 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Recognition with Augmented Synthesized Speech
Sep 25, 2019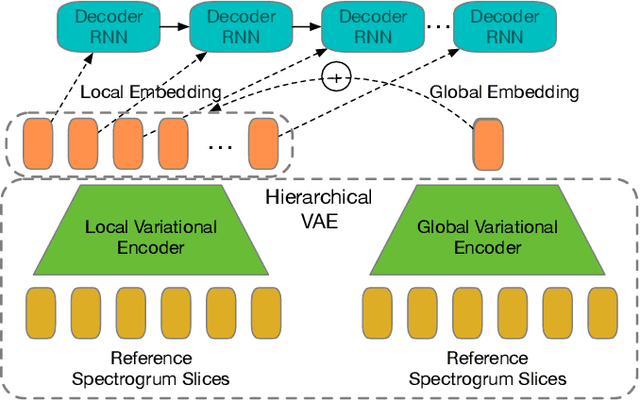
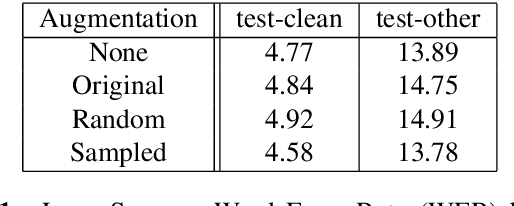
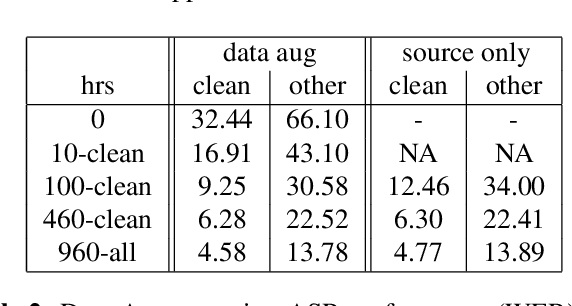
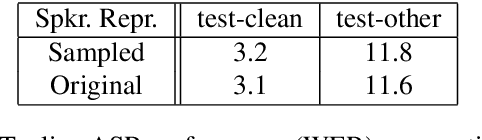
Recent success of the Tacotron speech synthesis architecture and its variants in producing natural sounding multi-speaker synthesized speech has raised the exciting possibility of replacing expensive, manually transcribed, domain-specific, human speech that is used to train speech recognizers. The multi-speaker speech synthesis architecture can learn latent embedding spaces of prosody, speaker and style variations derived from input acoustic representations thereby allowing for manipulation of the synthesized speech. In this paper, we evaluate the feasibility of enhancing speech recognition performance using speech synthesis using two corpora from different domains. We explore algorithms to provide the necessary acoustic and lexical diversity needed for robust speech recognition. Finally, we demonstrate the feasibility of this approach as a data augmentation strategy for domain-transfer. We find that improvements to speech recognition performance is achievable by augmenting training data with synthesized material. However, there remains a substantial gap in performance between recognizers trained on human speech those trained on synthesized speech.
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Sep 11, 2019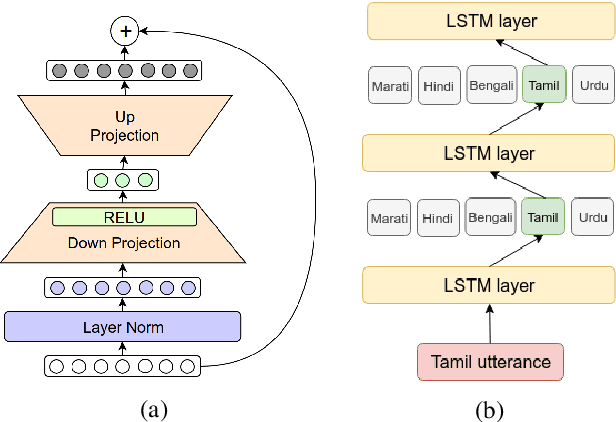
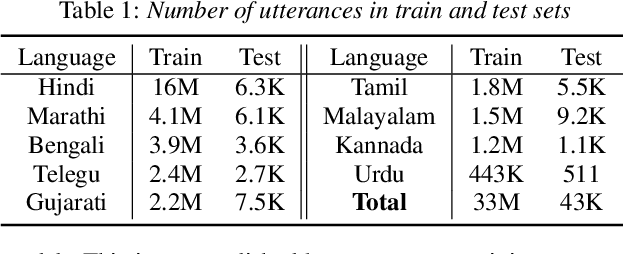
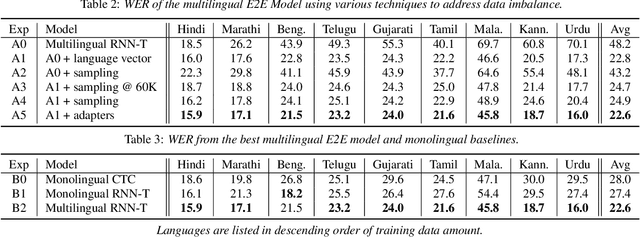
Multilingual end-to-end (E2E) models have shown great promise in expansion of automatic speech recognition (ASR) coverage of the world's languages. They have shown improvement over monolingual systems, and have simplified training and serving by eliminating language-specific acoustic, pronunciation, and language models. This work presents an E2E multilingual system which is equipped to operate in low-latency interactive applications, as well as handle a key challenge of real world data: the imbalance in training data across languages. Using nine Indic languages, we compare a variety of techniques, and find that a combination of conditioning on a language vector and training language-specific adapter layers produces the best model. The resulting E2E multilingual model achieves a lower word error rate (WER) than both monolingual E2E models (eight of nine languages) and monolingual conventional systems (all nine languages).
Two-Pass End-to-End Speech Recognition
Aug 29, 2019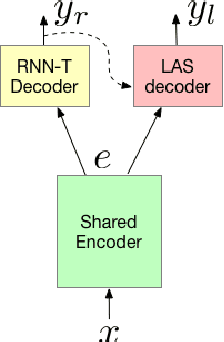

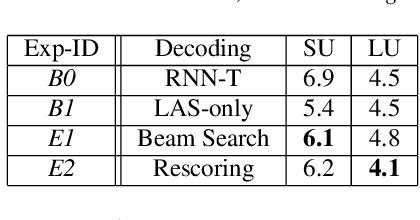
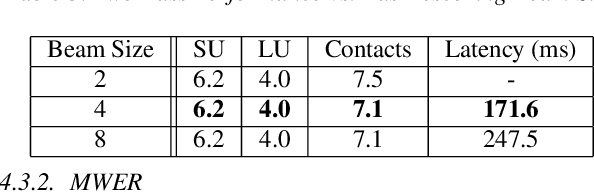
The requirements for many applications of state-of-the-art speech recognition systems include not only low word error rate (WER) but also low latency. Specifically, for many use-cases, the system must be able to decode utterances in a streaming fashion and faster than real-time. Recently, a streaming recurrent neural network transducer (RNN-T) end-to-end (E2E) model has shown to be a good candidate for on-device speech recognition, with improved WER and latency metrics compared to conventional on-device models [1]. However, this model still lags behind a large state-of-the-art conventional model in quality [2]. On the other hand, a non-streaming E2E Listen, Attend and Spell (LAS) model has shown comparable quality to large conventional models [3]. This work aims to bring the quality of an E2E streaming model closer to that of a conventional system by incorporating a LAS network as a second-pass component, while still abiding by latency constraints. Our proposed two-pass model achieves a 17%-22% relative reduction in WER compared to RNN-T alone and increases latency by a small fraction over RNN-T.
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 24, 2019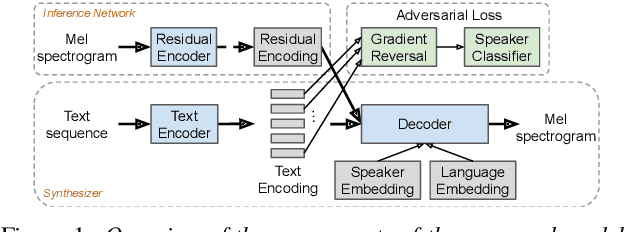
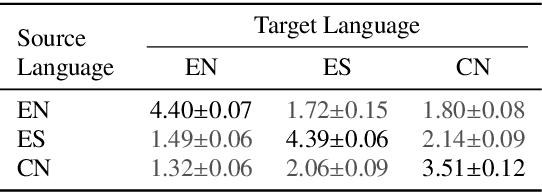
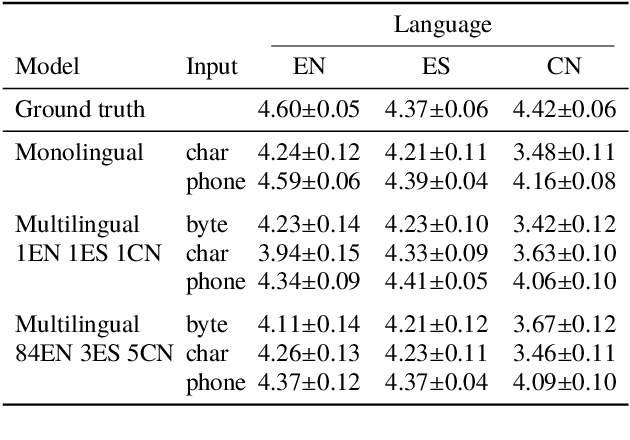
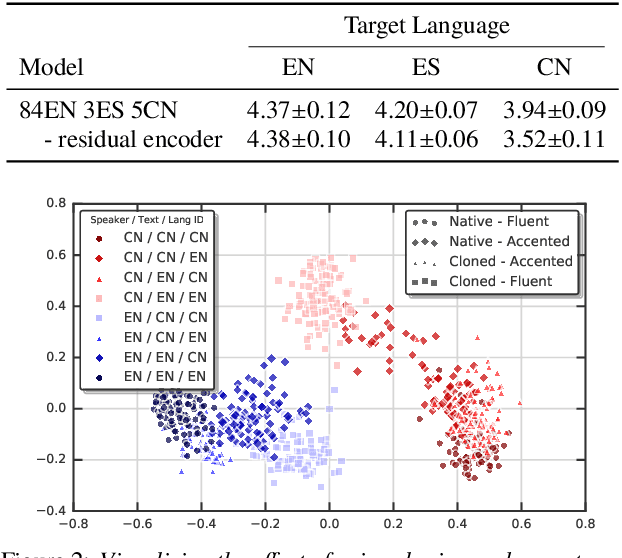
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Jul 11, 2019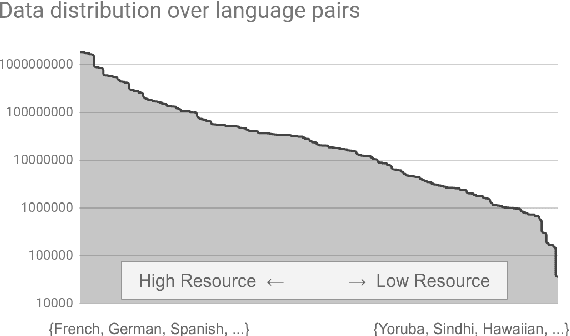
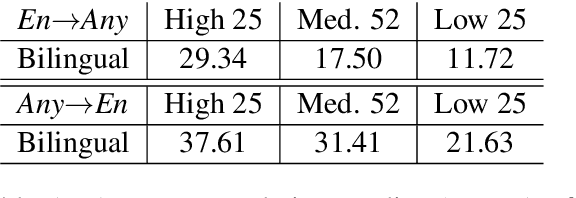
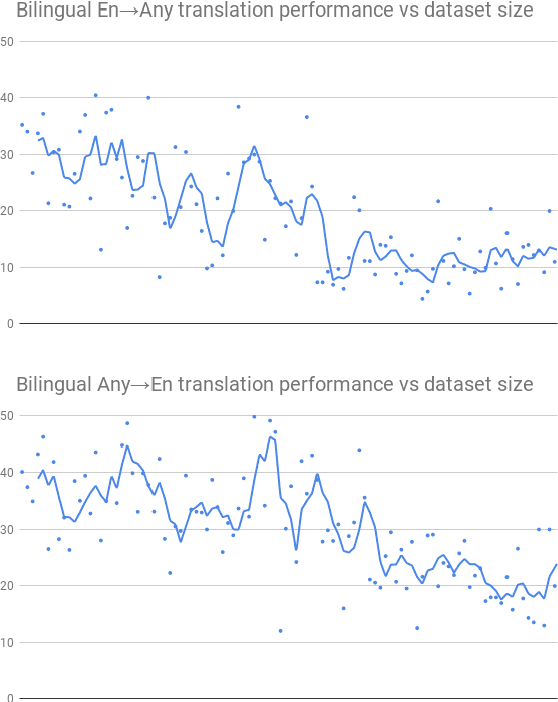
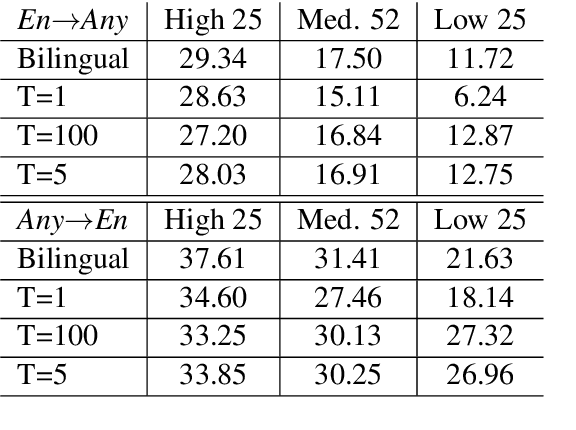
We introduce our efforts towards building a universal neural machine translation (NMT) system capable of translating between any language pair. We set a milestone towards this goal by building a single massively multilingual NMT model handling 103 languages trained on over 25 billion examples. Our system demonstrates effective transfer learning ability, significantly improving translation quality of low-resource languages, while keeping high-resource language translation quality on-par with competitive bilingual baselines. We provide in-depth analysis of various aspects of model building that are crucial to achieving quality and practicality in universal NMT. While we prototype a high-quality universal translation system, our extensive empirical analysis exposes issues that need to be further addressed, and we suggest directions for future research.
Gmail Smart Compose: Real-Time Assisted Writing
May 17, 2019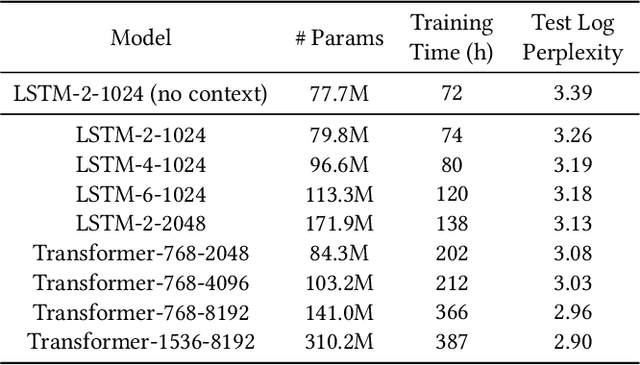
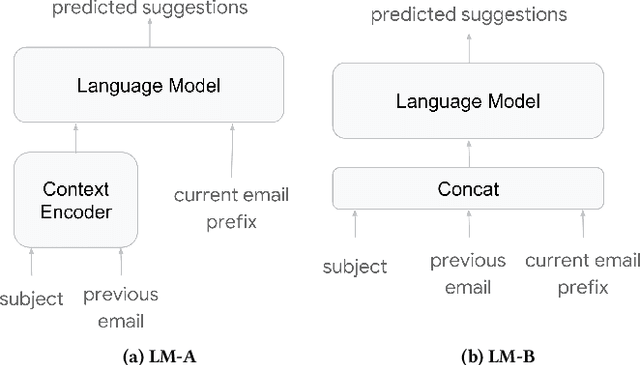
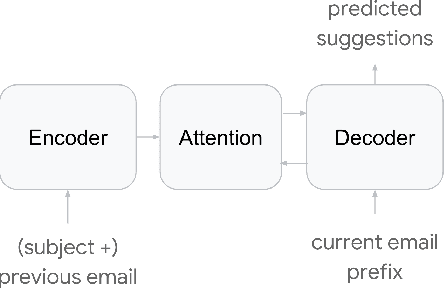
In this paper, we present Smart Compose, a novel system for generating interactive, real-time suggestions in Gmail that assists users in writing mails by reducing repetitive typing. In the design and deployment of such a large-scale and complicated system, we faced several challenges including model selection, performance evaluation, serving and other practical issues. At the core of Smart Compose is a large-scale neural language model. We leveraged state-of-the-art machine learning techniques for language model training which enabled high-quality suggestion prediction, and constructed novel serving infrastructure for high-throughput and real-time inference. Experimental results show the effectiveness of our proposed system design and deployment approach. This system is currently being served in Gmail.
Direct speech-to-speech translation with a sequence-to-sequence model
Apr 12, 2019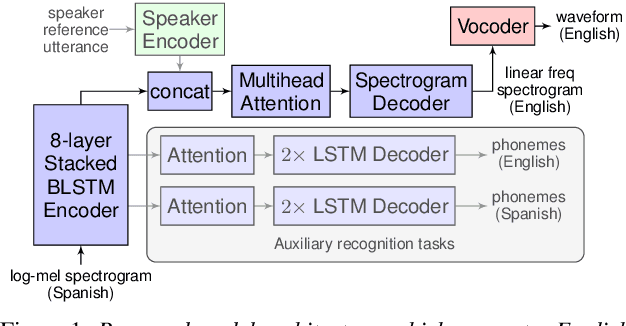
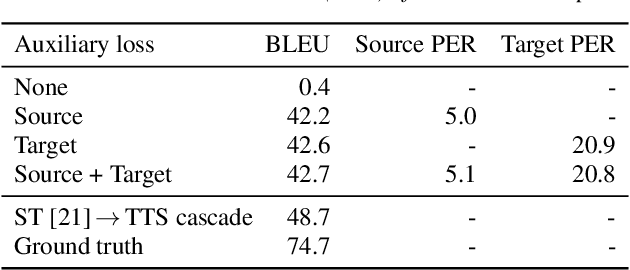
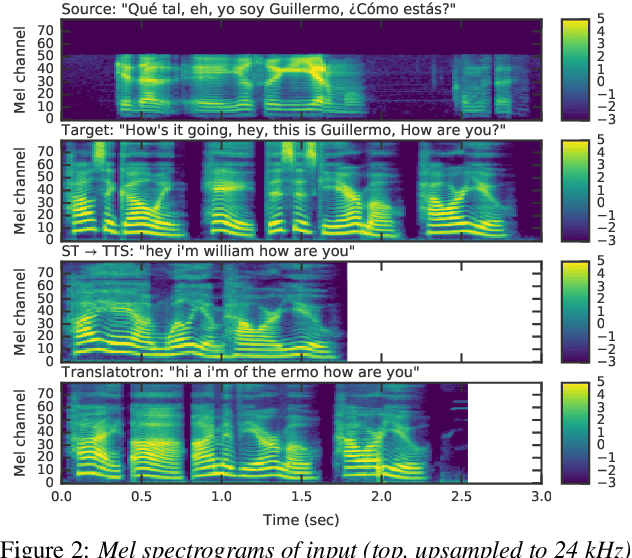
We present an attention-based sequence-to-sequence neural network which can directly translate speech from one language into speech in another language, without relying on an intermediate text representation. The network is trained end-to-end, learning to map speech spectrograms into target spectrograms in another language, corresponding to the translated content (in a different canonical voice). We further demonstrate the ability to synthesize translated speech using the voice of the source speaker. We conduct experiments on two Spanish-to-English speech translation datasets, and find that the proposed model slightly underperforms a baseline cascade of a direct speech-to-text translation model and a text-to-speech synthesis model, demonstrating the feasibility of the approach on this very challenging task.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Bytes are All You Need: End-to-End Multilingual Speech Recognition and Synthesis with Bytes
Nov 22, 2018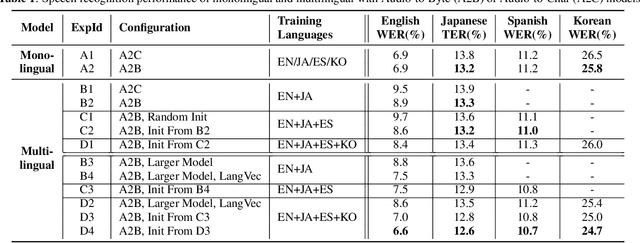
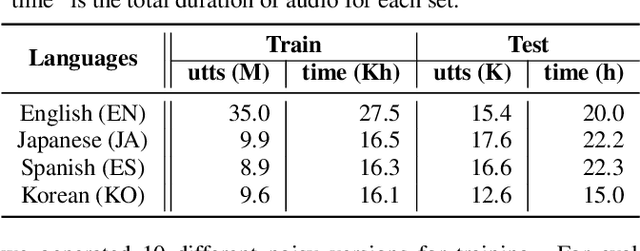

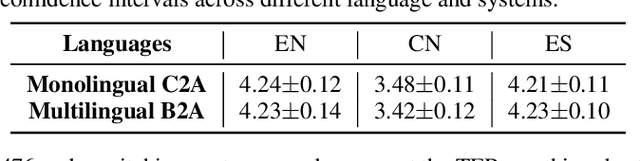
We present two end-to-end models: Audio-to-Byte (A2B) and Byte-to-Audio (B2A), for multilingual speech recognition and synthesis. Prior work has predominantly used characters, sub-words or words as the unit of choice to model text. These units are difficult to scale to languages with large vocabularies, particularly in the case of multilingual processing. In this work, we model text via a sequence of Unicode bytes, specifically, the UTF-8 variable length byte sequence for each character. Bytes allow us to avoid large softmaxes in languages with large vocabularies, and share representations in multilingual models. We show that bytes are superior to grapheme characters over a wide variety of languages in monolingual end-to-end speech recognition. Additionally, our multilingual byte model outperform each respective single language baseline on average by 4.4% relatively. In Japanese-English code-switching speech, our multilingual byte model outperform our monolingual baseline by 38.6% relatively. Finally, we present an end-to-end multilingual speech synthesis model using byte representations which matches the performance of our monolingual baselines.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018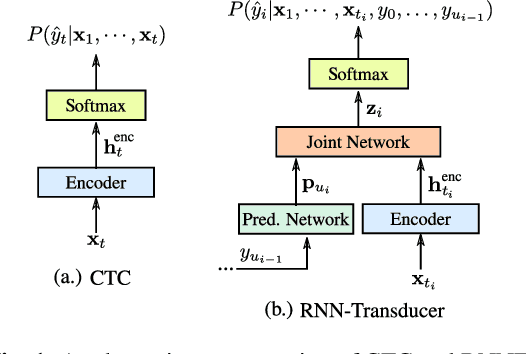
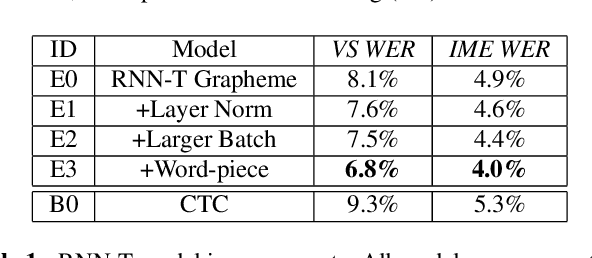
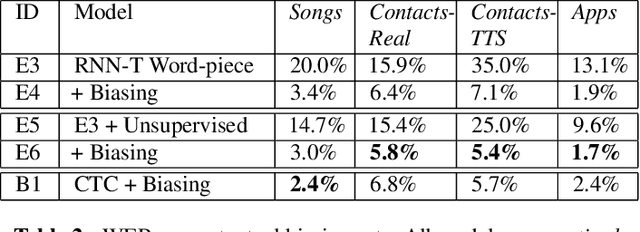
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.