 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateRephrase: Zero- and Few-Shot Reduction of Hate Intensity in Online Posts using Large Language Models
Oct 21, 2023



Hate speech has become pervasive in today's digital age. Although there has been considerable research to detect hate speech or generate counter speech to combat hateful views, these approaches still cannot completely eliminate the potential harmful societal consequences of hate speech -- hate speech, even when detected, can often not be taken down or is often not taken down enough; and hate speech unfortunately spreads quickly, often much faster than any generated counter speech. This paper investigates a relatively new yet simple and effective approach of suggesting a rephrasing of potential hate speech content even before the post is made. We show that Large Language Models (LLMs) perform well on this task, outperforming state-of-the-art baselines such as BART-Detox. We develop 4 different prompts based on task description, hate definition, few-shot demonstrations and chain-of-thoughts for comprehensive experiments and conduct experiments on open-source LLMs such as LLaMA-1, LLaMA-2 chat, Vicuna as well as OpenAI's GPT-3.5. We propose various evaluation metrics to measure the efficacy of the generated text and ensure the generated text has reduced hate intensity without drastically changing the semantic meaning of the original text. We find that LLMs with a few-shot demonstrations prompt work the best in generating acceptable hate-rephrased text with semantic meaning similar to the original text. Overall, we find that GPT-3.5 outperforms the baseline and open-source models for all the different kinds of prompts. We also perform human evaluations and interestingly, find that the rephrasings generated by GPT-3.5 outperform even the human-generated ground-truth rephrasings in the dataset. We also conduct detailed ablation studies to investigate why LLMs work satisfactorily on this task and conduct a failure analysis to understand the gaps.
LocSelect: Target Speaker Localization with an Auditory Selective Hearing Mechanism
Oct 17, 2023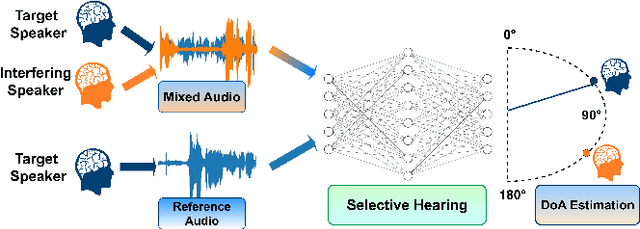
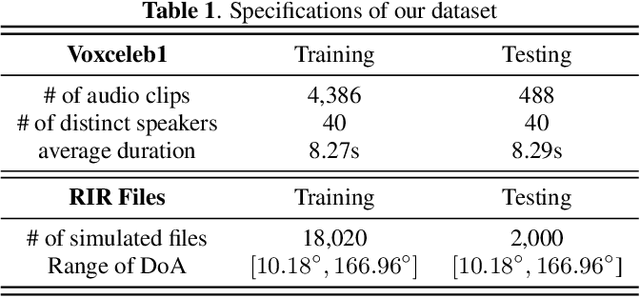
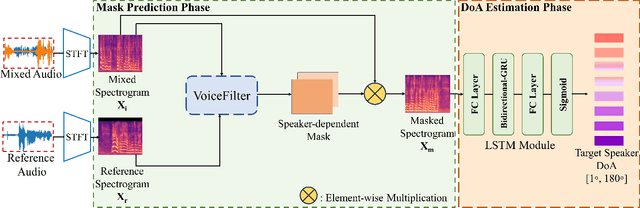
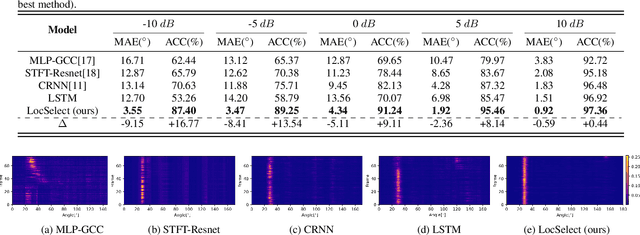
The prevailing noise-resistant and reverberation-resistant localization algorithms primarily emphasize separating and providing directional output for each speaker in multi-speaker scenarios, without association with the identity of speakers. In this paper, we present a target speaker localization algorithm with a selective hearing mechanism. Given a reference speech of the target speaker, we first produce a speaker-dependent spectrogram mask to eliminate interfering speakers' speech. Subsequently, a Long short-term memory (LSTM) network is employed to extract the target speaker's location from the filtered spectrogram. Experiments validate the superiority of our proposed method over the existing algorithms for different scale invariant signal-to-noise ratios (SNR) conditions. Specifically, at SNR = -10 dB, our proposed network LocSelect achieves a mean absolute error (MAE) of 3.55 and an accuracy (ACC) of 87.40%.
A Nonlinear Method for time series forecasting using VMD-GARCH-LSTM model
Oct 13, 2023



Time series forecasting represents a significant and challenging task across various fields. Recently, methods based on mode decomposition have dominated the forecasting of complex time series because of the advantages of capturing local characteristics and extracting intrinsic modes from data. Unfortunately, most models fail to capture the implied volatilities that contain significant information. To enhance the forecasting of current, rapidly evolving, and volatile time series, we propose a novel decomposition-ensemble paradigm, the VMD-LSTM-GARCH model. The Variational Mode Decomposition algorithm is employed to decompose the time series into K sub-modes. Subsequently, the GARCH model extracts the volatility information from these sub-modes, which serve as the input for the LSTM. The numerical and volatility information of each sub-mode is utilized to train a Long Short-Term Memory network. This network predicts the sub-mode, and then we aggregate the predictions from all sub-modes to produce the output. By integrating econometric and artificial intelligence methods, and taking into account both the numerical and volatility information of the time series, our proposed model demonstrates superior performance in time series forecasting, as evidenced by the significant decrease in MSE, RMSE, and MAPE in our comparative experimental results.
On the Equivalence of Graph Convolution and Mixup
Sep 29, 2023



This paper investigates the relationship between graph convolution and Mixup techniques. Graph convolution in a graph neural network involves aggregating features from neighboring samples to learn representative features for a specific node or sample. On the other hand, Mixup is a data augmentation technique that generates new examples by averaging features and one-hot labels from multiple samples. One commonality between these techniques is their utilization of information from multiple samples to derive feature representation. This study aims to explore whether a connection exists between these two approaches. Our investigation reveals that, under two mild conditions, graph convolution can be viewed as a specialized form of Mixup that is applied during both the training and testing phases. The two conditions are: 1) \textit{Homophily Relabel} - assigning the target node's label to all its neighbors, and 2) \textit{Test-Time Mixup} - Mixup the feature during the test time. We establish this equivalence mathematically by demonstrating that graph convolution networks (GCN) and simplified graph convolution (SGC) can be expressed as a form of Mixup. We also empirically verify the equivalence by training an MLP using the two conditions to achieve comparable performance.
Learning to Assist Different Wearers in Multitasks: Efficient and Individualized Human-In-the-Loop Adaption Framework for Exoskeleton Robots
Sep 26, 2023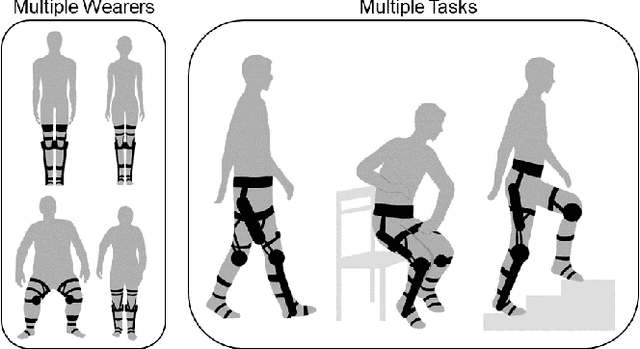
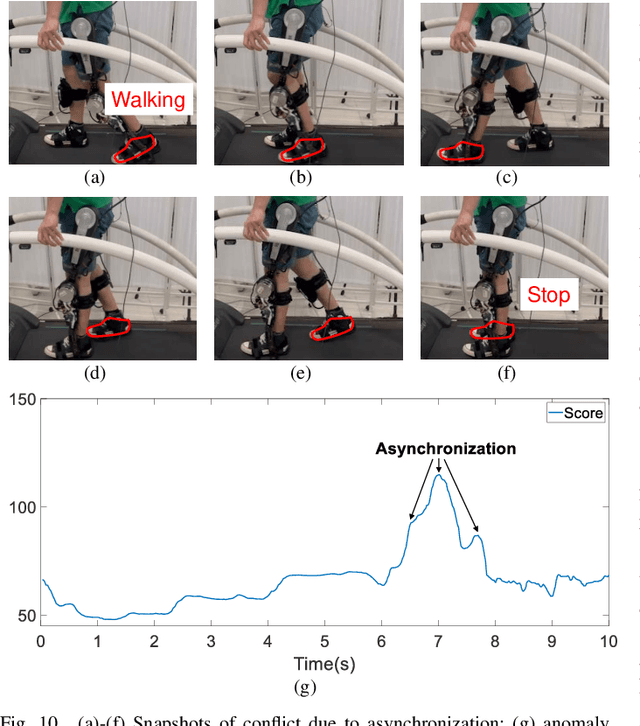
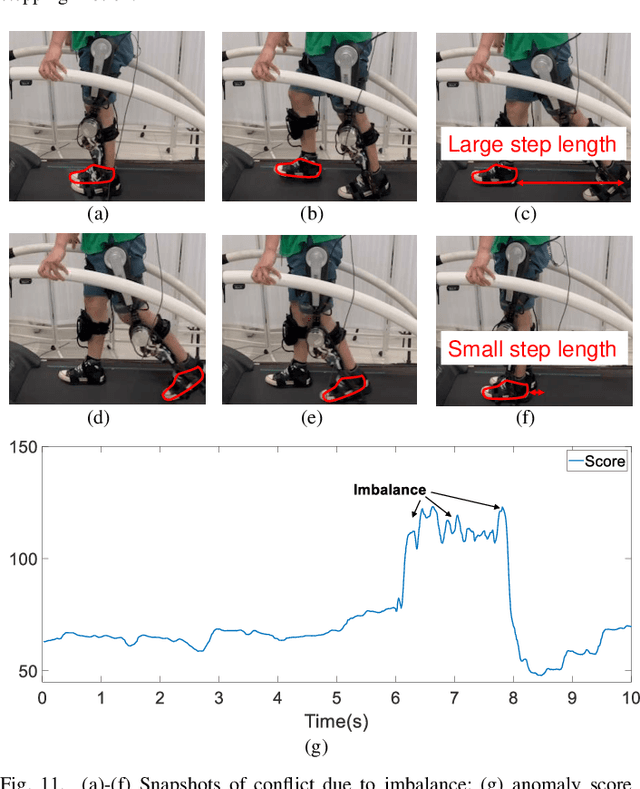
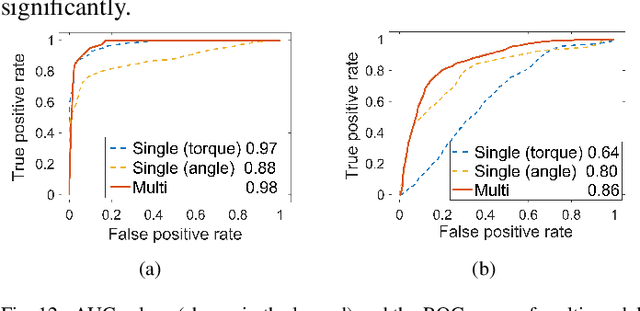
One of the typical purposes of using lower-limb exoskeleton robots is to provide assistance to the wearer by supporting their weight and augmenting their physical capabilities according to a given task and human motion intentions. The generalizability of robots across different wearers in multiple tasks is important to ensure that the robot can provide correct and effective assistance in actual implementation. However, most lower-limb exoskeleton robots exhibit only limited generalizability. Therefore, this paper proposes a human-in-the-loop learning and adaptation framework for exoskeleton robots to improve their performance in various tasks and for different wearers. To suit different wearers, an individualized walking trajectory is generated online using dynamic movement primitives and Bayes optimization. To accommodate various tasks, a task translator is constructed using a neural network to generalize a trajectory to more complex scenarios. These generalization techniques are integrated into a unified variable impedance model, which regulates the exoskeleton to provide assistance while ensuring safety. In addition, an anomaly detection network is developed to quantitatively evaluate the wearer's comfort, which is considered in the trajectory learning procedure and contributes to the relaxation of conflicts in impedance control. The proposed framework is easy to implement, because it requires proprioceptive sensors only to perform and deploy data-efficient learning schemes. This makes the exoskeleton practical for deployment in complex scenarios, accommodating different walking patterns, habits, tasks, and conflicts. Experiments and comparative studies on a lower-limb exoskeleton robot are performed to demonstrate the effectiveness of the proposed framework.
Safe and Individualized Motion Planning for Upper-limb Exoskeleton Robots Using Human Demonstration and Interactive Learning
Sep 15, 2023



A typical application of upper-limb exoskeleton robots is deployment in rehabilitation training, helping patients to regain manipulative abilities. However, as the patient is not always capable of following the robot, safety issues may arise during the training. Due to the bias in different patients, an individualized scheme is also important to ensure that the robot suits the specific conditions (e.g., movement habits) of a patient, hence guaranteeing effectiveness. To fulfill this requirement, this paper proposes a new motion planning scheme for upper-limb exoskeleton robots, which drives the robot to provide customized, safe, and individualized assistance using both human demonstration and interactive learning. Specifically, the robot first learns from a group of healthy subjects to generate a reference motion trajectory via probabilistic movement primitives (ProMP). It then learns from the patient during the training process to further shape the trajectory inside a moving safe region. The interactive data is fed back into the ProMP iteratively to enhance the individualized features for as long as the training process continues. The robot tracks the individualized trajectory under a variable impedance model to realize the assistance. Finally, the experimental results are presented in this paper to validate the proposed control scheme.
LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models
Sep 07, 2023In recent years, there have been remarkable advancements in the performance of Transformer-based Large Language Models (LLMs) across various domains. As these LLMs are deployed for increasingly complex tasks, they often face the need to conduct longer reasoning processes or understand larger contexts. In these situations, the length generalization failure of LLMs on long sequences becomes more prominent. Most pre-training schemes truncate training sequences to a fixed length. LLMs often struggle to generate fluent and coherent texts, let alone carry out downstream tasks, after longer contexts, even with relative positional encoding designed to cope with this problem. Common solutions such as finetuning on longer corpora often involve daunting hardware and time costs and require careful training process design. To more efficiently leverage the generation capacity of existing LLMs, we theoretically and empirically investigate the main out-of-distribution (OOD) factors contributing to this problem. Inspired by this diagnosis, we propose a simple yet effective solution for on-the-fly length generalization, LM-Infinite. It involves only a $\Lambda$-shaped attention mask (to avoid excessive attended tokens) and a distance limit (to avoid unseen distances) while requiring no parameter updates or learning. We find it applicable to a variety of LLMs using relative-position encoding methods. LM-Infinite is computationally efficient with $O(n)$ time and space, and demonstrates consistent text generation fluency and quality to as long as 32k tokens on ArXiv and OpenWebText2 datasets, with 2.72x decoding speedup. On downstream tasks such as passkey retrieval, it continues to work on inputs much longer than training lengths where vanilla models fail immediately.
Hide and Seek : A Lightweight Framework for Prompt Privacy Protection
Sep 06, 2023Numerous companies have started offering services based on large language models (LLM), such as ChatGPT, which inevitably raises privacy concerns as users' prompts are exposed to the model provider. Previous research on secure reasoning using multi-party computation (MPC) has proven to be impractical for LLM applications due to its time-consuming and communication-intensive nature. While lightweight anonymization techniques can protect private information in prompts through substitution or masking, they fail to recover sensitive data replaced in the LLM-generated results. In this paper, we expand the application scenarios of anonymization techniques by training a small local model to de-anonymize the LLM's returned results with minimal computational overhead. We introduce the HaS framework, where "H(ide)" and "S(eek)" represent its two core processes: hiding private entities for anonymization and seeking private entities for de-anonymization, respectively. To quantitatively assess HaS's privacy protection performance, we propose both black-box and white-box adversarial models. Furthermore, we conduct experiments to evaluate HaS's usability in translation and classification tasks. The experimental findings demonstrate that the HaS framework achieves an optimal balance between privacy protection and utility.
Rotation-Invariant Completion Network
Aug 23, 2023Real-world point clouds usually suffer from incompleteness and display different poses. While current point cloud completion methods excel in reproducing complete point clouds with consistent poses as seen in the training set, their performance tends to be unsatisfactory when handling point clouds with diverse poses. We propose a network named Rotation-Invariant Completion Network (RICNet), which consists of two parts: a Dual Pipeline Completion Network (DPCNet) and an enhancing module. Firstly, DPCNet generates a coarse complete point cloud. The feature extraction module of DPCNet can extract consistent features, no matter if the input point cloud has undergone rotation or translation. Subsequently, the enhancing module refines the fine-grained details of the final generated point cloud. RICNet achieves better rotation invariance in feature extraction and incorporates structural relationships in man-made objects. To assess the performance of RICNet and existing methods on point clouds with various poses, we applied random transformations to the point clouds in the MVP dataset and conducted experiments on them. Our experiments demonstrate that RICNet exhibits superior completion performance compared to existing methods.
DReg-NeRF: Deep Registration for Neural Radiance Fields
Aug 18, 2023Although Neural Radiance Fields (NeRF) is popular in the computer vision community recently, registering multiple NeRFs has yet to gain much attention. Unlike the existing work, NeRF2NeRF, which is based on traditional optimization methods and needs human annotated keypoints, we propose DReg-NeRF to solve the NeRF registration problem on object-centric scenes without human intervention. After training NeRF models, our DReg-NeRF first extracts features from the occupancy grid in NeRF. Subsequently, our DReg-NeRF utilizes a transformer architecture with self-attention and cross-attention layers to learn the relations between pairwise NeRF blocks. In contrast to state-of-the-art (SOTA) point cloud registration methods, the decoupled correspondences are supervised by surface fields without any ground truth overlapping labels. We construct a novel view synthesis dataset with 1,700+ 3D objects obtained from Objaverse to train our network. When evaluated on the test set, our proposed method beats the SOTA point cloud registration methods by a large margin, with a mean $\text{RPE}=9.67^{\circ}$ and a mean $\text{RTE}=0.038$. Our code is available at https://github.com/AIBluefisher/DReg-NeRF.