 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Agentic Reasoning with Retrieval via Synthetic Semantic Information Gain Reward
Jan 31, 2026Agentic reasoning enables large reasoning models (LRMs) to dynamically acquire external knowledge, but yet optimizing the retrieval process remains challenging due to the lack of dense, principled reward signals. In this paper, we introduce InfoReasoner, a unified framework that incentivizes effective information seeking via a synthetic semantic information gain reward. Theoretically, we redefine information gain as uncertainty reduction over the model's belief states, establishing guarantees, including non-negativity, telescoping additivity, and channel monotonicity. Practically, to enable scalable optimization without manual retrieval annotations, we propose an output-aware intrinsic estimator that computes information gain directly from the model's output distributions using semantic clustering via bidirectional textual entailment. This intrinsic reward guides the policy to maximize epistemic progress, enabling efficient training via Group Relative Policy Optimxization (GRPO). Experiments across seven question-answering benchmarks demonstrate that InfoReasoner consistently outperforms strong retrieval-augmented baselines, achieving up to 5.4% average accuracy improvement. Our work provides a theoretically grounded and scalable path toward agentic reasoning with retrieval.
DSP-Reg: Domain-Sensitive Parameter Regularization for Robust Domain Generalization
Jan 27, 2026Domain Generalization (DG) is a critical area that focuses on developing models capable of performing well on data from unseen distributions, which is essential for real-world applications. Existing approaches primarily concentrate on learning domain-invariant features, which assume that a model robust to variations in the source domains will generalize well to unseen target domains. However, these approaches neglect a deeper analysis at the parameter level, which makes the model hard to explicitly differentiate between parameters sensitive to domain shifts and those robust, potentially hindering its overall ability to generalize. In order to address these limitations, we first build a covariance-based parameter sensitivity analysis framework to quantify the sensitivity of each parameter in a model to domain shifts. By computing the covariance of parameter gradients across multiple source domains, we can identify parameters that are more susceptible to domain variations, which serves as our theoretical foundation. Based on this, we propose Domain-Sensitive Parameter Regularization (DSP-Reg), a principled framework that guides model optimization by a soft regularization technique that encourages the model to rely more on domain-invariant parameters while suppressing those that are domain-specific. This approach provides a more granular control over the model's learning process, leading to improved robustness and generalization to unseen domains. Extensive experiments on benchmarks, such as PACS, VLCS, OfficeHome, and DomainNet, demonstrate that DSP-Reg outperforms state-of-the-art approaches, achieving an average accuracy of 66.7\% and surpassing all baselines.
SIRR-LMM: Single-image Reflection Removal via Large Multimodal Model
Jan 12, 2026Glass surfaces create complex interactions of reflected and transmitted light, making single-image reflection removal (SIRR) challenging. Existing datasets suffer from limited physical realism in synthetic data or insufficient scale in real captures. We introduce a synthetic dataset generation framework that path-traces 3D glass models over real background imagery to create physically accurate reflection scenarios with varied glass properties, camera settings, and post-processing effects. To leverage the capabilities of Large Multimodal Model (LMM), we concatenate the image layers into a single composite input, apply joint captioning, and fine-tune the model using task-specific LoRA rather than full-parameter training. This enables our approach to achieve improved reflection removal and separation performance compared to state-of-the-art methods.
Rethinking Table Pruning in TableQA: From Sequential Revisions to Gold Trajectory-Supervised Parallel Search
Jan 07, 2026Table Question Answering (TableQA) benefits significantly from table pruning, which extracts compact sub-tables by eliminating redundant cells to streamline downstream reasoning. However, existing pruning methods typically rely on sequential revisions driven by unreliable critique signals, often failing to detect the loss of answer-critical data. To address this limitation, we propose TabTrim, a novel table pruning framework which transforms table pruning from sequential revisions to gold trajectory-supervised parallel search. TabTrim derives a gold pruning trajectory using the intermediate sub-tables in the execution process of gold SQL queries, and trains a pruner and a verifier to make the step-wise pruning result align with the gold pruning trajectory. During inference, TabTrim performs parallel search to explore multiple candidate pruning trajectories and identify the optimal sub-table. Extensive experiments demonstrate that TabTrim achieves state-of-the-art performance across diverse tabular reasoning tasks: TabTrim-8B reaches 73.5% average accuracy, outperforming the strongest baseline by 3.2%, including 79.4% on WikiTQ and 61.2% on TableBench.
LLHA-Net: A Hierarchical Attention Network for Two-View Correspondence Learning
Dec 31, 2025Establishing the correct correspondence of feature points is a fundamental task in computer vision. However, the presence of numerous outliers among the feature points can significantly affect the matching results, reducing the accuracy and robustness of the process. Furthermore, a challenge arises when dealing with a large proportion of outliers: how to ensure the extraction of high-quality information while reducing errors caused by negative samples. To address these issues, in this paper, we propose a novel method called Layer-by-Layer Hierarchical Attention Network, which enhances the precision of feature point matching in computer vision by addressing the issue of outliers. Our method incorporates stage fusion, hierarchical extraction, and an attention mechanism to improve the network's representation capability by emphasizing the rich semantic information of feature points. Specifically, we introduce a layer-by-layer channel fusion module, which preserves the feature semantic information from each stage and achieves overall fusion, thereby enhancing the representation capability of the feature points. Additionally, we design a hierarchical attention module that adaptively captures and fuses global perception and structural semantic information using an attention mechanism. Finally, we propose two architectures to extract and integrate features, thereby improving the adaptability of our network. We conduct experiments on two public datasets, namely YFCC100M and SUN3D, and the results demonstrate that our proposed method outperforms several state-of-the-art techniques in both outlier removal and camera pose estimation. Source code is available at http://www.linshuyuan.com.
Shared Spatial Memory Through Predictive Coding
Nov 06, 2025



Sharing and reconstructing a consistent spatial memory is a critical challenge in multi-agent systems, where partial observability and limited bandwidth often lead to catastrophic failures in coordination. We introduce a multi-agent predictive coding framework that formulate coordination as the minimization of mutual uncertainty among agents. Instantiated as an information bottleneck objective, it prompts agents to learn not only who and what to communicate but also when. At the foundation of this framework lies a grid-cell-like metric as internal spatial coding for self-localization, emerging spontaneously from self-supervised motion prediction. Building upon this internal spatial code, agents gradually develop a bandwidth-efficient communication mechanism and specialized neural populations that encode partners' locations: an artificial analogue of hippocampal social place cells (SPCs). These social representations are further enacted by a hierarchical reinforcement learning policy that actively explores to reduce joint uncertainty. On the Memory-Maze benchmark, our approach shows exceptional resilience to bandwidth constraints: success degrades gracefully from 73.5% to 64.4% as bandwidth shrinks from 128 to 4 bits/step, whereas a full-broadcast baseline collapses from 67.6% to 28.6%. Our findings establish a theoretically principled and biologically plausible basis for how complex social representations emerge from a unified predictive drive, leading to social collective intelligence.
NWaaS: Nonintrusive Watermarking as a Service for X-to-Image DNN
Jul 24, 2025The intellectual property of deep neural network (DNN) models can be protected with DNN watermarking, which embeds copyright watermarks into model parameters (white-box), model behavior (black-box), or model outputs (box-free), and the watermarks can be subsequently extracted to verify model ownership or detect model theft. Despite recent advances, these existing methods are inherently intrusive, as they either modify the model parameters or alter the structure. This natural intrusiveness raises concerns about watermarking-induced shifts in model behavior and the additional cost of fine-tuning, further exacerbated by the rapidly growing model size. As a result, model owners are often reluctant to adopt DNN watermarking in practice, which limits the development of practical Watermarking as a Service (WaaS) systems. To address this issue, we introduce Nonintrusive Watermarking as a Service (NWaaS), a novel trustless paradigm designed for X-to-Image models, in which we hypothesize that with the model untouched, an owner-defined watermark can still be extracted from model outputs. Building on this concept, we propose ShadowMark, a concrete implementation of NWaaS which addresses critical deployment challenges by establishing a robust and nonintrusive side channel in the protected model's black-box API, leveraging a key encoder and a watermark decoder. It is significantly distinctive from existing solutions by attaining the so-called absolute fidelity and being applicable to different DNN architectures, while being also robust against existing attacks, eliminating the fidelity-robustness trade-off. Extensive experiments on image-to-image, noise-to-image, noise-and-text-to-image, and text-to-image models, demonstrate the efficacy and practicality of ShadowMark for real-world deployment of nonintrusive DNN watermarking.
UltraVSR: Achieving Ultra-Realistic Video Super-Resolution with Efficient One-Step Diffusion Space
May 26, 2025Diffusion models have shown great potential in generating realistic image detail. However, adapting these models to video super-resolution (VSR) remains challenging due to their inherent stochasticity and lack of temporal modeling. In this paper, we propose UltraVSR, a novel framework that enables ultra-realistic and temporal-coherent VSR through an efficient one-step diffusion space. A central component of UltraVSR is the Degradation-aware Restoration Schedule (DRS), which estimates a degradation factor from the low-resolution input and transforms iterative denoising process into a single-step reconstruction from from low-resolution to high-resolution videos. This design eliminates randomness from diffusion noise and significantly speeds up inference. To ensure temporal consistency, we propose a lightweight yet effective Recurrent Temporal Shift (RTS) module, composed of an RTS-convolution unit and an RTS-attention unit. By partially shifting feature components along the temporal dimension, these two units collaboratively facilitate effective feature propagation, fusion, and alignment across neighboring frames, without relying on explicit temporal layers. The RTS module is integrated into a pretrained text-to-image diffusion model and is further enhanced through Spatio-temporal Joint Distillation (SJD), which improves temporal coherence while preserving realistic details. Additionally, we introduce a Temporally Asynchronous Inference (TAI) strategy to capture long-range temporal dependencies under limited memory constraints. Extensive experiments show that UltraVSR achieves state-of-the-art performance, both qualitatively and quantitatively, in a single sampling step.
Instruct2See: Learning to Remove Any Obstructions Across Distributions
May 23, 2025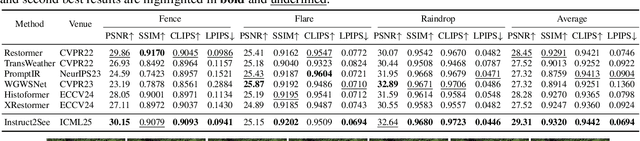
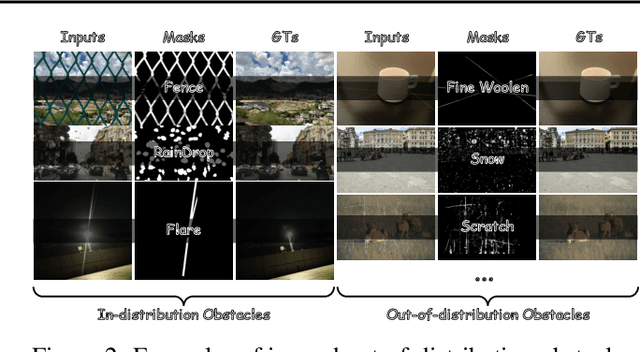
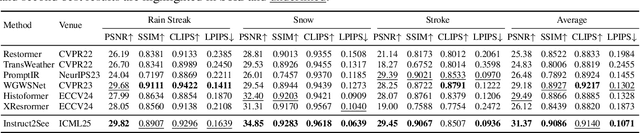
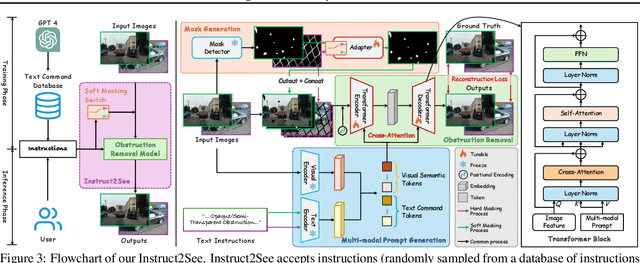
Images are often obstructed by various obstacles due to capture limitations, hindering the observation of objects of interest. Most existing methods address occlusions from specific elements like fences or raindrops, but are constrained by the wide range of real-world obstructions, making comprehensive data collection impractical. To overcome these challenges, we propose Instruct2See, a novel zero-shot framework capable of handling both seen and unseen obstacles. The core idea of our approach is to unify obstruction removal by treating it as a soft-hard mask restoration problem, where any obstruction can be represented using multi-modal prompts, such as visual semantics and textual instructions, processed through a cross-attention unit to enhance contextual understanding and improve mode control. Additionally, a tunable mask adapter allows for dynamic soft masking, enabling real-time adjustment of inaccurate masks. Extensive experiments on both in-distribution and out-of-distribution obstacles show that Instruct2See consistently achieves strong performance and generalization in obstruction removal, regardless of whether the obstacles were present during the training phase. Code and dataset are available at https://jhscut.github.io/Instruct2See.
Expanding Zero-Shot Object Counting with Rich Prompts
May 21, 2025Expanding pre-trained zero-shot counting models to handle unseen categories requires more than simply adding new prompts, as this approach does not achieve the necessary alignment between text and visual features for accurate counting. We introduce RichCount, the first framework to address these limitations, employing a two-stage training strategy that enhances text encoding and strengthens the model's association with objects in images. RichCount improves zero-shot counting for unseen categories through two key objectives: (1) enriching text features with a feed-forward network and adapter trained on text-image similarity, thereby creating robust, aligned representations; and (2) applying this refined encoder to counting tasks, enabling effective generalization across diverse prompts and complex images. In this manner, RichCount goes beyond simple prompt expansion to establish meaningful feature alignment that supports accurate counting across novel categories. Extensive experiments on three benchmark datasets demonstrate the effectiveness of RichCount, achieving state-of-the-art performance in zero-shot counting and significantly enhancing generalization to unseen categories in open-world scenarios.