplexing only used task-specific Transformers without any pre-training, which limited their accuracy and generality. In this paper, we develop pre-trained multiplexed language models (MUX-PLMs) that can be widely finetuned on any downstream task. Our approach includes a three-stage training procedure and novel multiplexing and demultiplexing modules for improving throughput and downstream task accuracy. We demonstrate our method on BERT and ELECTRA pre-training objectives, with our MUX-BERT and MUX-ELECTRA models achieving 2x/5x inference speedup with a 2-4 \% drop in absolute performance on GLUE and 1-2 \% drop on token-level tasks.
Binarized Neural Machine Translation
Feb 09, 2023



The rapid scaling of language models is motivating research using low-bitwidth quantization. In this work, we propose a novel binarization technique for Transformers applied to machine translation (BMT), the first of its kind. We identify and address the problem of inflated dot-product variance when using one-bit weights and activations. Specifically, BMT leverages additional LayerNorms and residual connections to improve binarization quality. Experiments on the WMT dataset show that a one-bit weight-only Transformer can achieve the same quality as a float one, while being 16x smaller in size. One-bit activations incur varying degrees of quality drop, but mitigated by the proposed architectural changes. We further conduct a scaling law study using production-scale translation datasets, which shows that one-bit weight Transformers scale and generalize well in both in-domain and out-of-domain settings. Implementation in JAX/Flax will be open sourced.
SimCGNN: Simple Contrastive Graph Neural Network for Session-based Recommendation
Feb 08, 2023



Session-based recommendation (SBR) problem, which focuses on next-item prediction for anonymous users, has received increasingly more attention from researchers. Existing graph-based SBR methods all lack the ability to differentiate between sessions with the same last item, and suffer from severe popularity bias. Inspired by nowadays emerging contrastive learning methods, this paper presents a Simple Contrastive Graph Neural Network for Session-based Recommendation (SimCGNN). In SimCGNN, we first obtain normalized session embeddings on constructed session graphs. We next construct positive and negative samples of the sessions by two forward propagation and a novel negative sample selection strategy, and then calculate the constructive loss. Finally, session embeddings are used to give prediction. Extensive experiments conducted on two real-word datasets show our SimCGNN achieves a significant improvement over state-of-the-art methods.
AnyTOD: A Programmable Task-Oriented Dialog System
Dec 20, 2022



We propose AnyTOD, an end-to-end task-oriented dialog (TOD) system with zero-shot capability for unseen tasks. We view TOD as a program executed by a language model (LM), where program logic and ontology is provided by a designer in the form of a schema. To enable generalization onto unseen schemas and programs without prior training, AnyTOD adopts a neuro-symbolic approach. A neural LM keeps track of events that occur during a conversation, and a symbolic program implementing the dialog policy is executed to recommend next actions AnyTOD should take. This approach drastically reduces data annotation and model training requirements, addressing a long-standing challenge in TOD research: rapidly adapting a TOD system to unseen tasks and domains. We demonstrate state-of-the-art results on the STAR and ABCD benchmarks, as well as AnyTOD's strong zero-shot transfer capability in low-resource settings. In addition, we release STARv2, an updated version of the STAR dataset with richer data annotations, for benchmarking zero-shot end-to-end TOD models.
Speech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022



Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.
Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners
Dec 09, 2022



This work explores an efficient approach to establish a foundational video-text model for tasks including open-vocabulary video classification, text-to-video retrieval, video captioning and video question-answering. We present VideoCoCa that reuses a pretrained image-text contrastive captioner (CoCa) model and adapt it to video-text tasks with minimal extra training. While previous works adapt image-text models with various cross-frame fusion modules (for example, cross-frame attention layer or perceiver resampler) and finetune the modified architecture on video-text data, we surprisingly find that the generative attentional pooling and contrastive attentional pooling layers in the image-text CoCa design are instantly adaptable to ``flattened frame embeddings'', yielding a strong zero-shot transfer baseline for many video-text tasks. Specifically, the frozen image encoder of a pretrained image-text CoCa takes each video frame as inputs and generates \(N\) token embeddings per frame for totally \(T\) video frames. We flatten \(N \times T\) token embeddings as a long sequence of frozen video representation and apply CoCa's generative attentional pooling and contrastive attentional pooling on top. All model weights including pooling layers are directly loaded from an image-text CoCa pretrained model. Without any video or video-text data, VideoCoCa's zero-shot transfer baseline already achieves state-of-the-art results on zero-shot video classification on Kinetics 400/600/700, UCF101, HMDB51, and Charades, as well as zero-shot text-to-video retrieval on MSR-VTT and ActivityNet Captions. We also explore lightweight finetuning on top of VideoCoCa, and achieve strong results on video question-answering (iVQA, MSRVTT-QA, MSVD-QA) and video captioning (MSR-VTT, ActivityNet, Youcook2). Our approach establishes a simple and effective video-text baseline for future research.
Fast Online Hashing with Multi-Label Projection
Dec 03, 2022



Hashing has been widely researched to solve the large-scale approximate nearest neighbor search problem owing to its time and storage superiority. In recent years, a number of online hashing methods have emerged, which can update the hash functions to adapt to the new stream data and realize dynamic retrieval. However, existing online hashing methods are required to update the whole database with the latest hash functions when a query arrives, which leads to low retrieval efficiency with the continuous increase of the stream data. On the other hand, these methods ignore the supervision relationship among the examples, especially in the multi-label case. In this paper, we propose a novel Fast Online Hashing (FOH) method which only updates the binary codes of a small part of the database. To be specific, we first build a query pool in which the nearest neighbors of each central point are recorded. When a new query arrives, only the binary codes of the corresponding potential neighbors are updated. In addition, we create a similarity matrix which takes the multi-label supervision information into account and bring in the multi-label projection loss to further preserve the similarity among the multi-label data. The experimental results on two common benchmarks show that the proposed FOH can achieve dramatic superiority on query time up to 6.28 seconds less than state-of-the-art baselines with competitive retrieval accuracy.
Knowledge-grounded Dialog State Tracking
Oct 13, 2022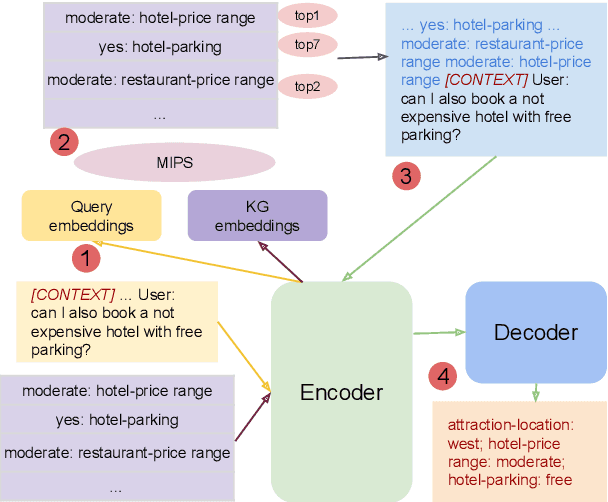
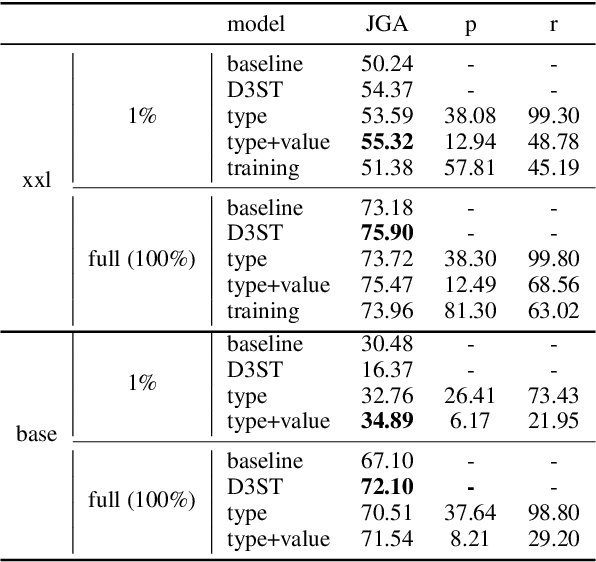
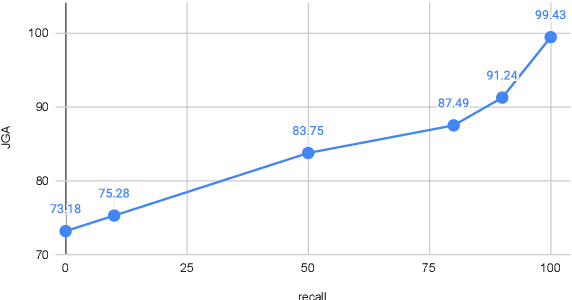
Knowledge (including structured knowledge such as schema and ontology, and unstructured knowledge such as web corpus) is a critical part of dialog understanding, especially for unseen tasks and domains. Traditionally, such domain-specific knowledge is encoded implicitly into model parameters for the execution of downstream tasks, which makes training inefficient. In addition, such models are not easily transferable to new tasks with different schemas. In this work, we propose to perform dialog state tracking grounded on knowledge encoded externally. We query relevant knowledge of various forms based on the dialog context where such information can ground the prediction of dialog states. We demonstrate superior performance of our proposed method over strong baselines, especially in the few-shot learning setting.
ReAct: Synergizing Reasoning and Acting in Language Models
Oct 06, 2022
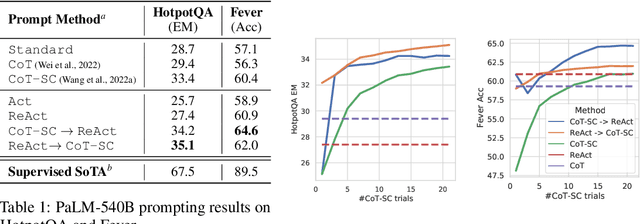

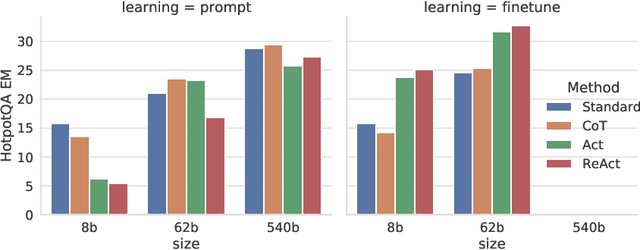
While large language models (LLMs) have demonstrated impressive capabilities across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-thought prompting) and acting (e.g. action plan generation) have primarily been studied as separate topics. In this paper, we explore the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plans as well as handle exceptions, while actions allow it to interface with external sources, such as knowledge bases or environments, to gather additional information. We apply our approach, named ReAct, to a diverse set of language and decision making tasks and demonstrate its effectiveness over state-of-the-art baselines, as well as improved human interpretability and trustworthiness over methods without reasoning or acting components. Concretely, on question answering (HotpotQA) and fact verification (Fever), ReAct overcomes issues of hallucination and error propagation prevalent in chain-of-thought reasoning by interacting with a simple Wikipedia API, and generates human-like task-solving trajectories that are more interpretable than baselines without reasoning traces. On two interactive decision making benchmarks (ALFWorld and WebShop), ReAct outperforms imitation and reinforcement learning methods by an absolute success rate of 34% and 10% respectively, while being prompted with only one or two in-context examples.
Multiple Descent in the Multiple Random Feature Model
Aug 21, 2022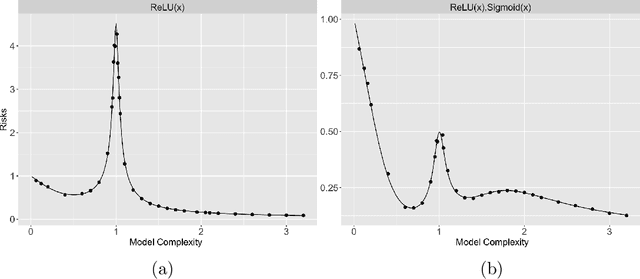
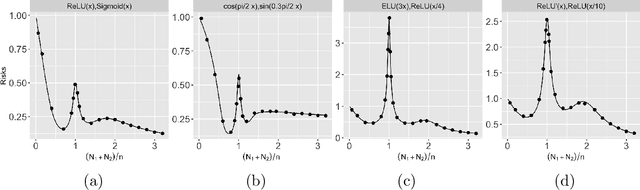
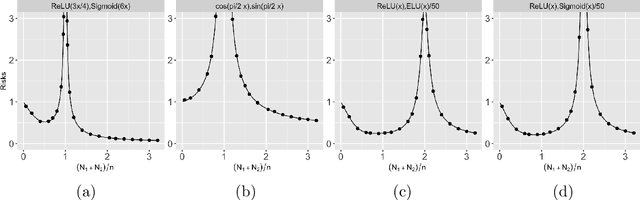
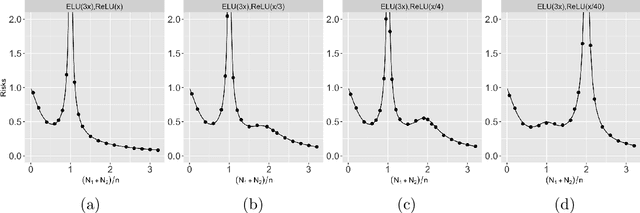
Recent works have demonstrated a double descent phenomenon in over-parameterized learning: as the number of model parameters increases, the excess risk has a $\mathsf{U}$-shape at beginning, then decreases again when the model is highly over-parameterized. Although this phenomenon has been investigated by recent works under different settings such as linear models, random feature models and kernel methods, it has not been fully understood in theory. In this paper, we consider a double random feature model (DRFM) consisting of two types of random features, and study the excess risk achieved by the DRFM in ridge regression. We calculate the precise limit of the excess risk under the high dimensional framework where the training sample size, the dimension of data, and the dimension of random features tend to infinity proportionally. Based on the calculation, we demonstrate that the risk curves of DRFMs can exhibit triple descent. We then provide an explanation of the triple descent phenomenon, and discuss how the ratio between random feature dimensions, the regularization parameter and the signal-to-noise ratio control the shape of the risk curves of DRFMs. At last, we extend our study to the multiple random feature model (MRFM), and show that MRFMs with $K$ types of random features may exhibit $(K+1)$-fold descent. Our analysis points out that risk curves with a specific number of descent generally exist in random feature based regression. Another interesting finding is that our result can recover the risk peak locations reported in the literature when learning neural networks are in the "neural tangent kernel" regime.