 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Speech Enhancement with Regression and Generative Mamba
May 27, 2025



The Interspeech 2025 URGENT Challenge aimed to advance universal, robust, and generalizable speech enhancement by unifying speech enhancement tasks across a wide variety of conditions, including seven different distortion types and five languages. We present Universal Speech Enhancement Mamba (USEMamba), a state-space speech enhancement model designed to handle long-range sequence modeling, time-frequency structured processing, and sampling frequency-independent feature extraction. Our approach primarily relies on regression-based modeling, which performs well across most distortions. However, for packet loss and bandwidth extension, where missing content must be inferred, a generative variant of the proposed USEMamba proves more effective. Despite being trained on only a subset of the full training data, USEMamba achieved 2nd place in Track 1 during the blind test phase, demonstrating strong generalization across diverse conditions.
Robust Speech Recognition with Schrödinger Bridge-Based Speech Enhancement
May 07, 2025



In this work, we investigate application of generative speech enhancement to improve the robustness of ASR models in noisy and reverberant conditions. We employ a recently-proposed speech enhancement model based on Schr\"odinger bridge, which has been shown to perform well compared to diffusion-based approaches. We analyze the impact of model scaling and different sampling methods on the ASR performance. Furthermore, we compare the considered model with predictive and diffusion-based baselines and analyze the speech recognition performance when using different pre-trained ASR models. The proposed approach significantly reduces the word error rate, reducing it by approximately 40% relative to the unprocessed speech signals and by approximately 8% relative to a similarly sized predictive approach.
* 5 pages. Published in ICASSP 2025
Uconv-Conformer: High Reduction of Input Sequence Length for End-to-End Speech Recognition
Aug 16, 2022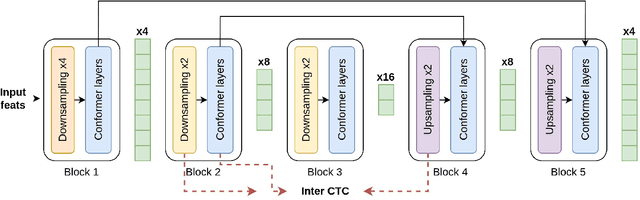
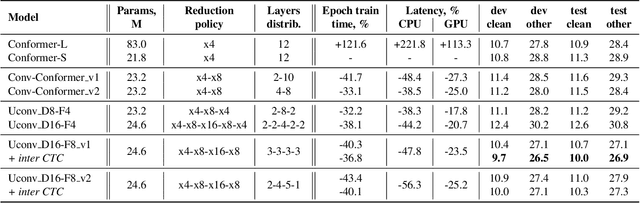
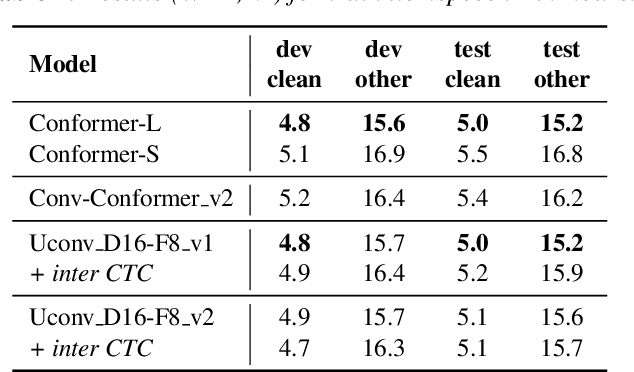
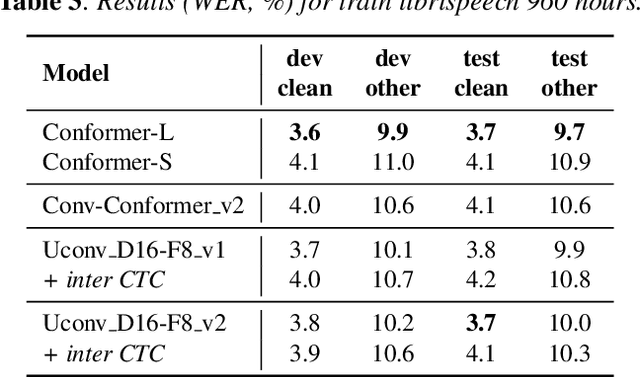
Optimization of modern ASR architectures is among the highest priority tasks since it saves many computational resources for model training and inference. The work proposes a new Uconv-Conformer architecture based on the standard Conformer model that consistently reduces the input sequence length by 16 times, which results in speeding up the work of the intermediate layers. To solve the convergence problem with such a significant reduction of the time dimension, we use upsampling blocks similar to the U-Net architecture to ensure the correct CTC loss calculation and stabilize network training. The Uconv-Conformer architecture appears to be not only faster in terms of training and inference but also shows better WER compared to the baseline Conformer. Our best Uconv-Conformer model showed 40.3% epoch training time reduction, 47.8%, and 23.5% inference acceleration on the CPU and GPU, respectively. Relative WER on Librispeech test_clean and test_other decreased by 7.3% and 9.2%.