 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Automated Perceptual Voice Quality Assessment with Speech Foundation Models
May 28, 2025



Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders. Traditionally, expert raters use scales such as the CAPE-V and GRBAS. However, these are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes VOQANet, a deep learning framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To improve robustness and interpretability, we introduce VOQANet+, which integrates handcrafted acoustic features such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior work focusing only on vowel-based phonation (PVQD-A subset) from the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) for better generalizability. Results show that sentence-based input outperforms vowel-based input, particularly at the patient level, highlighting the benefit of longer utterances for capturing voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error and Pearson correlation across CAPE-V and GRBAS dimensions, with VOQANet+ achieving further improvements. Additional tests under noisy conditions show that VOQANet+ maintains high prediction accuracy, supporting its use in real-world and telehealth settings. These findings demonstrate the value of combining SFM embeddings with domain-informed acoustic features for interpretable and robust voice quality assessment.
Universal Speech Enhancement with Regression and Generative Mamba
May 27, 2025



The Interspeech 2025 URGENT Challenge aimed to advance universal, robust, and generalizable speech enhancement by unifying speech enhancement tasks across a wide variety of conditions, including seven different distortion types and five languages. We present Universal Speech Enhancement Mamba (USEMamba), a state-space speech enhancement model designed to handle long-range sequence modeling, time-frequency structured processing, and sampling frequency-independent feature extraction. Our approach primarily relies on regression-based modeling, which performs well across most distortions. However, for packet loss and bandwidth extension, where missing content must be inferred, a generative variant of the proposed USEMamba proves more effective. Despite being trained on only a subset of the full training data, USEMamba achieved 2nd place in Track 1 during the blind test phase, demonstrating strong generalization across diverse conditions.
Cross-modal Knowledge Transfer Learning as Graph Matching Based on Optimal Transport for ASR
May 19, 2025Transferring linguistic knowledge from a pretrained language model (PLM) to acoustic feature learning has proven effective in enhancing end-to-end automatic speech recognition (E2E-ASR). However, aligning representations between linguistic and acoustic modalities remains a challenge due to inherent modality gaps. Optimal transport (OT) has shown promise in mitigating these gaps by minimizing the Wasserstein distance (WD) between linguistic and acoustic feature distributions. However, previous OT-based methods overlook structural relationships, treating feature vectors as unordered sets. To address this, we propose Graph Matching Optimal Transport (GM-OT), which models linguistic and acoustic sequences as structured graphs. Nodes represent feature embeddings, while edges capture temporal and sequential relationships. GM-OT minimizes both WD (between nodes) and Gromov-Wasserstein distance (GWD) (between edges), leading to a fused Gromov-Wasserstein distance (FGWD) formulation. This enables structured alignment and more efficient knowledge transfer compared to existing OT-based approaches. Theoretical analysis further shows that prior OT-based methods in linguistic knowledge transfer can be viewed as a special case within our GM-OT framework. We evaluate GM-OT on Mandarin ASR using a CTC-based E2E-ASR system with a PLM for knowledge transfer. Experimental results demonstrate significant performance gains over state-of-the-art models, validating the effectiveness of our approach.
QualiSpeech: A Speech Quality Assessment Dataset with Natural Language Reasoning and Descriptions
Mar 26, 2025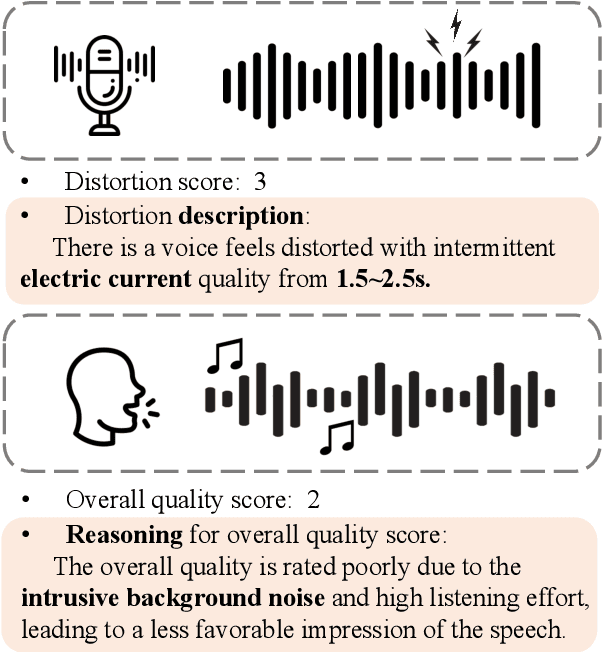
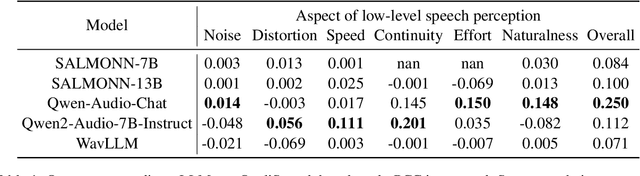
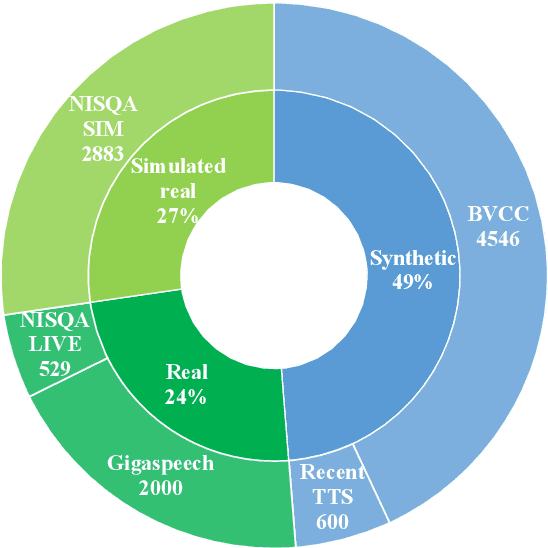
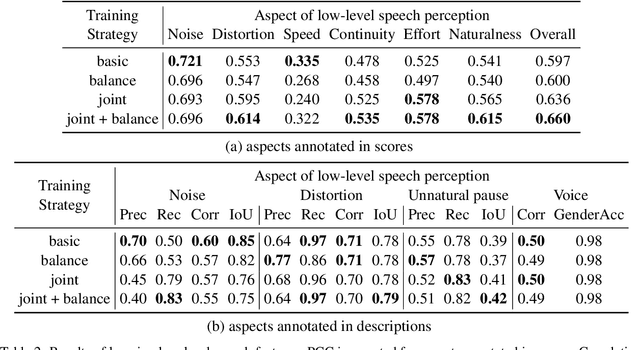
This paper explores a novel perspective to speech quality assessment by leveraging natural language descriptions, offering richer, more nuanced insights than traditional numerical scoring methods. Natural language feedback provides instructive recommendations and detailed evaluations, yet existing datasets lack the comprehensive annotations needed for this approach. To bridge this gap, we introduce QualiSpeech, a comprehensive low-level speech quality assessment dataset encompassing 11 key aspects and detailed natural language comments that include reasoning and contextual insights. Additionally, we propose the QualiSpeech Benchmark to evaluate the low-level speech understanding capabilities of auditory large language models (LLMs). Experimental results demonstrate that finetuned auditory LLMs can reliably generate detailed descriptions of noise and distortion, effectively identifying their types and temporal characteristics. The results further highlight the potential for incorporating reasoning to enhance the accuracy and reliability of quality assessments. The dataset will be released at https://huggingface.co/datasets/tsinghua-ee/QualiSpeech.
Linguistic Knowledge Transfer Learning for Speech Enhancement
Mar 10, 2025Linguistic knowledge plays a crucial role in spoken language comprehension. It provides essential semantic and syntactic context for speech perception in noisy environments. However, most speech enhancement (SE) methods predominantly rely on acoustic features to learn the mapping relationship between noisy and clean speech, with limited exploration of linguistic integration. While text-informed SE approaches have been investigated, they often require explicit speech-text alignment or externally provided textual data, constraining their practicality in real-world scenarios. Additionally, using text as input poses challenges in aligning linguistic and acoustic representations due to their inherent differences. In this study, we propose the Cross-Modality Knowledge Transfer (CMKT) learning framework, which leverages pre-trained large language models (LLMs) to infuse linguistic knowledge into SE models without requiring text input or LLMs during inference. Furthermore, we introduce a misalignment strategy to improve knowledge transfer. This strategy applies controlled temporal shifts, encouraging the model to learn more robust representations. Experimental evaluations demonstrate that CMKT consistently outperforms baseline models across various SE architectures and LLM embeddings, highlighting its adaptability to different configurations. Additionally, results on Mandarin and English datasets confirm its effectiveness across diverse linguistic conditions, further validating its robustness. Moreover, CMKT remains effective even in scenarios without textual data, underscoring its practicality for real-world applications. By bridging the gap between linguistic and acoustic modalities, CMKT offers a scalable and innovative solution for integrating linguistic knowledge into SE models, leading to substantial improvements in both intelligibility and enhancement performance.
Transfer Learning for Keypoint Detection in Low-Resolution Thermal TUG Test Images
Jan 30, 2025This study presents a novel approach to human keypoint detection in low-resolution thermal images using transfer learning techniques. We introduce the first application of the Timed Up and Go (TUG) test in thermal image computer vision, establishing a new paradigm for mobility assessment. Our method leverages a MobileNetV3-Small encoder and a ViTPose decoder, trained using a composite loss function that balances latent representation alignment and heatmap accuracy. The model was evaluated using the Object Keypoint Similarity (OKS) metric from the COCO Keypoint Detection Challenge. The proposed model achieves better performance with AP, AP50, and AP75 scores of 0.861, 0.942, and 0.887 respectively, outperforming traditional supervised learning approaches like Mask R-CNN and ViTPose-Base. Moreover, our model demonstrates superior computational efficiency in terms of parameter count and FLOPS. This research lays a solid foundation for future clinical applications of thermal imaging in mobility assessment and rehabilitation monitoring.
CodecFake-Omni: A Large-Scale Codec-based Deepfake Speech Dataset
Jan 14, 2025



With the rapid advancement of codec-based speech generation (CoSG) systems, creating fake speech that mimics an individual's identity and spreads misinformation has become remarkably easy. Addressing the risks posed by such deepfake speech has attracted significant attention. However, most existing studies focus on detecting fake data generated by traditional speech generation models. Research on detecting fake speech generated by CoSG systems remains limited and largely unexplored. In this paper, we introduce CodecFake-Omni, a large-scale dataset specifically designed to advance the study of neural codec-based deepfake speech (CodecFake) detection and promote progress within the anti-spoofing community. To the best of our knowledge, CodecFake-Omni is the largest dataset of its kind till writing this paper, encompassing the most diverse range of codec architectures. The training set is generated through re-synthesis using nearly all publicly available open-source 31 neural audio codec models across 21 different codec families (one codec family with different configurations will result in multiple different codec models). The evaluation set includes web-sourced data collected from websites generated by 17 advanced CoSG models with eight codec families. Using this large-scale dataset, we reaffirm our previous findings that anti-spoofing models trained on traditional spoofing datasets generated by vocoders struggle to detect synthesized speech from current CoSG systems. Additionally, we propose a comprehensive neural audio codec taxonomy, categorizing neural audio codecs by their root components: vector quantizer, auxiliary objectives, and decoder types, with detailed explanations and representative examples for each. Using this comprehensive taxonomy, we conduct stratified analysis to provide valuable insights for future CodecFake detection research.
Detecting the Undetectable: Assessing the Efficacy of Current Spoof Detection Methods Against Seamless Speech Edits
Jan 07, 2025



Neural speech editing advancements have raised concerns about their misuse in spoofing attacks. Traditional partially edited speech corpora primarily focus on cut-and-paste edits, which, while maintaining speaker consistency, often introduce detectable discontinuities. Recent methods, like A\textsuperscript{3}T and Voicebox, improve transitions by leveraging contextual information. To foster spoofing detection research, we introduce the Speech INfilling Edit (SINE) dataset, created with Voicebox. We detailed the process of re-implementing Voicebox training and dataset creation. Subjective evaluations confirm that speech edited using this novel technique is more challenging to detect than conventional cut-and-paste methods. Despite human difficulty, experimental results demonstrate that self-supervised-based detectors can achieve remarkable performance in detection, localization, and generalization across different edit methods. The dataset and related models will be made publicly available.
MSECG: Incorporating Mamba for Robust and Efficient ECG Super-Resolution
Dec 06, 2024Electrocardiogram (ECG) signals play a crucial role in diagnosing cardiovascular diseases. To reduce power consumption in wearable or portable devices used for long-term ECG monitoring, super-resolution (SR) techniques have been developed, enabling these devices to collect and transmit signals at a lower sampling rate. In this study, we propose MSECG, a compact neural network model designed for ECG SR. MSECG combines the strength of the recurrent Mamba model with convolutional layers to capture both local and global dependencies in ECG waveforms, allowing for the effective reconstruction of high-resolution signals. We also assess the model's performance in real-world noisy conditions by utilizing ECG data from the PTB-XL database and noise data from the MIT-BIH Noise Stress Test Database. Experimental results show that MSECG outperforms two contemporary ECG SR models under both clean and noisy conditions while using fewer parameters, offering a more powerful and robust solution for long-term ECG monitoring applications.
MSEMG: Surface Electromyography Denoising with a Mamba-based Efficient Network
Nov 28, 2024



Surface electromyography (sEMG) recordings can be contaminated by electrocardiogram (ECG) signals when the monitored muscle is closed to the heart. Traditional signal-processing-based approaches, such as high-pass filtering and template subtraction, have been used to remove ECG interference but are often limited in their effectiveness. Recently, neural-network-based methods have shown greater promise for sEMG denoising, but they still struggle to balance both efficiency and effectiveness. In this study, we introduce MSEMG, a novel system that integrates the Mamba State Space Model with a convolutional neural network to serve as a lightweight sEMG denoising model. We evaluated MSEMG using sEMG data from the Non-Invasive Adaptive Prosthetics database and ECG signals from the MIT-BIH Normal Sinus Rhythm Database. The results show that MSEMG outperforms existing methods, generating higher-quality sEMG signals with fewer parameters. The source code for MSEMG is available at https://github.com/tonyliu0910/MSEMG.