 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Know More Than They Can Explain: Quantifying Knowledge Transfer in Human-AI Collaboration
Jun 05, 2025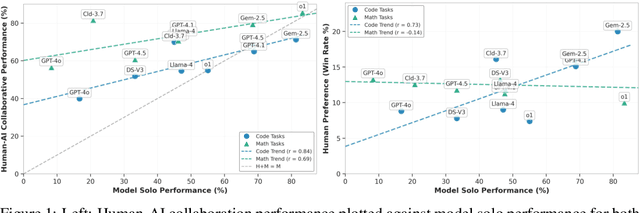



Recent advancements in AI reasoning have driven substantial improvements across diverse tasks. A critical open question is whether these improvements also yields better knowledge transfer: the ability of models to communicate reasoning in ways humans can understand, apply, and learn from. To investigate this, we introduce Knowledge Integration and Transfer Evaluation (KITE), a conceptual and experimental framework for Human-AI knowledge transfer capabilities and conduct the first large-scale human study (N=118) explicitly designed to measure it. In our two-phase setup, humans first ideate with an AI on problem-solving strategies, then independently implement solutions, isolating model explanations' influence on human understanding. Our findings reveal that although model benchmark performance correlates with collaborative outcomes, this relationship is notably inconsistent, featuring significant outliers, indicating that knowledge transfer requires dedicated optimization. Our analysis identifies behavioral and strategic factors mediating successful knowledge transfer. We release our code, dataset, and evaluation framework to support future work on communicatively aligned models.
SWE-smith: Scaling Data for Software Engineering Agents
Apr 30, 2025Despite recent progress in Language Models (LMs) for software engineering, collecting training data remains a significant pain point. Existing datasets are small, with at most 1,000s of training instances from 11 or fewer GitHub repositories. The procedures to curate such datasets are often complex, necessitating hundreds of hours of human labor; companion execution environments also take up several terabytes of storage, severely limiting their scalability and usability. To address this pain point, we introduce SWE-smith, a novel pipeline for generating software engineering training data at scale. Given any Python codebase, SWE-smith constructs a corresponding execution environment, then automatically synthesizes 100s to 1,000s of task instances that break existing test(s) in the codebase. Using SWE-smith, we create a dataset of 50k instances sourced from 128 GitHub repositories, an order of magnitude larger than all previous works. We train SWE-agent-LM-32B, achieving 40.2% Pass@1 resolve rate on the SWE-bench Verified benchmark, state of the art among open source models. We open source SWE-smith (collection procedure, task instances, trajectories, models) to lower the barrier of entry for research in LM systems for automated software engineering. All assets available at https://swesmith.com.
IMPersona: Evaluating Individual Level LM Impersonation
Apr 08, 2025

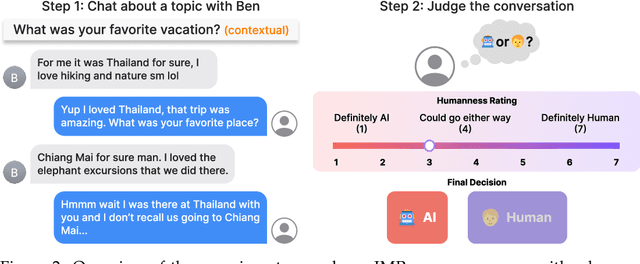

As language models achieve increasingly human-like capabilities in conversational text generation, a critical question emerges: to what extent can these systems simulate the characteristics of specific individuals? To evaluate this, we introduce IMPersona, a framework for evaluating LMs at impersonating specific individuals' writing style and personal knowledge. Using supervised fine-tuning and a hierarchical memory-inspired retrieval system, we demonstrate that even modestly sized open-source models, such as Llama-3.1-8B-Instruct, can achieve impersonation abilities at concerning levels. In blind conversation experiments, participants (mis)identified our fine-tuned models with memory integration as human in 44.44% of interactions, compared to just 25.00% for the best prompting-based approach. We analyze these results to propose detection methods and defense strategies against such impersonation attempts. Our findings raise important questions about both the potential applications and risks of personalized language models, particularly regarding privacy, security, and the ethical deployment of such technologies in real-world contexts.
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
Oct 04, 2024



Autonomous systems for software engineering are now capable of fixing bugs and developing features. These systems are commonly evaluated on SWE-bench (Jimenez et al., 2024a), which assesses their ability to solve software issues from GitHub repositories. However, SWE-bench uses only Python repositories, with problem statements presented predominantly as text and lacking visual elements such as images. This limited coverage motivates our inquiry into how existing systems might perform on unrepresented software engineering domains (e.g., front-end, game development, DevOps), which use different programming languages and paradigms. Therefore, we propose SWE-bench Multimodal (SWE-bench M), to evaluate systems on their ability to fix bugs in visual, user-facing JavaScript software. SWE-bench M features 617 task instances collected from 17 JavaScript libraries used for web interface design, diagramming, data visualization, syntax highlighting, and interactive mapping. Each SWE-bench M task instance contains at least one image in its problem statement or unit tests. Our analysis finds that top-performing SWE-bench systems struggle with SWE-bench M, revealing limitations in visual problem-solving and cross-language generalization. Lastly, we show that SWE-agent's flexible language-agnostic features enable it to substantially outperform alternatives on SWE-bench M, resolving 12% of task instances compared to 6% for the next best system.
EnIGMA: Enhanced Interactive Generative Model Agent for CTF Challenges
Sep 24, 2024



Although language model (LM) agents are demonstrating growing potential in many domains, their success in cybersecurity has been limited due to simplistic design and the lack of fundamental features for this domain. We present EnIGMA, an LM agent for autonomously solving Capture The Flag (CTF) challenges. EnIGMA introduces new Agent-Computer Interfaces (ACIs) to improve the success rate on CTF challenges. We establish the novel Interactive Agent Tool concept, which enables LM agents to run interactive command-line utilities essential for these challenges. Empirical analysis of EnIGMA on over 350 CTF challenges from three different benchmarks indicates that providing a robust set of new tools with demonstration of their usage helps the LM solve complex problems and achieves state-of-the-art results on the NYU CTF and Intercode-CTF benchmarks. Finally, we discuss insights on ACI design and agent behavior on cybersecurity tasks that highlight the need to adapt real-world tools for LM agents.
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Oct 10, 2023



Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We consider real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. We therefore introduce SWE-bench, an evaluation framework including $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. Claude 2 and GPT-4 solve a mere $4.8$% and $1.7$% of instances respectively, even when provided with an oracle retriever. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
CSTS: Conditional Semantic Textual Similarity
May 24, 2023



Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). As an example, the similarity between the sentences "The NBA player shoots a three-pointer." and "A man throws a tennis ball into the air to serve." is higher for the condition "The motion of the ball." (both upward) and lower for "The size of the ball." (one large and one small). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we evaluate several state-of-the-art models to demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging, with Spearman correlation scores of <50. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding.
MUX-PLMs: Pre-training Language Models with Data Multiplexing
Feb 24, 2023



Data multiplexing is a recently proposed method for improving a model's inference efficiency by processing multiple instances simultaneously using an ordered representation mixture. Prior work on data multiplexing only used task-specific Transformers without any pre-training, which limited their accuracy and generality. In this paper, we develop pre-trained multiplexed language models (MUX-PLMs) that can be widely finetuned on any downstream task. Our approach includes a three-stage training procedure and novel multiplexing and demultiplexing modules for improving throughput and downstream task accuracy. We demonstrate our method on BERT and ELECTRA pre-training objectives, with our MUX-BERT and MUX-ELECTRA models achieving 2x/5x inference speedup with a 2-4 \% drop in absolute performance on GLUE and 1-2 \% drop on token-level tasks.
CARETS: A Consistency And Robustness Evaluative Test Suite for VQA
Mar 15, 2022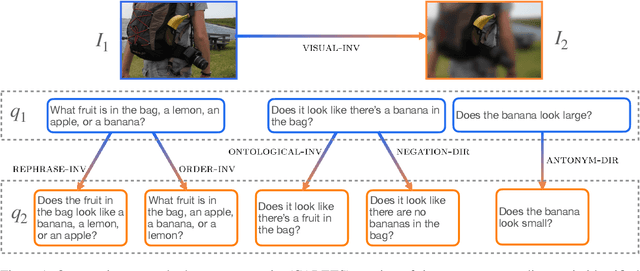
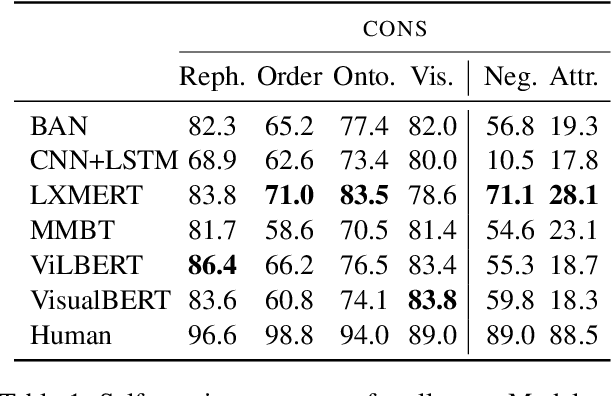
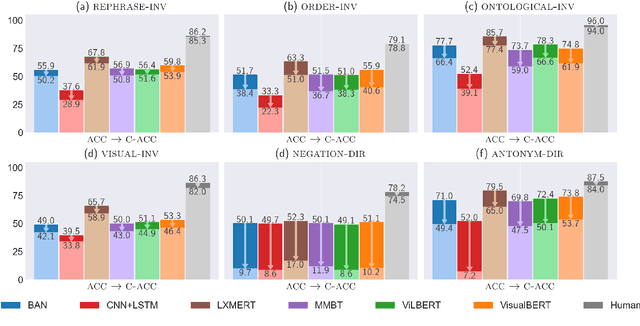
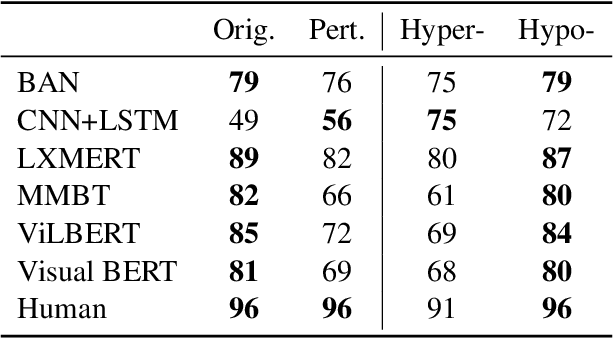
We introduce CARETS, a systematic test suite to measure consistency and robustness of modern VQA models through a series of six fine-grained capability tests. In contrast to existing VQA test sets, CARETS features balanced question generation to create pairs of instances to test models, with each pair focusing on a specific capability such as rephrasing, logical symmetry or image obfuscation. We evaluate six modern VQA systems on CARETS and identify several actionable weaknesses in model comprehension, especially with concepts such as negation, disjunction, or hypernym invariance. Interestingly, even the most sophisticated models are sensitive to aspects such as swapping the order of terms in a conjunction or varying the number of answer choices mentioned in the question. We release CARETS to be used as an extensible tool for evaluating multi-modal model robustness.
DataMUX: Data Multiplexing for Neural Networks
Feb 18, 2022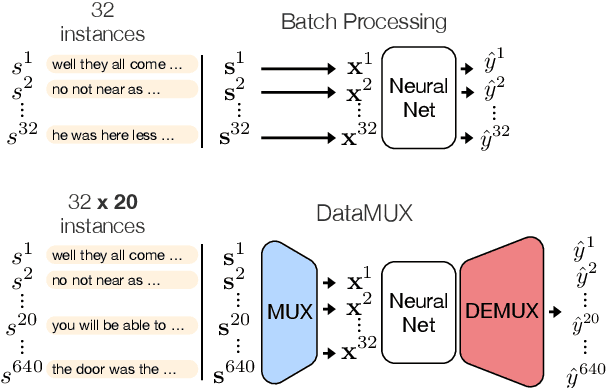
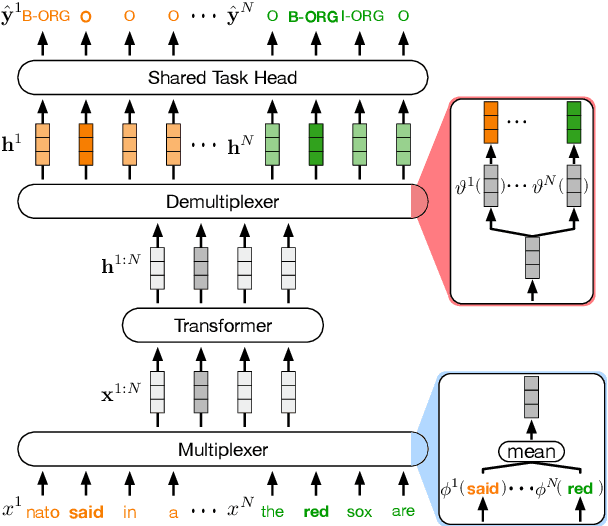
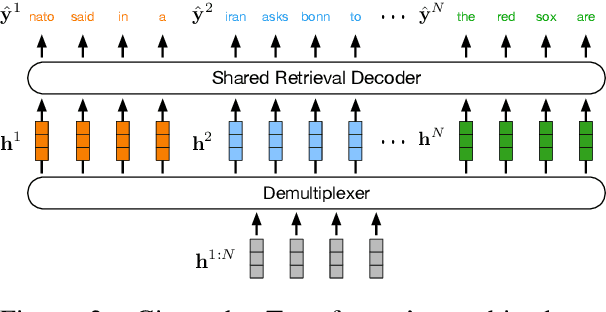
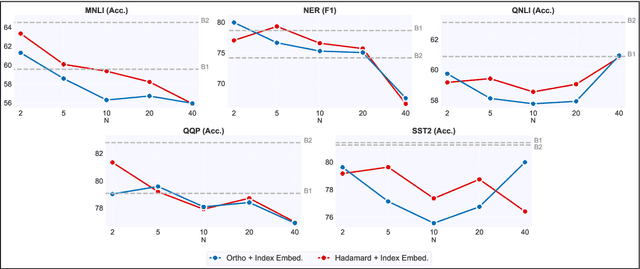
In this paper, we introduce data multiplexing (DataMUX), a technique that enables deep neural networks to process multiple inputs simultaneously using a single compact representation. DataMUX demonstrates that neural networks are capable of generating accurate predictions over mixtures of inputs, resulting in increased throughput with minimal extra memory requirements. Our approach uses two key components -- 1) a multiplexing layer that performs a fixed linear transformation to each input before combining them to create a mixed representation of the same size as a single input, which is then processed by the base network, and 2) a demultiplexing layer that converts the base network's output back into independent representations before producing predictions for each input. We show the viability of DataMUX for different architectures (Transformers, and to a lesser extent MLPs and CNNs) across six different tasks spanning sentence classification, named entity recognition and image classification. For instance, DataMUX for Transformers can multiplex up to $20$x/$40$x inputs, achieving $11$x/$18$x increase in throughput with minimal absolute performance drops of $<2\%$ and $<4\%$ respectively on MNLI, a natural language inference task. We also provide a theoretical construction for multiplexing in self-attention networks and analyze the effect of various design elements in DataMUX.